Exploiting commutativity for practical fast replication Park & Ousterhout, NSDI’19
I’m really impressed with this work. The authors give us a practical-to-implement enhancement to replication schemes (e.g., as used in primary-backup systems) that offers a signification performance boost. I’m expecting to see this picked up and rolled-out in real-world systems as word spreads. At a high level, CURP works by dividing execution into periods of commutative operation where ordering does not matter, punctuated by full syncs whenever commutativity would break.
The Consistent Unordered Replication Protocol (CURP) allows clients to replicate requests that have not yet been ordered, as long as they are commutative. This strategy allows most operations to complete in 1 RTT (the same as an unreplicated system).
When integrated with RAMCloud write latency was improved by ~2x, and write throughput by 4x. Which is impressive given that RAMCloud isn’t exactly hanging around in the first place! When integrated with Redis, CURP was able to add durability and consistency while keeping similar performance to non-durable Redis.
CURP can be easily applied to most existing systems using primary-backup replication. Changes required by CURP are not intrusive, and it works with any kind of backup mechanism (e.g., state-machine replication, file writes to network replicated drives, or scattered replication). This is important since most high-performance systems optimize their backup mechanisms, and we don’t want to lose those optimizations…
The big idea: durability, ordering, and commutativity
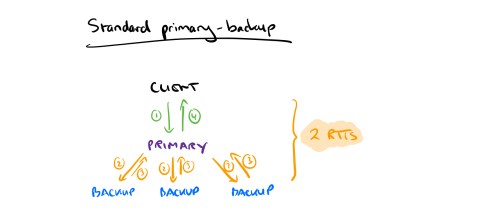
We’re looking for two things from a replication protocol: durability of executed operations, and consistent ordering across all replicas for linearizability. Hence the classic primary-backup protocol in which clients send requests to a primary, which by being a single instance serves to give a global order to requests. The primary then ensures that the update is propagated to backup replicas before returning to the client. This all takes 2 RTTs. Consensus protocols with strong leaders also require 2 RTTs. Fast Paxos and Generalized Paxos reduce latency to 1.5 RTT through optimistic replication with presumed ordering. Network-Ordered Paxos and Speculative Paxos can get close to 1 RTT latency, but require special networking hardware.
CURP’s big idea is as follows: when operations are commutative, ordering doesn’t matter. So the only property we have to ensure during a commutative window is durability. If the client sends a request in parallel to the primary and to f additional servers which all make the request durable, then the primary can reply immediately and once the client has received all f confirmations it can reveal the result. This gives us a 1 RTT latency for operations that commute, and we fall back to the regular 2 RTT sync mechanism when an operation does not commute.
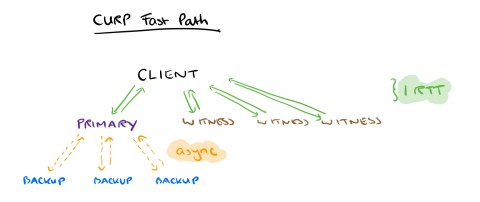
Those f additional servers are called witnesses. If you’re building a new system from scratch, it makes a lot of sense to combine the roles of backup and witness in a single process. But this is not a requirement, and for ease of integration with an existing system witnesses can be separate.
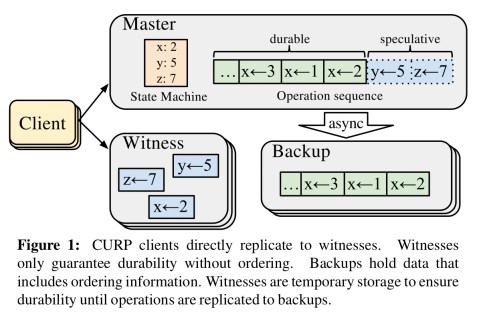
… witnesses do not carry ordering information, so clients can directly record operations into witnesses in parallel with sending operations to masters so that all requests will finish in 1 RTT. In addition to the unordered replication to witnesses, masters still replicate ordered data to backups, but do so asynchronously after sending the execution results back to the clients.
This should all be raising a number of questions, chief among which is what should happen when a client, witness, or primary crashes. We’ll get to that shortly. The other obvious question is how do we know when operations commute?
Witnesses must be able to determine whether operations are commutative or not just from the operation parameters. For example, in key-value stores, witnesses can exploit the fact that operations on different keys are commutative… Witnesses cannot be used for operations whose commutativity depends on the system state.
So CURP works well with key-value stores, but not with SQL-based stores (in which WHERE clauses for example mean that operation outcomes can depend on system state).
The CURP protocol
CURP uses a total of f+1 replicas to tolerate f failures (as per standard primary-backup), and additionally uses f witnesses to ensure durability of updates even before replications to backups are completed. Witnesses may fail independently of backups.
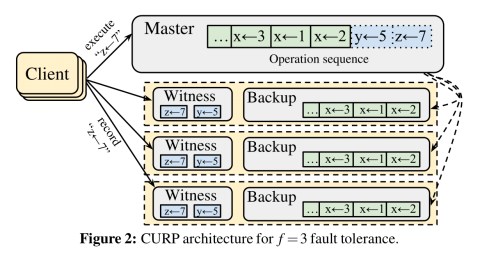
To ensure the durability of the speculatively completed updates, clients multicast update operations to witnesses. To preserve linearizability, witnesses and masters enforce commutativity among operations that are not fully replicated to backups.
Operation in the absence of failures
Clients send update requests to the primary, and concurrently to the f witnesses allocated to the primary. Once the client has responses from all f witnesses (indicating durability) and the primary (which responds immediately without waiting for data to replicate to backups) then it can return the result. This is the 1 RTT path.
If the client sends an operation to a witness, and instead of confirming acceptance the witness rejects that operation (because it does not commute with the other operations currently being held by the witness), then the client cannot complete in 1 RTT. It now sends a sync request to the primary and awaits the response (indicating data is safely replicated and the operation result can be returned). Thus the operation latency in this case in 2 RTTs in the best case, and up to 3 RTTs in the worst case depending on the status of replication between primary and backups at the point the sync request was received.
Witnesses durably record operations requested by clients. Non-volatile memory (e.g. flash-backed DRAM) is a good choice for this as the amount of space required is relatively small. On receiving a client request, the witness saves the operation and sends an accept response if it commutes with all other saved operations. Otherwise it rejects the request. All witnesses operate independently. Witnesses may also receive garbage collection RPCs from their primary, indicating the RPC IDs of operations that are now durable (safely replicated by the primary to all backups). The witnesses can then delete these operations from their stores.
A primary receives, serializes, and executes all update RPC requests from clients. In general a primary will respond to clients before syncing to backups (speculative execution) leading to unsynced operations. If the primary receives an operation request which does not commute with all currently unsynced operations then it must sync before responding (and adds a ‘synced’ header in the response so that the client knows an explicit sync request is unnecessary. Primaries can batch and asynchronously replicate RPC requests. E.g. with 3-way primary-backup replication and batches of 10 RPCs, we have 1.3 RPCs per request on average. The optimal batch and window size depends on the particulars of the workload.
For read requests clients can go directly to primaries (no need for the durability afforded by witnesses). The primary must sync before returning if the read request does not commute with all currently unsynced updates. Clients can also read from a backup while retaining linearizability guarantees if they also confirm with a witness that the read operation commutes with all operations currently saved in the witness.
Recovery
If a client does not get a response from a primary it resends the update RPC to a new primary, and tries to record the RPC request in the witnesses of that primary. If the client does not get a response from a witness, it can fall back to the traditional replication path by issuing a sync request to the primary.
If a witness crashes it is decommissioned and a new witness is assigned to the primary. The primary is notified of its new witness list. The primary then syncs to backups before responding that it is now safe to recover from the new witness. A witness list version number maintained by the primary and sent by the client on every request so that clients can be notified of the change and update their lists.
If a primary crashes there may have been unsynced operations for which clients have received results but the data is not yet replicated to backups. A new primary is allocated, and bootstrapped by recovering from one of the backups. The primary then picks any available witness, asks it to stop accepting more operations, and then retrieves all requests known to the witness. The new primary can execute these requests in any order since they are known to be commutative. With the operations executed, the primary syncs to backups and resets all the witnesses. It can now begin accepting requests again.
The gotcha in this scheme is that some of the requests sent by the witness may in fact have already been executed and replicated to backups before the primary crashed. We don’t want to re-execute such operations:
Duplicate executions of the requests can violate linearizability. To avoid duplicate executions of the requests that are already replicated to backups, CURP relies on exactly-once semantics provided by RIFL, which detects already executed client requests and avoids their re-execution.
(We studied RIFL in an earlier edition of The Morning Paper, RIFL promises efficient ‘bolt-on’ linearizability for distributed RPC systems).
Performance evaluation
We evaluated CURP by implementing it in the RAMCloud and Redis storage systems, which have very different backup mechanisms. First, using the RAMCloud implementation, we show that CUP improves the performance of consistently replicated systems. Second, with the Redis implementation we demonstrate that CURP can make strong consistency affordable in a system where it had previously been too expensive for practical use.
I’m out of space to do the evaluation justice, but you’ll find full details in §5. Here are a couple of highlights…
The chart below shows the performance of Redis without durability (i.e., as most people use it today), with full durability in the original Redis scheme, and with durability via CURP. You can clearly see that using CURP we get the benefits of consistency and durability with performance much closer to in-memory only Redis.
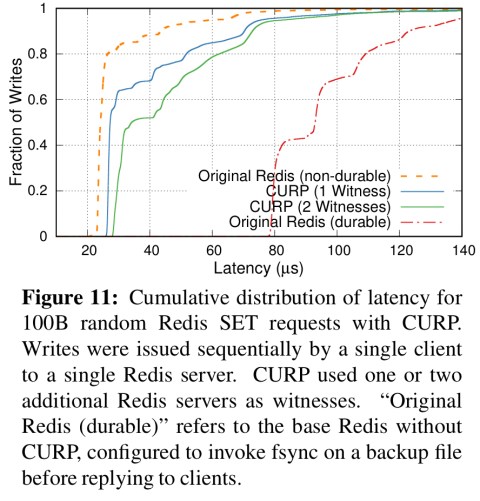
And here’s the change in latency of write operations for RAMCloud. It took me a moment to understand what we’re seeing here, since it looks like the system gets slower as the write percentage goes down. But remember that we’re only measuring write latency here, not average request latency. Presumably with more reads we need to sync more often.
Thanks to Qian Li who points out in the comments I’d completely missed the crucial ‘cumulative’ word in the description of this chart. Now it all makes so much more sense! Only a tiny fraction of writes have higher latency, and CURP is **improving** tail latencies.
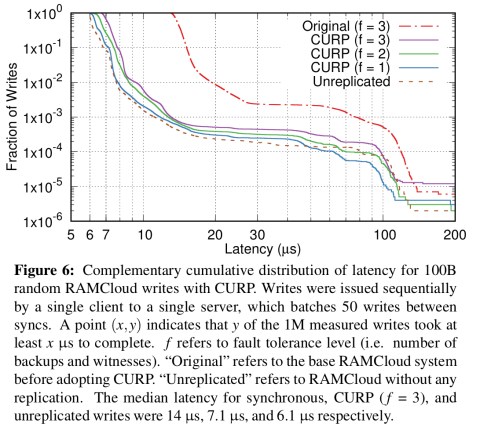
In the RAMCloud implementation, witnesses could handle 1270K requests per second on a single thread, with interwoven gc requests at 1 in every 50 writes from the primary. The memory overhead is just 9MB. CURP does however increase network bandwidth usage for update operations by 75%.

I think you might have misunderstood the last figure ;) The last figure (i.e. Figure 6 in the paper) is an inverse CDF plot (described in the caption below that as well), where point (x, y) means y portion of requests have latency larger than x usec. The inverse CDF can help readers to see the tail latencies: y = 0.1 means 90% tail, and y = 0.01 means 99% tail, etc.
From my understanding, this figure shows that CURP can enable better tail latencies compared with original RAMCloud.
Thank you!! I totally missed the “cumulative” in the description, and it makes *so* much more sense as soon as you pointed that out. I’ll add a clarification to the post…
Having the client write to f witnesses and master seems like a lot of work on the client library.
I must have missed the Kool Aid on the way into the meeting! :)
– While there is no universal definition of RTT, it’s a bit disingenuous to consider concurrent RTT units to two different subsystems as “1 RTT”. At worst it confuses an optimistic extension of the design (the so-called “fast path” here) with the core design, which is *not* 1 RTT.
– Incorporating system logic into the client makes it part of the system. It is no longer “just” a client, in fact, it is now sharing coordinator duties with the primary. We can see this from the fact that it now must be trusted (e.g. “exchanging witness version numbers” with the primary and bi-directional ‘sync/synced’ operations). (Side note: Through this lens, CURP is precisely 2 RTT at best, because the “client” operations must be separated from the “co-coordinator” operations, and that little jump is itself an RTT).
– It’s trivial to make uncontested, replicated writes to something when you control the ordering. It’s called holding and enforcing a write lock. This entire protocol distills to nothing more than source ordering and speculative write locks, with the witnesses acting effectively as a lock service to shortcut coordination between the potentially concurrent writers. Let’s take a hypothetical DB we will call “LockedDB”. If you reduce the operations to:
– LockedDB always enforces locks atomically. Locks are single use and monotonically ordered.
– in parallel, optimistically attempt operation with all LockedDB replicas and acquire lock from lock service
– on the slow path:
– client’s will inform all LockedDB replicas “later” if a lock couldn’t be acquired by sending a ‘sync’ message. Replicas fall back to normal linearized operation if they are unaware of this lock (e.g. the second operation arrived before the first one due to some network condition).
– replicas will inform the client if a lock already exists for the operation by adding a ‘synced’ header in its response. Replicas fall back to normal linearized operation for outstanding contested writes outside the critical path.
– on the fast path:
– replicas create a speculative local lock for the client.
– replicas simply acknowledge the operation once they have local durability and release the speculative lock.
– clients are strictly responsible for ensuring that *all* replicas perform all writes
…we’ve just essentially replicated CURP. (I’m not going to attempt to go through all the recovery modes in a reply :) ).
– The very hand-wavey solution to the “witness list” failure detection / synchronization / split brain problem is conveniently convenient. It would have been cleaner to separate out membership crisply so that churn and simultaneous subsystem failure conditions could be treated properly, but this is just a nitpick.
I can easily see the use of locks enabling better performance in networked critical sections…people have been using them that way for decades :).
The approach reminds me of virtual synchrony.