Cloud programming simplified: a Berkeley view on serverless computing Jonas et al., arXiv 2019
With thanks to Eoin Brazil who first pointed this paper out to me via Twitter….
Ten years ago Berkeley released the ‘Berkeley view of cloud computing’ paper, predicting that cloud use would accelerate. Today’s paper choice is billed as its logical successor: it predicts that the use of serverless computing will accelerate. More precisely:
… we predict that serverless computing will grow to dominate the future of cloud computing.
The acknowledgements thank reviewers from Google, Amazon, and Microsoft among others, so it’s reasonable to assume the major cloud providers have had at least some input to the views presented here. The discussion is quite high level, and at points it has the feel of a PR piece for Berkeley (there’s even a cute collective author email address: serverlessview at berkeley.edu), but there’s enough of interest in its 35 pages for us to get our teeth into…
The basic structure is as follows. First we get the obligatory attempt at defining serverless, together a discussion of why it matters. Then the authors look at some of the current limitations (cf. ‘Serverless computing: one step forward, two steps back’) before going on to suggest areas for improvement in the coming years. The paper closes with a nice section on common fallacies (and pitfalls) of serverless, together with a set of predictions. I’m going to start there!
Predictions, fallacies, pitfalls
Fallacy: cloud function instances cost up to 7.5x more per minute than regular VM instances of similar capacity, therefore serverless cloud computing is more expensive than serverful cloud computing.
Rebuttal: the equivalent functionality that you’re getting from a function is much more than you can achieve with a single VM instance. Plus, you don’t pay when there are no events. Putting the two together means that serverless could well end up being less expensive.
Prediction (for me, the most interesting sentence in the whole paper!) :
We see no fundamental reason why the cost of serverless computing should be higher than that of serverful computing, so we predict that billing models will evolve so that almost any application, running at almost any scale, will cost no more and perhaps much less with serverless computing.
But yes, billing by actual usage means that costs will be less predictable (hopefully in a good way!) than ‘always-on’ solutions.
Fallacy: it’s easy to port applications between serverless computing providers since functions are written in high-level languages. (Does anyone really think that serverless increases portability? All the talk I hear is of the opposite concern!).
Rebuttal/Pitfall: vendor lock-in may be stronger with serverless computing than for serverful computing. (Yes, because of the reliance on the eventing model and the set of back-end services your functions bind too).
Prediction: “We expect new BaaS storage services to be created that expand the types of applications that run well on serverless computing,” and, “The future of serverless computing will be to facilitate BaaS.”
Pitfall: (today) “few so called ‘elastic’ services match the real flexibility demands of serverless computing.”
Fallacy: cloud functions cannot handle very low latency applications needing predictable performance
Rebuttal: if you pre-warm / keep a pool of functions ready then they can (combine this thought with ‘we see no fundamental reason why the cost of serverless computing should be higher than that of serverful computing…’)
Prediction:
While serverful cloud computing won’t disappear, the relative importance of that portion of the cloud will decline as serverless computing overcomes its current limitations. Serverless computing will become the default computing paradigm of the Cloud Era, largely replacing serverful computing and thereby bringing closure to the Client-Server Era.
(So what’s the new term? Client-Function architecture?? )
Oh, and one more thing: “we expect serverless computing to become simpler to program securely than serverful computing…“
Serverless motivation
I guess it’s definition time!
Put simply, serverless computing = FaaS + BaaS. In our definition, for a service to be considered serverless, it must scale automatically with no need for explicit provisioning, and be billed based on usage. In the rest of this paper, we focus on the emergence, evolution, and future of cloud functions…
If you squint just right, you can just about make out the other important part of a serverless platform in that equation: in the ‘+’ sign connecting FaaS and BaaS is the set of platform events that can be used to glue the two together, and they’re an important part of the overall model in my mind.
One of the key things that serverless gives is a transfer of responsibility from the user to the cloud provider for many operational concerns:
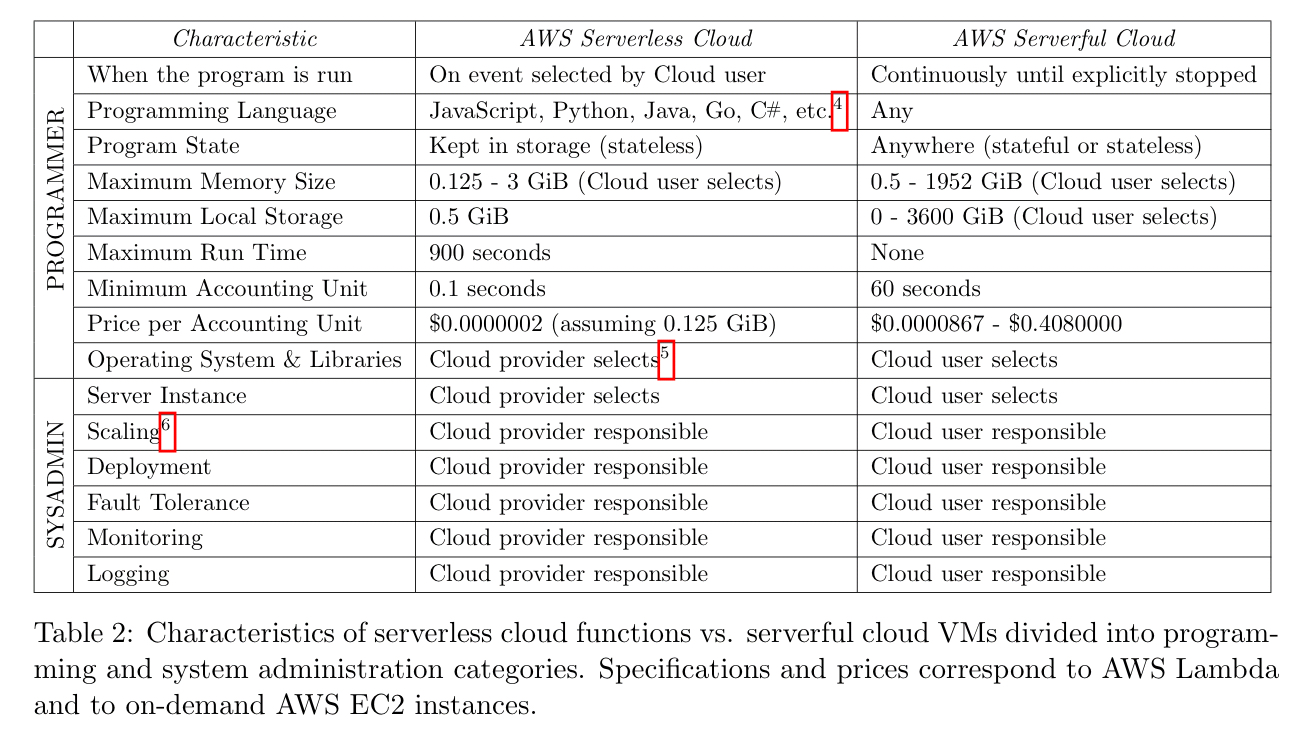
The authors list three critical distinctions between serverless and serverful computing:
- Decoupled computation and storage: storage and computation scale separately and are provisioned and priced independently. (Hang on, don’t I get that with EBS in ‘serverful’ mode??)
- Executing code without managing resource allocation.
- Paying in proportion to resources used instead of for resources allocated.
The fundamental differentiator between serverless computing and the previous generations of PaaS is the autoscaling and associated billing model:
- tracking load with much greater fidelity than serverful autoscaling techniques,
- scaling all the way down to zero, and
- charging in much more fine-grained manner for time the code spends executing, not the resources reserved to execute the program.
But then there’s also this claim that I can’t make any sense of: “by allowing users to bring their own libraries, serverless computing can support a much broader range of applications than PaaS services which are tied closely to particular use cases.” I’m pretty sure that any library / package I can reference from a function I could also reference from my Node.js / Java / Ruby / Python /… app!
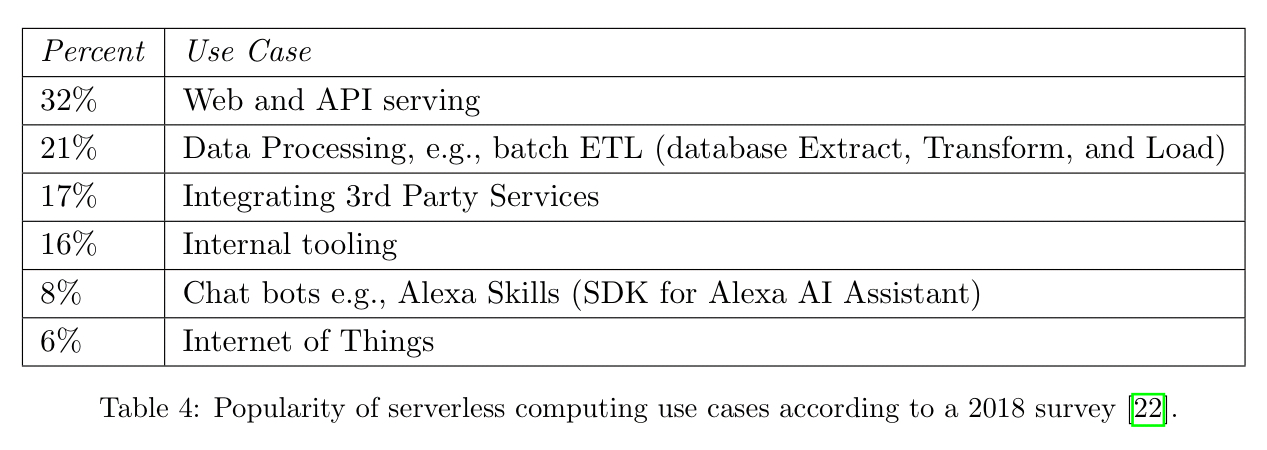
The most popular uses of serverless today, according to a 2018 survey are as follows:
Current limitations
Section 3 of the paper examines a set of five applications to understand the current strengths and weaknesses. These are summarised in the table below. It should not surprise you in the least that implementing a database using functions-as-a-service turns out to be a bad idea!!
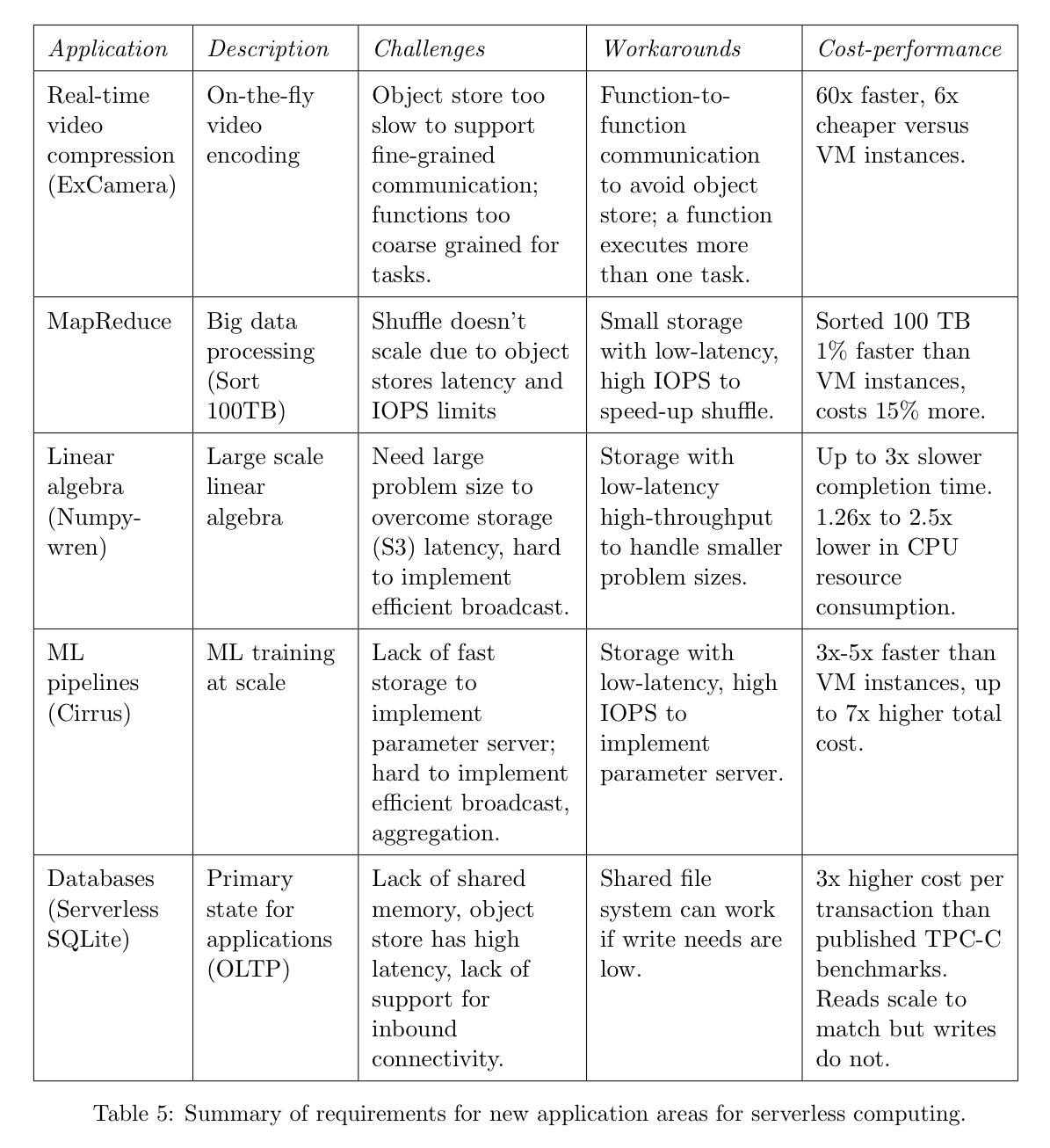
One thing that several of these workloads have in common is resource requirements that can vary significantly during their execution, hence it is attractive to try and take advantage of the fine-grained autoscaling serverless offers.
Four main current limitations emerge from this exercise:
- Inadequate storage support for fine-grained operations
- A lack of fine-grained coordination mechanisms (the latency is too high in the standard eventing mechanisms)
- Poor performance for standard communication patterns (which can be
or
depending on the use case, but ‘N’ typically goes up a lot as we have many more functions than we did VMs).
- Cold-start latency leading to unpredictable performance
Suggestions for the future
The first suggestion (§4.1) concerns the support of serverless functions with particular resource requirements (e.g. access to accelerators).
One approach would be to enable developers to specify these resource requirements explicitly. However, this would make it harder for cloud providers to achieve high utilization through statistical multiplexing, as it puts more constraints on function scheduling… A better alternative would be to raise the level of abstraction, having the cloud provider infer resource requirements instead of having the developer specify them.
So scenario A the developer (for example) explicitly specifies via metadata that the function needs a GPU, and scenario B the platform infers through inspection that the function needs a GPU. It’s not clear to me how that makes any difference to the scheduling constraints! Although with clever inference maybe we can get closer to the true resource requirements, whereas we know developers tend to over-provision when making explicit requests. We’d have to take the level of abstraction right up to something close to SLOs for things to get really interesting though, and even then there would need to be multiple viable strategies for the cloud platform to select between in order to meet those targets. This topic is also touched on in section $4.5 where we find the following, “alternatively, the cloud provider could monitor the performance of the cloud functions and migrate them to the most appropriate hardware the next time they are run. “
The second suggestion is to expose function communication patterns (computation graphs) to the platform, so that this information can inform placement. AWS Step Functions is a step in this direction ;).
Section 4.2 discusses the need for more storage options. In particular, serverless ephemeral storage used for coordination between functions (e.g., an in-memory data grid), and serverless durable storage, which here means access to a low-latency persistent shared key-value store. A related ask is for a low-latency eventing / signaling service for function coordination.
It feels worth bringing up again here that instead of trying to replicate old application development patterns in a future cloud platform, a serverless approach using something like Bloom and its underlying CALM philosophy would give much of what we’re looking for here: a higher level abstraction with a naturally exposed computation graph and ability for the platform to make informed scheduling and autoscaling decisions.
Startup times can be minimised through the investigation of new lighter-weight isolation mechanisms, using unikernels, and lazy loading of libraries.
Section 4.4 discusses security challenges: fine-grained provisioning of access to private keys, delegation of privileges across functions, and information leakage through network communication patterns (which are more revealing with a larger number of fine-grained components).

I don’t really understand why they think that functions can be made cheaper than reserved demand. In every other industry, we see premium pricing for “spot demand” and a discount for repeated subscription “smooth demand”. Why? Because if I have ten customers with predictable demand I can run lean workout overcapacity and invest to bring efficiencies. If I have ten customers who can all surge simultaneously, or all leave me at once, I have to have higher capacity available to be able to meet peak demand and not lose customers. That means that I need to have overcapacity that is mostly idle. I also cannot treat the income on a semi-permanent and invest.
Many large organisations will have some workload that is reasonably consistent and some workloads that are lower usage and that might surge. This means that a mixed model may be beneficial; lock into a long contract for core capacity and pay for any surge at spot price. Perhaps that’s the future; move to functions but buy a “discount package” much like a cell phone contract where you have to pay an amount every month for a year at a discounted rate regardless of actual use. That will seem of benefit to both parties of the supply and demand.
I was working at an organisation that spent over ten million dollars a year on one of the big three public cloud providers. A group of developers were getting very excited about using functions. I asked them about costs. They were oblivious. I showed them the huge discounts we got for reserved instances due to the large amount of money that we spent on public cloud. I think that they go the message that while the price model of functions is perfect for early phase startups and small businesses (particularly as it can surge if they take off) a spot price model is totally inappropriate for medium to large enterprises. Until the laws of economics fundamentally change that won’t change regardless of hyperbole about exciting new technologies.
Really interesting points. Reserving to some watermark to take advantage of lower pricing (and predictability from the cloud provider side) and then exploiting fully dynamic pricing in the margin above that seems a likely destination here. When you think about what people are doing to keep latency-sensitive functions warm (a whole other discussion!) then you’ve kind of got your ‘reserved’ bucket right there as a starting point…
I predict that we will see the big 3 grow their lead in serverless as and when 5G services become deployed. The big 3 will partner will carriers so they can co-locate serverless resources at key nodes. Then the big 3 can optimise traffic to and from storage.
This will go a long way to mitigating “Cold-start latency leading to unpredictable performance”
I predict that we will revisit caching mechanisms over 5G networks and long haul fibre. Provider-side caching will then carry a lot of the load in addressing some items:
* Inadequate storage support for fine-grained operations
* A lack of fine-grained coordination mechanisms (the latency is too high in the standard eventing mechanisms)
Clearly it will depend on the price-point of 5G network services, and what part of the spec operators will offer.
Hello,
Regarding placement optimizations via communication patterns as well as lighter-weight isolation mechanisms for FaaS, you might want to also check out a paper recently published in USENIX ATC in 2018: “SAND: Towards High-Performance Serverless Computing”.
Disclaimer: I am the lead author of that paper.
A very informative read and covers all important points that one needs to check ahead of opting a cloud solution.