Cloudburst: stateful functions-as-a-service, Sreekanti et al., arXiv 2020
Today’s paper choice is a fresh-from-the-arXivs take on serverless computing from the RISELab at Berkeley, addressing some of the limitations outlined in last year’s ‘Berkeley view on serverless computing.’ Stateless is fine until you need state, at which point the coarse-grained solutions offered by current platforms limit the kinds of application designs that work well. Last week we looked at a function shipping solution to the problem; Cloudburst uses the more common data shipping to bring data to caches next to function runtimes (though you could also make a case that the scheduling algorithm placing function execution in locations where the data is cached a flavour of function-shipping too).
Given the simplicity and economic appeal of FaaS, it is interesting to explore designs that preserve the autoscaling and operational benefits of current offerings, while adding performant, cost-efficient and consistent shared state and communication.
The key ingredients of Cloudburst are a highly-scalable key-value store for persistent state (Anna), local caches co-located with function execution environments, and cache-consistency protocols to preserve developer sanity while data is moved in and out of those caches. Oh, and there’s a scheduler too of course to keep all the plates spinning.
On the Cloudburst design teams’ wish list:
- A running function’s ‘hot’ data should be kept physically nearby for low-latency access
- Updates should be allowed at any function invocation site
- Cross-function communication should work at wire speed
Logical disaggregation with physical colocation
The canononical cloud platform architecture decouples storage and compute services so that each can be scaled and operated independently, i.e., they are disaggregated. Cloudburst advocates a design point the authors call "logical disaggregation with physical colocation" (LDPC for short). It’s disaggregated in the sense that storage and compute can be provisioned and billed independently, but physically colocated in the sense that hot data can be cached locally next to the function runtimes that access it.
It’s a fancy sounding name, but it’s essentially the same design as we’ve been using in enterprise applications for decades now: think application server with an L2 ORM cache sat in front of a relational database. Only now the database is itself a distributed KVS, and the slices of application functionality are much finer-grained.
A low-latency autoscaling KVS can serve as both global storage and a DHT-like overlay network. To provide better data locality to functions, a KVS cache can be deployed on every machine that hosts function inocations. Cloudburst’s design includes consistent mutable caches in the compute tier
Programming model
Cloudburst programs are written in Python. Function arguments can either be regular Python objects or KVS references. Such references are transparently retrieved and deserialized at runtime. Functions can be composed into DAGs, with results automatically passed from one DAG function to the next by the Cloudburst runtime. The Cloudburst API comprises simple get/put/delete operations over the KVS, and send and recv operations to send messages between function executors.

High level architecture
Cloudburst has four key components: function executors, caches, function schedulers, and a resource management system. These are underpinned by Anna, a highly scalable KVS also out of the RiseLab, that supports a variety of coordination-free consistency models using lattice composition.
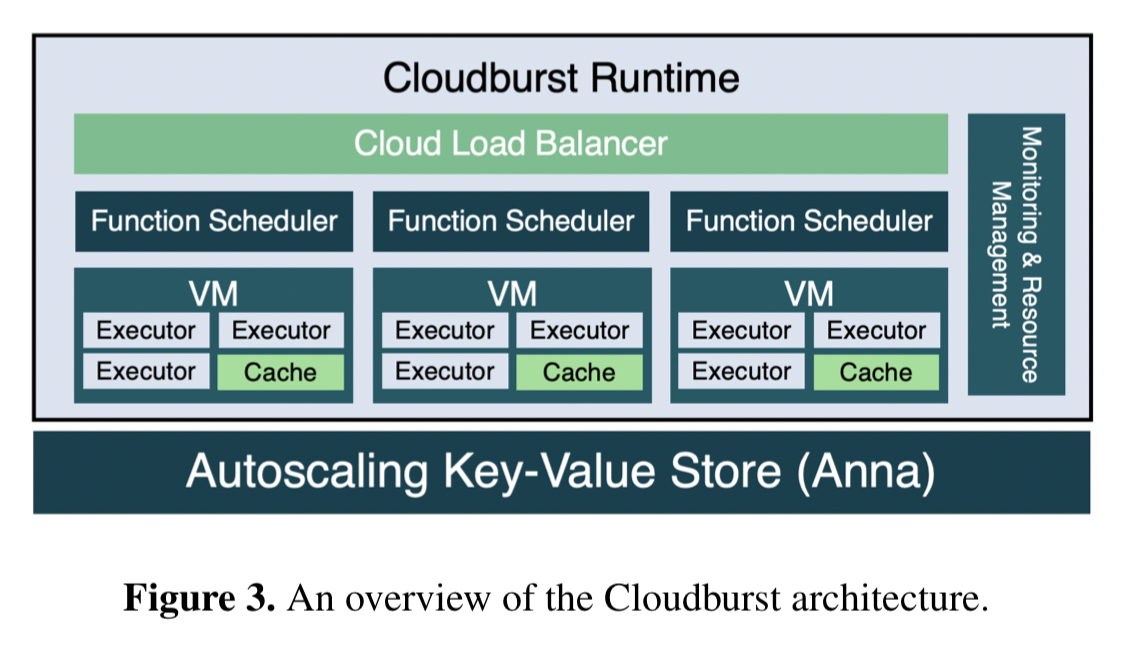
Function executors are just long-lived Python processes that can retrieve and execute serialized functions, transparently resolving any persistent state (KVS) reference arguments. A function execution VM hosts multiple function executors, and also a local cache process which executors interact with via IPC. Executors only ever interact with the cache, which provides read-through and write-behind access to Anna. To avoid stale data in caches, Anna sends periodic updates to nodes based on cached information it has about the keys stored at that node.
We’re only given very high level details about the operation of this part of the system, a few open questions that come to my mind:
- Caches asynchronously send updates to the KVS to be merged after acknowledging the request from the executor. Do caches themselves use some kind of persistent logging, or is there a window of opportunity for data loss here?
- Why do caches have to publish their cached keys to Anna? Doesn’t Anna already know which clients have requested which keys?
- What happens when there is stale data in a cache? Does the cache sit in-front of, or behind the bolt-on causal consistency layer that Cloudburst uses?
All requests to register or invoke functions or DAGS are handled by schedulers. Registered functions are serialized and stored in Anna, as are DAG topologies.
We prioritize data locality when scheduling both single functions and DAGs. If the invocation’s arguments have KVS references, the scheduler inspects its local cached key index and attempts to pick the executor with the most data cached locally. Otherwise the scheduler picks an executor at random. Hot data and functions get replicated across many executor nodes via backpressure.
Cloudburst monitors request and service rates (storing metrics in Anna). When incoming request rates exceed service rates, the monitoring engine increases the resources allocated to the function by first pinning the function to more executors, and then adding nodes to the system if CPU utilisation exceeds a threshold.
Consistency
As a foundation, Anna supports consistency for individual clients. Execution of a DAG may span multiple nodes though, and to support this Cloudburst adds a distribution session consistency protocol on top. Anna’s guarantees also only apply to values conforming to its lattice-based type system (supporting an order-insenstive, idempotent merge operation). In order to deal with arbitrary Python values, Cloudburst wraps opaque program state in lattice types. It would be interesting to see how Cloudburst would work with MRDTs.
Cloudburst doesn’t support isolation (it allows dirty reads), but it can support repeatable reads and causal consistency (and several other consistency models as supported by Anna). Cloudburst’s causal consistency session guarantees span multiple keys and multiple physical sites.
For repeatable read, Cloudbust creates snaphots of each locally cached object on first read, and these are then stored for the lifetime of a DAG execution. Cache addresses and versions are propogated downstream through the DAG along with function results. Python program state is wrapped in a last writer wins lattice (essentially a value, timestamp pair).
For distributed session causal consistency Cloudburst wraps Python program state in a causal lattice. Here we find the answer to my question about the relationship between the causal consistency protocol and the cache too – it’s neither before or after (both of which seemed offer difficulties), but integrated!
We also augment the Cloudburst cache to be a causally consistent store, implementing the bolt-on causal consistency protocol.
In additional to the read-set metadata the repeatable read propagates through the DAG, in causal consistency mode Cloudburst also ships the full set of causal dependencies for the read set.
Evaluation
The first evaluation compares function composition overheads against pure AWS Lambda, Lambda functions communicating via S3, Lambda functions communicating via DynamoDB, and AWS Step Functions, as well as the SAND serverless platform that employs a hierarchical message bus and the Dask distributed Python runtime.
Cloudburst’s function composition matches state-of-the-art Python runtime latency and outperforms commercial serverless infrastructure by 1-3 orders of magnitude.
These overheads enable distributed algorithms to be implemented, the evaluation shows that a gossip-based distributed aggregation of a floating-point metric is 3x faster than an implementation using Lambda and DynamoDB (see §6.1.3).
The overheads of various consistency models are tested over 250 randomly generated DAGs. Median latencies remain low all the way to distributed session causal consistency (the strongest model), but tail latencies do increase as the amount of coordination required goes up.
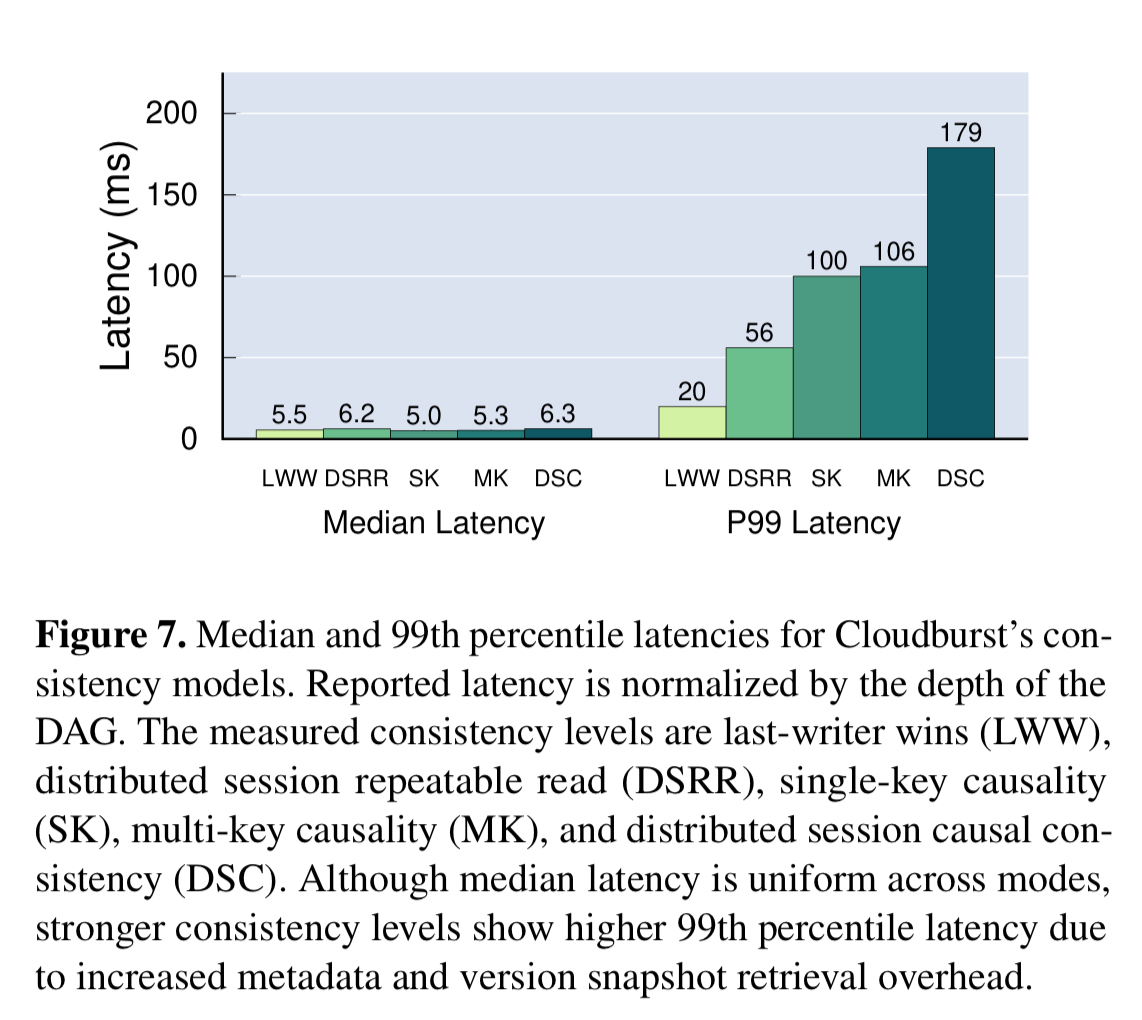
Although Cloudburst’s non-trivial consistency models increase tail latencies, median latencies are over an order of magnitude faster than DynamoDB and S3 for similar tasks, while providing stronger consistency.
The final part of the evaluation compares the performance on Cloudburst in two application scenarios: machine learning model prediction serving, and the Retwis twitter clone. Porting retwis-py was straightforward (44 lines of code changed), and the result delivered performance comparable to a servful baseline. For the model serving use case, Cloudburst delivered performance comparable to a single Python process, and outperformed AWS Sagemaker by 1.7x.
A closing thought
Cloudburst demonstrates that disaggregation and colocation are not inherently in conflict. In fact, the LPDC design pattern is key to our solution for stateful serverless computing.
The serverless story is only just beginning!

Hi Adrian — thanks for the great writeup of our paper! We wanted to respond a couple of the questions you raised about the system architecture:
“Do caches themselves use some kind of persistent logging, or is there a window of opportunity for data loss here?”
Cloudburst doesn’t have any logging: As in AWS Lambda and other FaaS systems, we assume that client retries are the source of redo recovery. As it happens, we have follow-on work under review with additional fault tolerance mechanisms that go beyond what the standard FaaS models offer, but in this paper we’re sticking with the current industry standard for FaaS fault tolerance.
“Why do caches have to publish their cached keys to Anna? Doesn’t Anna already know which clients have requested which keys?”
Anna could track which clients have requested which keys, but it would have to guess at how long each cache might keep data around. Depending on workload characteristics (e.g., data access skew, number of requests), the amount of time each key spends in-cache can vary significantly. To circumvent this problem, we simply have caches periodically publish their cached key sets (not the payloads).
“Does the cache sit in-front of, or behind the bolt-on causal consistency layer that Cloudburst uses?”
As you pointed out later in your post, the cache is the layer that implements the causal protocol. The idea is that the cache already has visibility into each program’s reads/writes, so it can easily leverage this metadata to guarantee causality. We’ve extended the guarantees (in more under-review work) provided by the caching layer to support transactional causal consistency.
Hi. In Figure 4, Cloudbusrt(cold) outperforms Lambda(Redis) so much. And my question is that if one main reason is that the RTT between the Anna and the function schedulers are much less than the one between Lambda and Redis? In the paper, I didn’t find the details indicating where the Anna was deployed for the evaluation.
Thanks a lot for your great work by the way.