The case for network-accelerated query processing Lerner et al., CIDR’19
Datastores continue to advance on a number of fronts. Some of those that come to mind are adapting to faster networks (e.g. ‘FARM: Fast Remote Memory’) and persistent memory (see e.g. ‘Let’s talk about storage and recovery methods for non-volatile memory database systems’), deeply integrating approximate query processing (e.g. ‘ApproxHadoop: Bringing approximations to MapReduce frameworks’ and ‘BlinkDB’), embedding machine learning in the core of the system (e.g. ‘SageDB’), and offloading processing into the network (e.g KV-Direct) — one particular example of exploiting hardware accelerators. Today’s paper gives us an exciting look at the untapped potential for network-accelerated query processing. We’re going to need all that data structure synthesis and cost-model based exploration coupled with self-learning to unlock the potential that arises from all of these advances in tandem!
NetAccel uses programmable network devices to offload some query patterns for MPP databases into the switch.
Thus, for the first time, moving data through networking equipment can contributed to query execution. Our preliminary results show that we can improve response times on even the best agreed upon plans by more than 2x using 25Gbps networks. We also see the promise of linear performance improvement with faster speeds. [Emphasis mine]
That promise of linear performance hints at an 8x speedup with a 100Gbps network in a data center!
Programmable switches and MAUs
Modern programmable network devices have packet-processing hardware in the form of Match-Action Units or MAUs. A MAU combines a match engine (is this a packet of interest?), with an action engine (what should I do with it?). The match engine holds data in a table format. MAUs are programmable in the sense that the table layout, type of lookup to perform, and processing done at a match event can all be specified. Combining several MAUs together in pipeline fashion yields a programmable dataplane.
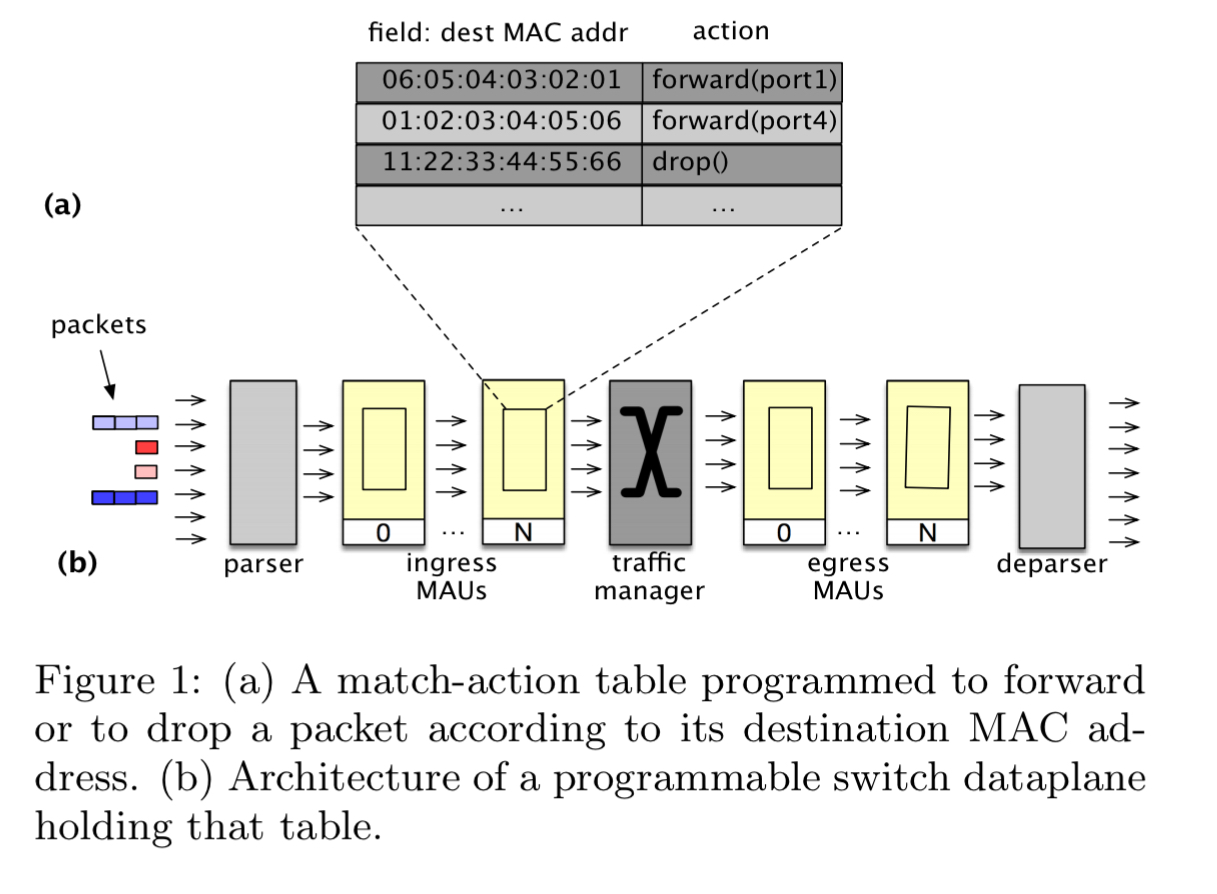
When programming MAUs we must take care to ensure progress can be made at line speed. This requires constant-time lookups and deterministic actions. For example, there are no loops or dynamic resource allocation permitted as these could make a program’s runtime non-deterministic. The P4 language can be used to program collections of MAUs, and it’s language restrictions and compiler ensure that a given program can run properly on a given target. Current hardware devices have e.g. 12-20 MAUs.
Processing in the network
Traditionally, the fastest plans in MPP databases are those with the least amount of data movement across nodes, and network switches are passive elements that just route packets. The tuples generated by query execution are an opaque payload from the perspective of the network.
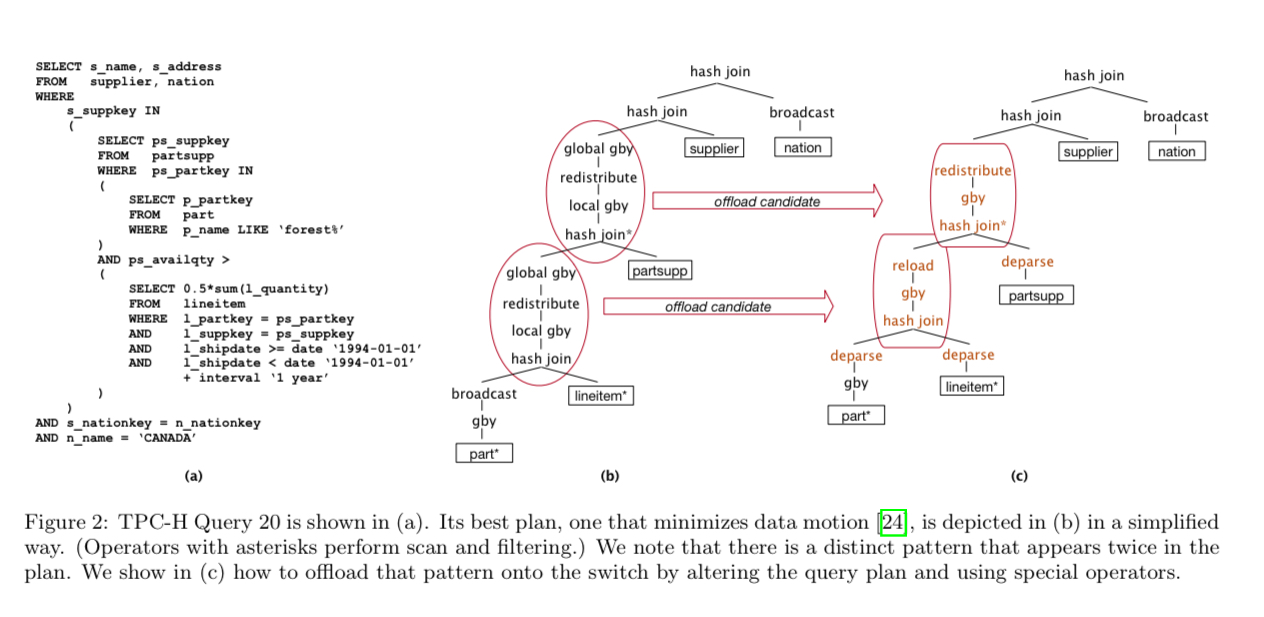
A query such as Query 20 from the TPC-H benchmark (Fig 2a), which joins five relations, has a query plan designed to minimise data motion (Fig 2b). With programmable switches though, it becomes possible to implement some parts on the query in the network. This requires an updated query plan (Fig 2c) to take advantage of the possibility.
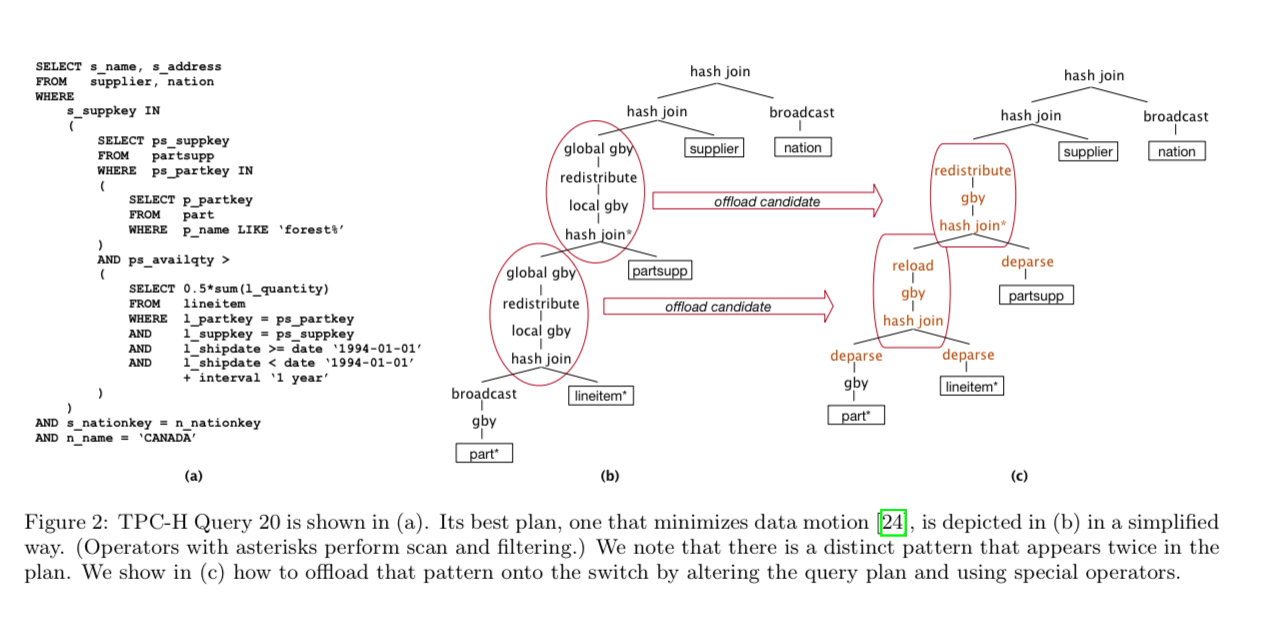
(Enlarge)
For the first time, entire segments of a query plan can be performed on the switch, with potentially strong consequences to data placement, query execution, and optimization. The tuples are processed on the switch at “line-speed” – up to 100 Gbps in our case – yielding performance improvements that increase with network speed.
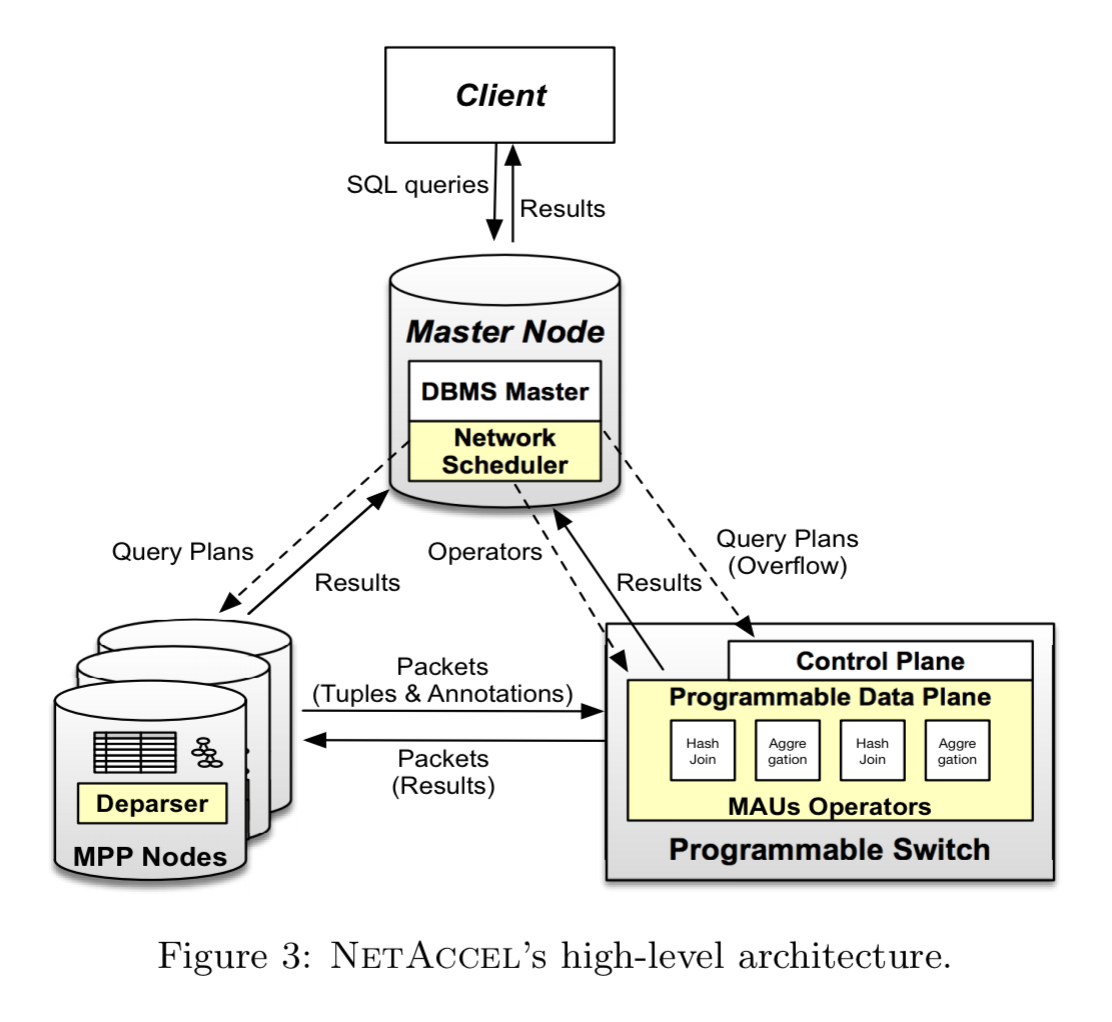
Introducing NetAccel
NetAccel is an MPP database (Greenplum) extended with three novel components:
- a set of network accelerated query operators that can be instantiated on a switch and combined to implement segments of a query
- a deparser that takes care of the communication between the MPP nodes and the switch
- a network scheduler (controller) that identifies appropriate queries, determines the placement of network-accelerated operations, and monitors their execution
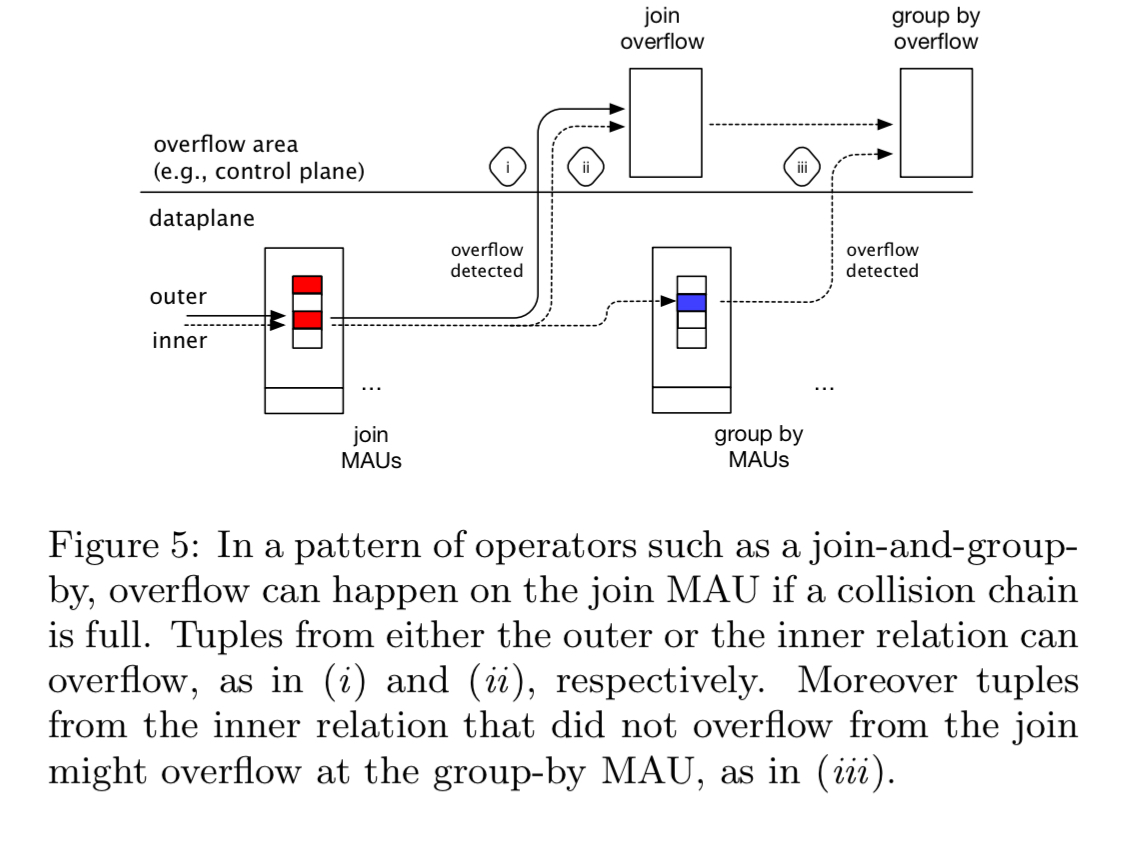
The network scheduler decides how the MAUs will be organised. One strategy is to implement fixed common query patterns, e.g. join-and-group-by. Alternatively the MAU allocation could be adaptive. In the prototype a fixed join-and-group-by pattern is used. The scheduler also puts in place a strategy to deal with overflowing tuples. That is, what should happen if the incoming data tuples do not fit in allocated data space at the MAU. One simple overflowing strategy is to overflow to the control plane, which can be reached simply by routing packets to it. Once a tuple has overflowed, any further operation on the tuple is also redirected.
The deparser manages communication between the MPP node and the switch. This includes the tuples themselves, as well as the instructions for what is to be done with them.
An important consideration here is the choice of a network protocol. For instance, simply making a tuple be the payload of a TCP packet would not work. The switch drops many packets… and moreover creates new packets dynamically… TCP being stateful making such changes to the packet flow without a receiver equating them to anomalies would be an overhead. Better network protocol stacks exist for our case. We could use a traditional IP stack and a connectionless protocol such as UDP. Or use a lightweight protocol directly atop of Ethernet. We are currently exploring the latter…
At 100 Gbps and tuples of less than 40 bytes, we may need to forward more than 148M tuples per second per port. Normal OS and TCP/IP stacks cannot operate at this pace: NetAccel bypasses both.
The fun part of course is the network-accelerated operators themselves. The authors discuss operators for hash-joins, hash-based aggregation, data motion, and data reloading.
Hash-joins require as a minimum two MAUs: one to store a hash table, and one to keep track of overflow. But we can extend capacity by using a chain of MAUs to store larger tables in each case. Each additional MAU in the chain stores an additional position in the collision chain for each location in the hash table.
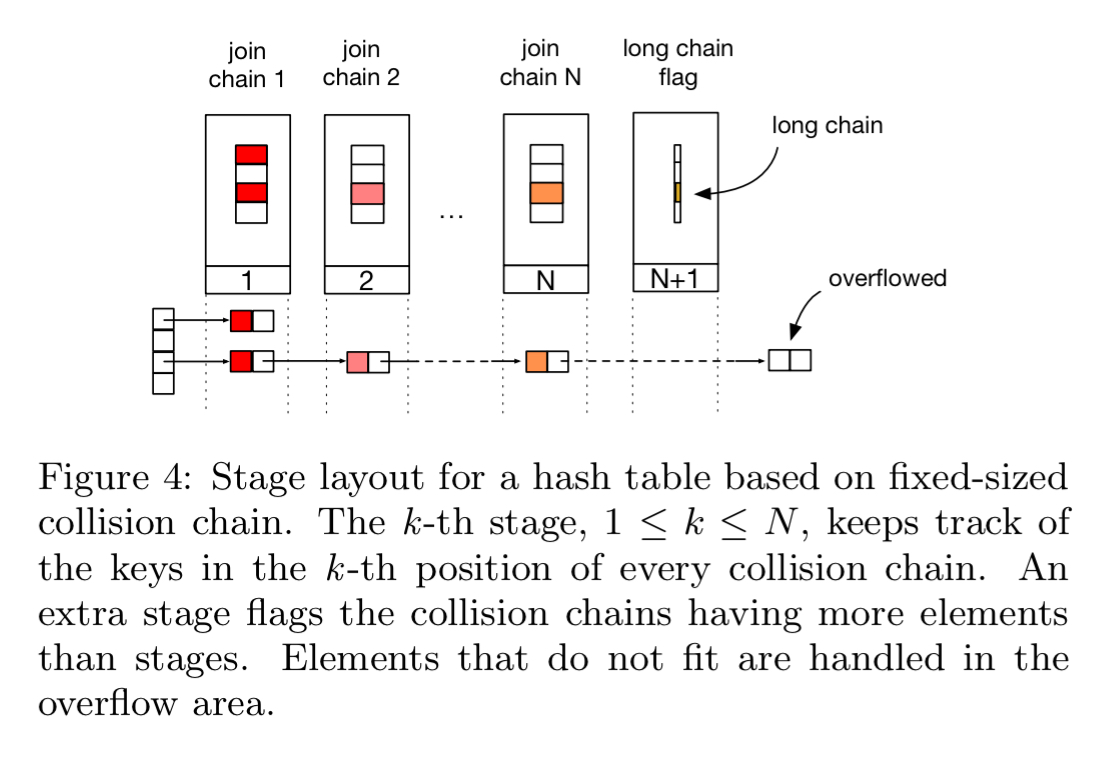
If insertion fails at all MAUs (the collision chain is full), then the packet is overflowed. Packet metadata is updated to indicate that an insertion was not possible, and we also record that the chain to which the packet hashes is full. The full algorithm looks like this:

See section 3.3 in the paper for the details of the hash-based aggregation algorithm.
Data motion operators assist in sending the results of an operation to downstream nodes, and data reloading operators are used to relocate data within the switch.
Prototype and evaluation
The prototype implements a join-and-group-by-one query pattern on the MAUs of a Tofino switch. The pattern uses 10 MAUs, as shown in the figure below.
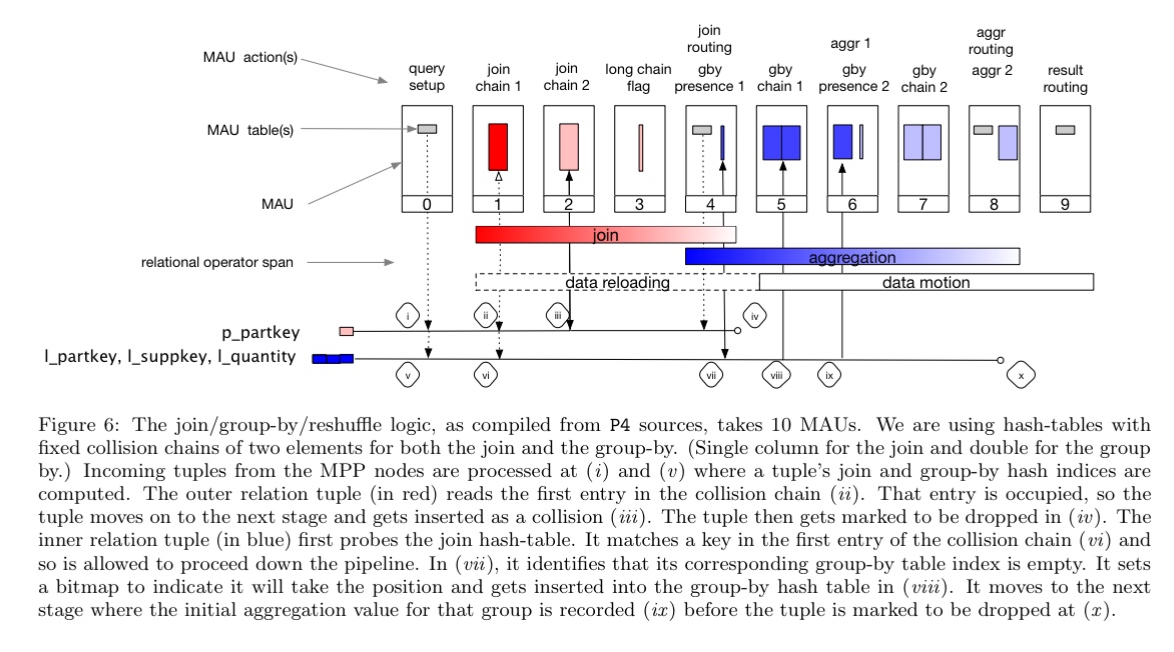
(Enlarge)
The experiments use a four-node Greenplum Parallel Database instance (three segment nodes and one control node), running Query 20 from the TPC-H benchmark with scale factor of 100.
For the most expensive join-and-group-by segment of this query, the normal Greenplum query plan completes in 1702ms, whereas the network accelerated plan completes in 834ms.
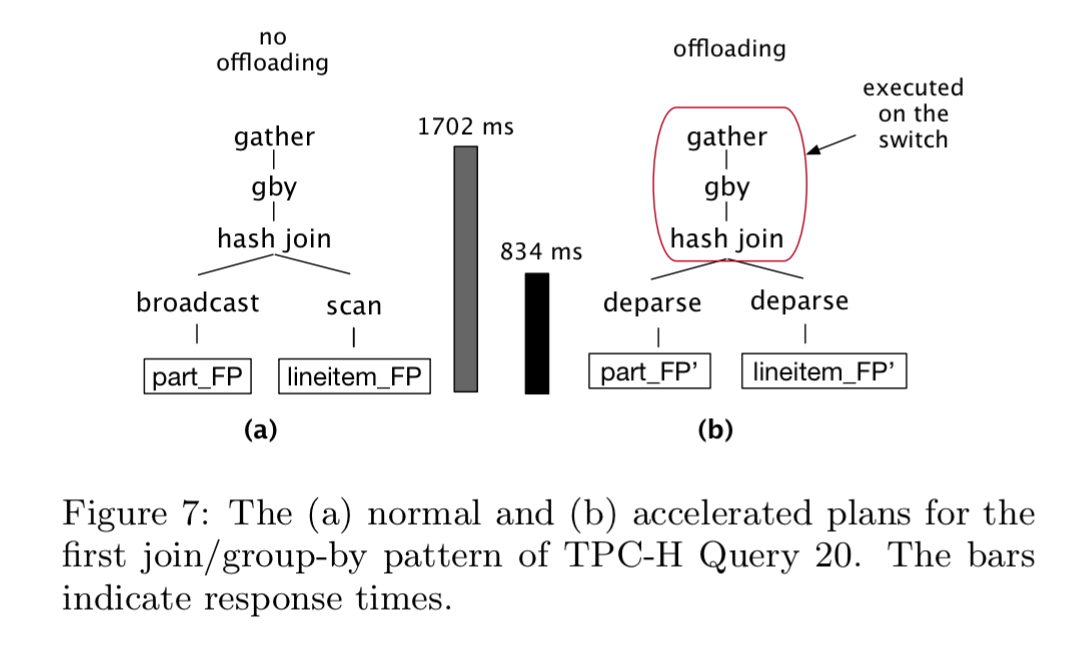
In the normal plan, Greenplum tries to move as little data as possible and to perform the join-and-group-by locally. This is the accepted best practice for distributed plans. Conversely, the accelerated plan pushes both relations onto the switch. The effective network speed the deparse achieved in that case was within 2% of the nominal maximum of 25 Gbps. The accelerated plan ran 2.04x faster.
A second experiment explores the allocation of MAU tables to either the join or group-by stages, finding that it is more advantageous to assign extra MAUs to the join rather than to the group-by.
A final experiment investigates the effects of varying network speed. In the chart below, the ‘original’ bar shows the plan originally chosen by Greenplum, and ‘normal’ is the best possible plan of the query without using the network acceleration. The ‘accel’ bar shows the performance achieved with network acceleration, and the ‘min’ bar shows the theoretically minimum time it would take if the network was systematically saturated.
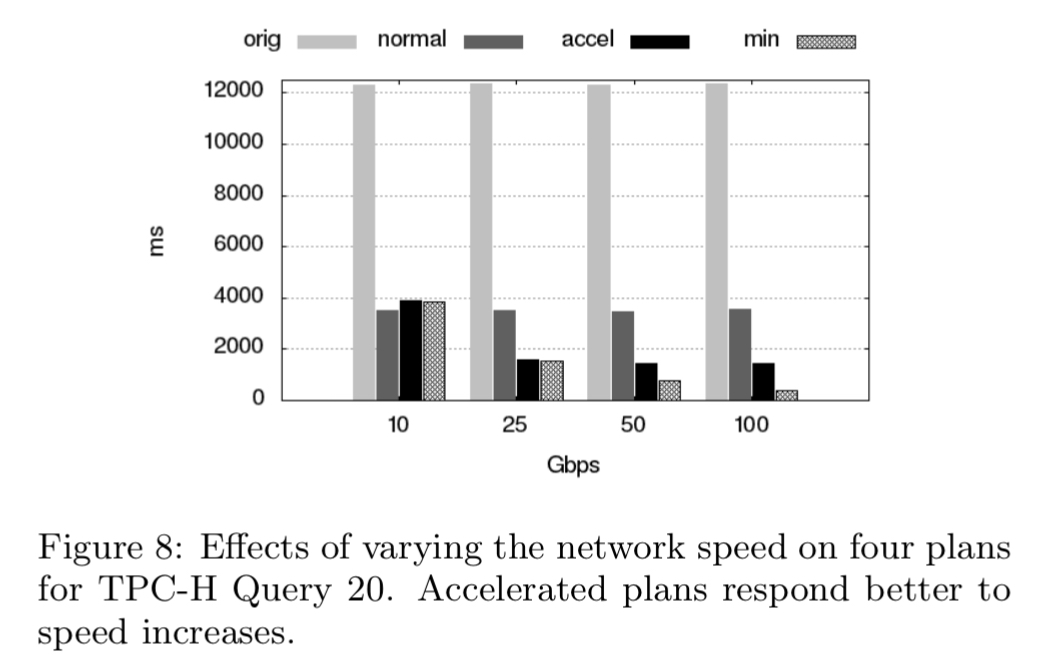
The current limitation to getting the ‘accel’ performance closer to ‘min’ is the deparser, which plateaus at 29 Gbps.
Realizing the potential speed— the difference between the ‘min’ bar at a given speed and the ‘accel’ one— requires some future work (e.g., by using RDMA).
Research agenda
NetAccel opens several fundamental research directions to be explored, including:
- CPU offloading to deparse tuples onto the network without involving the CPU (e.g., RDMA, smart NICs).
- Richer offloading strategies beyond simple control plane overflow
- MAU allocation strategies for efficient and flexible allocation
- Switch paralllelism that distributes work across several pipelines
- Updating the query optimiser and cost model to accommodate the option of in-network processing. Whereas traditional plans aim to minimise data movement, network-accelerated strategies benefit from minimising intermediate states.
While realizing the full potential of our vision will take years, we are excited by the prospect of NetAccel and by the new data processing avenues opening up with the advent of next-generation networking equipment.
I have to say, I can’t wait to see where this will take us. I have a feeling it’s going to be a big part of large scale data processing in the future.

{kind=link}
{kind=link}
The post you shared here is full of knowledge. Networking is an area in constant evolution. New protocols keep arising from emerging fields such as virtualization cloud computing or the Internet-of-Things. Many such protocols are implemented in hardware-based
switches.
Hi,
Thanks for sharing info.