SageDB: a learned database system Kraska et al., CIDR’19
About this time last year, a paper entitled ‘The case for learned index structures’ (part I, part II) generated a lot of excitement and debate. Today’s paper choice builds on that foundation, putting forward a vision where learned models pervade every aspect of a database system.
The core idea behind SageDB is to build one or more models about the data and workload distribution and based on them automatically build the best data structures and algorithms for all components of the database system. This approach, which we call “database synthesis” will allow us to achieve unprecedented performance by specializing the implementation of every database component to the specific database, query workload, and execution environment.
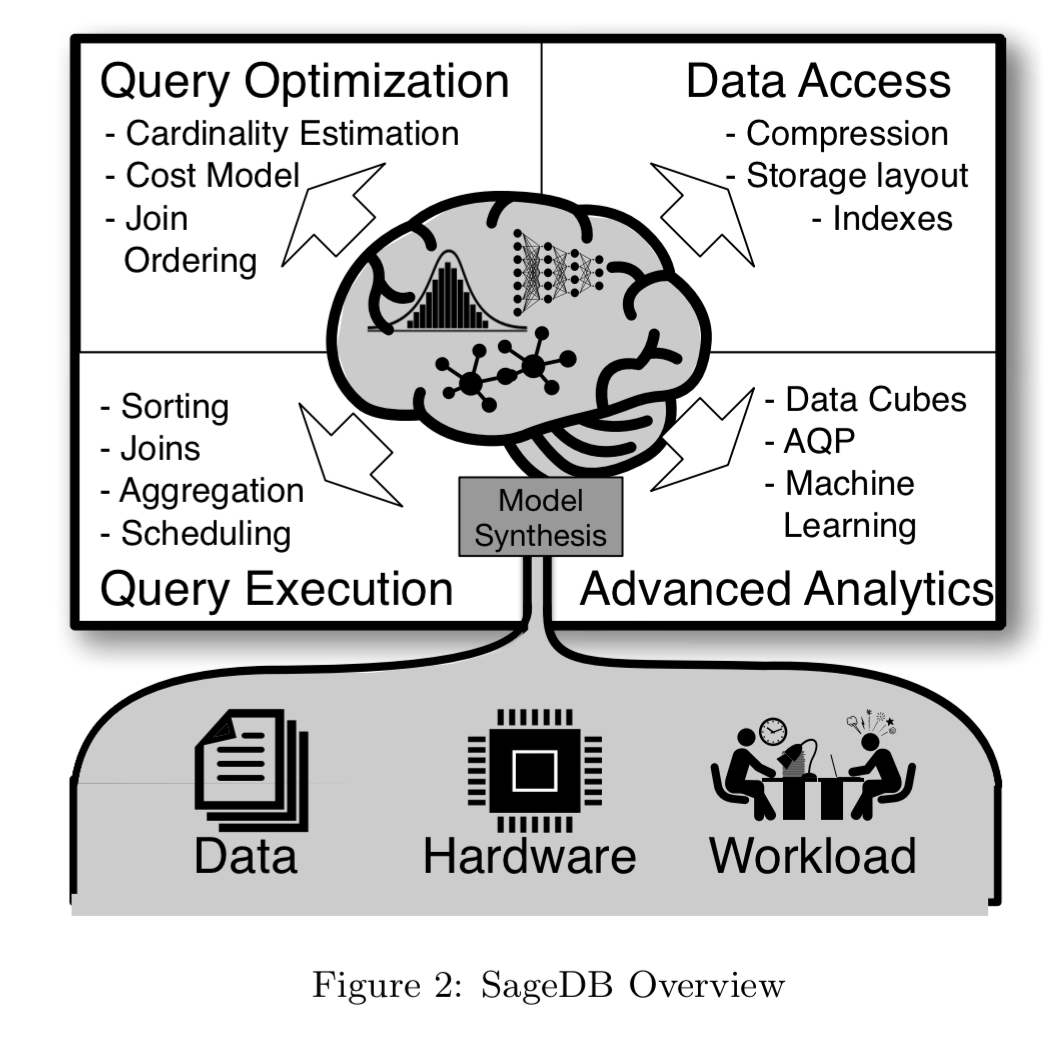
For the want of a model
In the absence of runtime learning and adaptation, database systems are engineered for general purpose use and do not take full advantage of the specific characteristics of the workload and data at hand. The size of the opportunity for SageDB is the gap between such an approach and what is possible when designing a specialised solution with full knowledge of the data distribution and workload.
Consider an extreme case: we want to store and query ranges of fixed-length records with continuous integer keys. Using a conventional index here makes no sense as the key itself can be used as an offset. A C program loading 100M integers into an array and summing over a range runs in about 300ms. Doing the same operation in Postgres takes about 150 seconds: a 500x overhead for the general purpose design.
…we can optimize almost any algorithm or data structure used by the database with knowledge of the exact data distribution. These optimizations can sometimes even change the complexity class of well-known data processing algorithms.
Knowledge of the data distribution comes in the form of a (learned) model. Armed with such a model, the authors argue that we can automatically synthesise index structures, sorting and join algorithms, and even entire query optimisers, leveraging the data distribution patterns for performance gains.
Overfitting is good
What kind of a model makes sense? A histogram for example is a very simple model, but for the use cases discussed here either too coarse-grained or too big to be useful. At the other end of the spectrum, deep and wide neural nets come with high costs (though these are expected to decrease with advances in hardware). Combine this with the fact that for this use case, ‘overfitting’ is good! We want to capture the precise nuances of our exact data as precisely as possible. (The research program to date is largely focused on analytic workloads, some degree of generalisation is clearly beneficial once we start to consider updates).
As of today, we found that we often need to generate special models to see significant benefits.
As an example, consider the RMI model from ‘The case for learned index structures’ :
- Fit a simple model (linear regression, simple neural net etc.) over the data
- Use the prediction of the model to pick another model, an expert, which more accurately models the subset of the data
- Repeat the process until the leaf model is making a final prediction
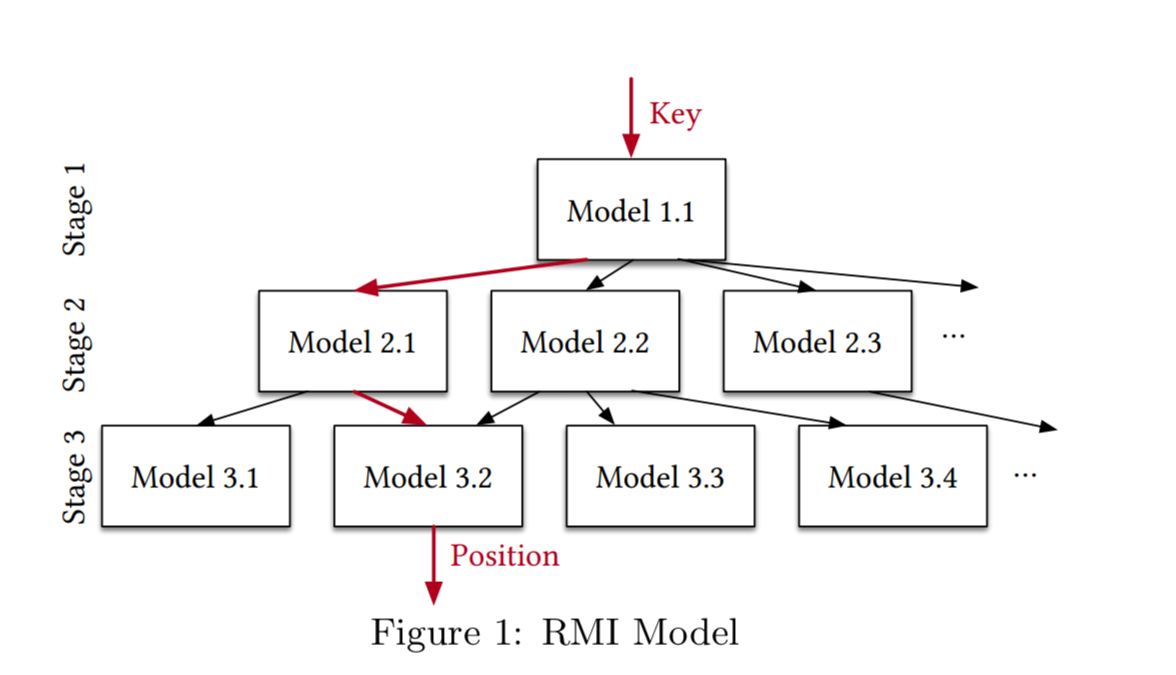
RMI is just a starting point. For example, it is possible to make the top model or bottom model more complex, replace parts of the models at a particular level stage with other types of models, use quantization, vary the feature representation, combine models with other data structures, and so on. We therefore believe we will see an explosion of new ideas on how to most efficiently generate models for database components to achieve the right balance between precision, low latency, space, and execution time for a given workload.
Data access
Last year’s paper on ‘The case for learned index structures’ showed that an RMI-based index can outperform state of the art B-Tree implementations by a factor of two while being orders of magnitude smaller (“note that the updated arXiv version contains new results“). Subsequent work has extended this to data stored on disk, compression inserts, and multi-dimensional data.
For multi-dimensional data, the baseline is an R-Tree (as opposed to a B-Tree). R-Trees map rectangles to a list of index ranges such that the index of every point lying in the rectangle is contained in the union of these ranges. We can replace an R-Tree with a learned model, just as we could the B-Tree. One of the tricks that makes the RMI B-Tree replacement work is that it is sufficient for the model to get us ‘in the right locality’ and then we can do a local search around the prediction to finish the job. For R-Trees, we also need a layout that enables efficient localised search.
While many possible projection strategies exist, we found that successively sorting and partitioning points along a sequence of dimensions into equally-sized cells produces a layout that is efficient to compute, learnable (e.g., in contrast to z-order, which is very hard to learn), and tight (i.e., almost all points in the union of the index ranges satisfy the query).
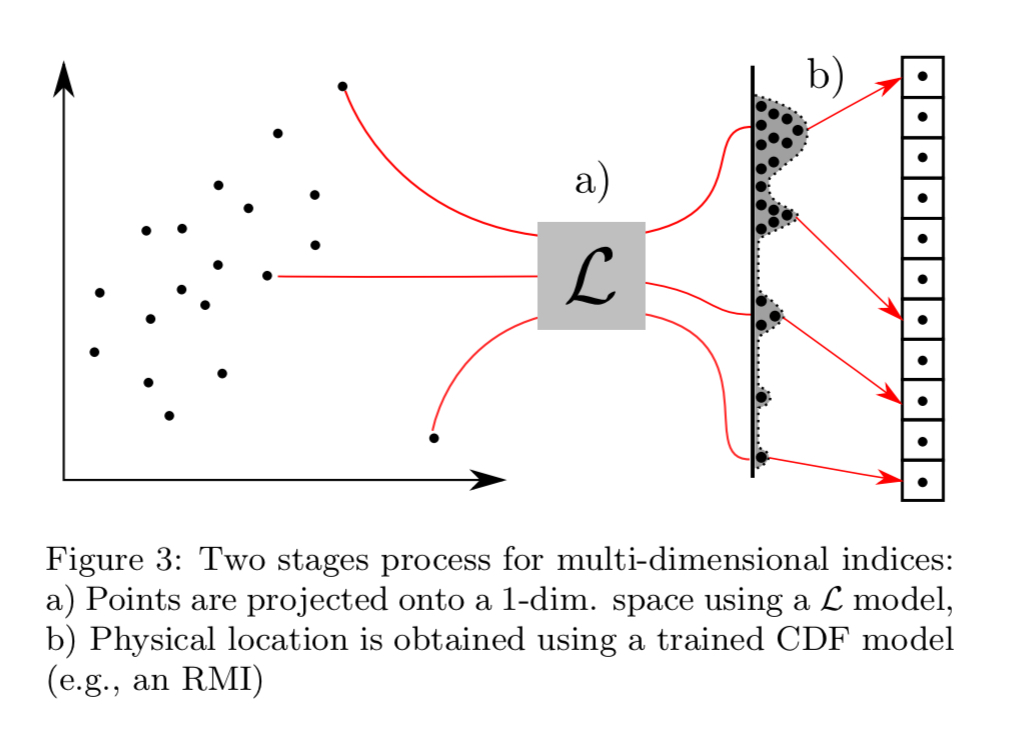
The authors implemented such a learned index over an in-memory column store with compression, and compared it to a full column scan, a clustered index (sorting by the column providing the best overall performance), and an R-Tree. The benchmarks used 60 million records from the lineitem table of the TPC-H benchmark, with query selectivity of 0.25%.
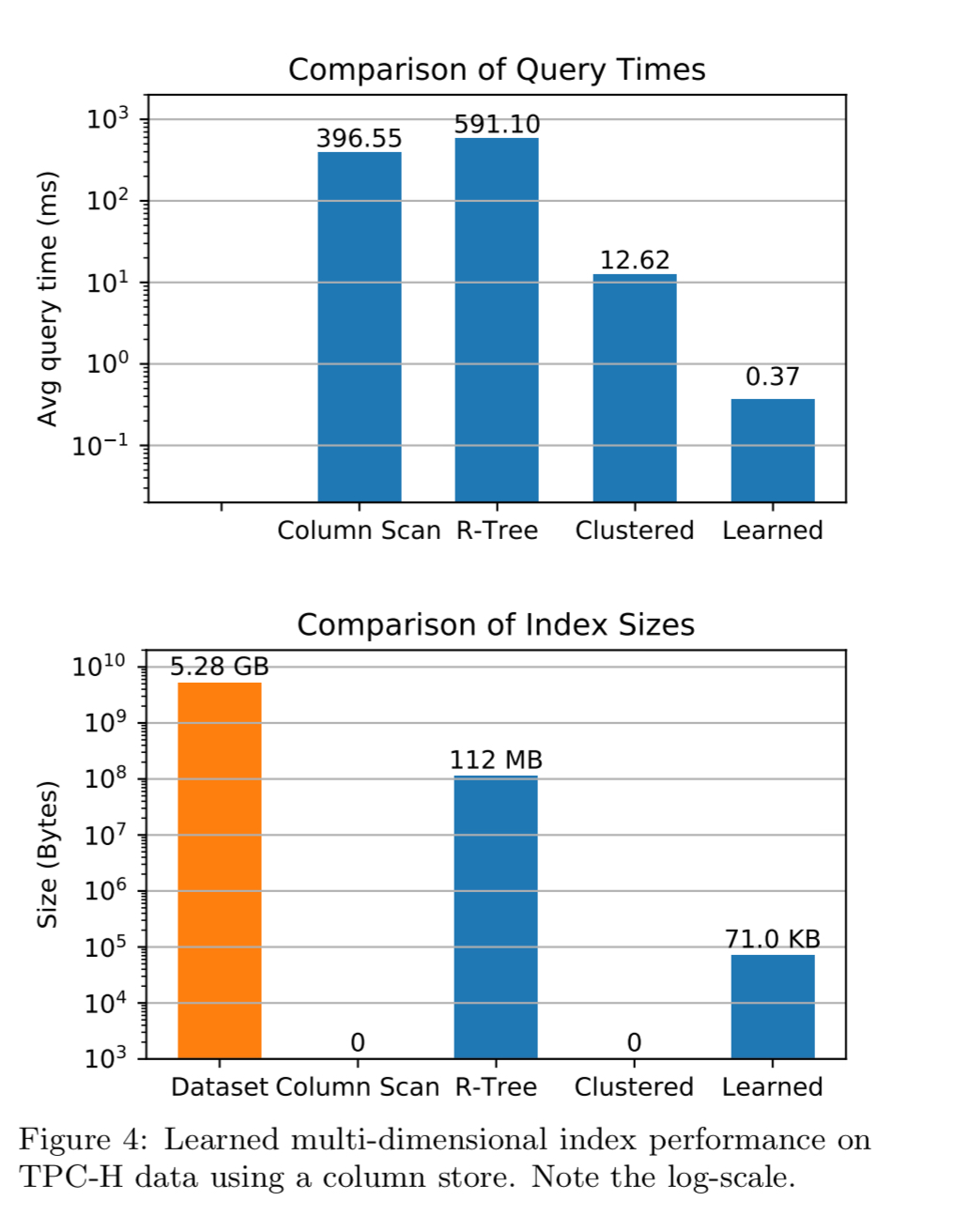
The learned index beats the next best performing implementation by 34x (note the log scales on the charts) and has only a tiny space overhead compared to the clustered solution.
Further analysis revealed that the learned index beats the clustered index on almost every type of query – the exception is when the clustered dimension in the clustered index is the only dimension in the query.
Query execution
This is one of my favourite parts of the paper, because it demonstrates how learned models can even help in the humble and age-old case of sorting. The approach to sorting is to use a learned model to put the records into roughly the right order, and then correct the nearly perfected sorted data as a final step. For this an efficient local-sort such as insertion sort can be used, which is very fast with almost-sorted arrays.

The figure below shows results of a learned approach to sorting for increasingly large data sizes of 64-bit doubles randomly sampled from a normal distribution. In the comparison, Timsort is the default sort for Java and Python, std::sort is from the C++ library. The learned variant is 18% faster than the next best (Radix sort in this case) on average.
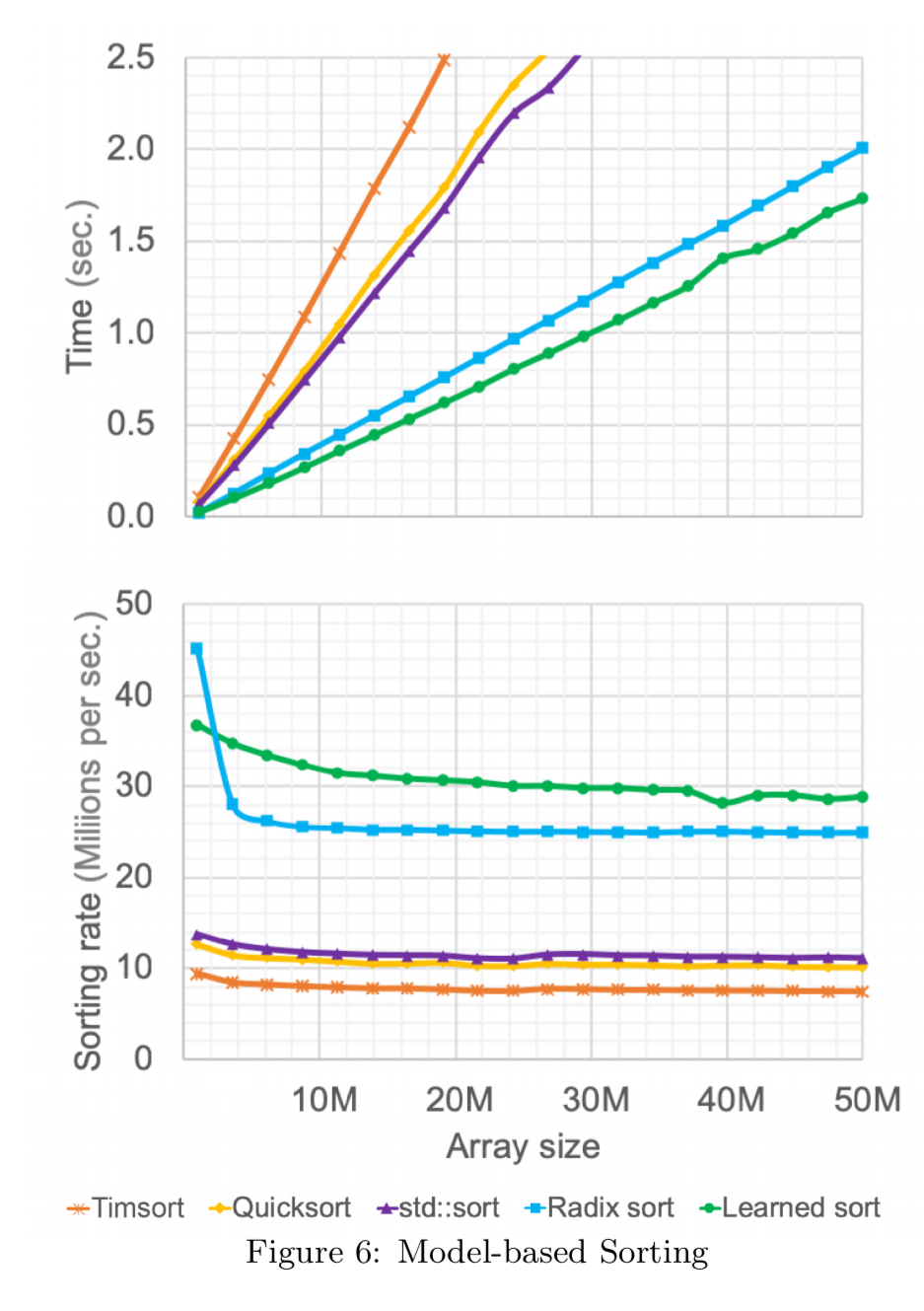
(This doesn’t include the time taken to learn the model).
Learned models can also be used to improve joins. For example, consider a merge-join with two stored join columns and a model-per-column. We can use the model to skip data that will not join (the authors don’t detail how the equivalent of ‘local patching’ is supposed to work in this scenario, it’s not immediately obvious to me).
The authors also experimented with workload aware schedulers, implementing a reinforcement-learning based scheduling system using a graph neural network:
Our system represents a scheduling algorithm as a neural network that takes as input information about the data (e.g., using a CDF model) and the query workload (e.g, using a model trained on previous executions of queries) to make scheduling decisions.
On a sample of 10 TPC-H queries, the learned scheduler improved average job completion time by 45% over Spark’s default FIFO scheduler.
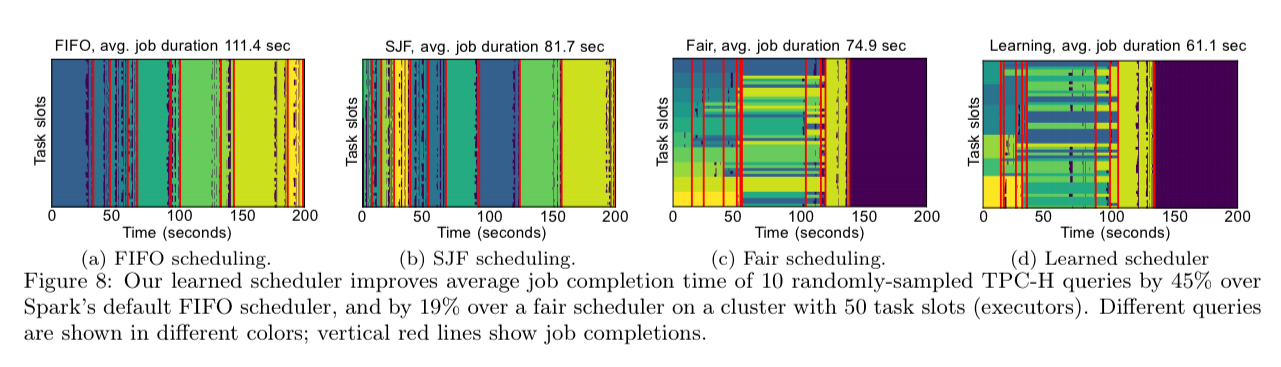
The strategy that the scheduler learned to get this improvement was to combine completing short jobs quickly with maximising cluster efficiency, learning to run jobs near their parallelism ‘sweet spot.’
Query optimiser
Traditional query optimizers are extremely hard to build, maintain, and often yield sub-optimal query plans. The brittleness and complexity of the optimizer makes it a good candidate to be learned…
Initial experiments starting with a traditional cost model and refining it over time through learning showed that the model quality can be improved, but that to make big gains would require making significant improvements to cardinality estimation. The research direction now (no reported results as yet) is to explore hybrid-model based approaches to cardinality estimation. These hybrid models combine a learned model of the underlying data patterns and correlations, with exception/outlier listens that capture extreme (and hard to learn) anomalies of the particular instance of the data.
Other areas
Other suggested areas where learned models may prove beneficial in the future include approximate query processing, predictive modelling, and workloads including inserts and updates.
The last word
SageDB presents a radical new approach to build database systems, by using ML models combined with program synthesis to generate system components. If successful, we believe this approach will result in a new generation of big data processing tools, which can better take advantage of GPUs and TPUs, provide significant benefits in regard to storage consumption and space, and, in some cases, even change the complexity class of certain data operations.

Like the original learned indexes paper, I suspect their results look so dramatic because they sandbagged the baseline. Two obvious examples: why are they clustering on a single dimension for multidimensional data? Why not cluster on a simple space-filling curve like z-order? And then their learned scheduler outperforms a FIFO queue, amazing! Given that they already model query workloads, how about a dead-simple Shortest Job First scheduler? I look forward to some pointed criticism like the learned indexes paper received.
Great article. I think you might be interested in an alternative approach to learned indexes. This approach called Sparsey is based on representing items with as fixed-size sparse distributed representations (SDR), i.e., small subsets of binary units chosen from a much larger field. I’ve just published a Medium article, “Learned Multidimensional Indexes” (https://medium.com/@rod_83597/learned-multidimensional-indexes-171c93fb581a) describing how SDR implements multidimensional indexing.