Design continuums and the path toward self-designing key-value stores that know and learn Idreos et al., CIDR’19
We’ve seen systems that help to select the best data structure from a pre-defined set of choices (e.g. ‘Darwinian data structure selection’), systems that synthesise data structure implementations given an abstract specification (‘Generalized data structure synthesis’), systems that use learning to tune configurations given a pre-defined set of configuration options (e.g, ‘BOAT: Building auto-tuners with structured Bayesian optimization’), systems that use learned models as key inputs to algorithms (e.g. ‘SageDB: a learned database system’), and systems that use reinforcement learning to discover fit-for-workload policies (‘Towards a hands-free query optimizer through deep learning’). Today’s paper choice jumps right into the middle of this mix, showing how families of data structures can be organised into design continuums with well-understood design parameters and cost models informing selection of a given data-structure design from within the space. As well as helping us to understand and reason about data structures within the space, the constrained feature space with quick-to-evaluate cost models opens the way to practical machine learning guided data structure synthesis and selection. The notion of design continuums is explored in the context of one specific continuum: data structures for key-value stores.
…these properties allow us to envision a new class of self-designing key-value stores with a substantially improved ability to adapt to workload and hardware changes by transitioning between drastically different data structure designs to assume a diverse set of performance properties at will.
The paper jumps back and forward between the details of the design continuum for KV-stores, and the idea of a design continuum itself. I shall put more emphasis on the latter in this write-up.
What is a design continuum?
Selecting a data structure involves making trade-offs: what’s right for one workload and set of objectives may not be right for another. When we’re building systems by hand, we tend to create either (a) general purpose systems, or (b) systems positioned towards extremes in the design space, specialised for a particular task. There’s a lot of ground between the two. The picture that emerges for me is that we’re heading towards a world of ‘personalisation’ (mass-customisation) for system software. In consumer facing software, personalisation is the idea that the system can learn the interests and preferences of its individual users, and tailor the user experience for each. Whereas we all used to get a general purpose user-experience, now personalisation is everywhere. In system software, the ‘user’ is a workload, and by learning the ‘preferences’ (characteristics) of that workload we can deliver an optimised ‘experience’ when executing it. Instead of general purpose we have fit-for-(this exact)-purpose.
Mass customisation requires (a) that we be able to enumerate points in the data structure space such that we can explore it efficiently, and (b) a way of efficiently evaluating the performance of a given data structure design. In general this is a really hard problem because the design space is vast.
Our insight is that there exist “design continuums” embedded in the design space of data structures. An intuitive way to think of design continuums is as a performance hyperplane that connects a specific set of data structure designs. Design continuums are effectively a projection of the design space, a “pocket” of designs where we can identify unifying properties among its members.
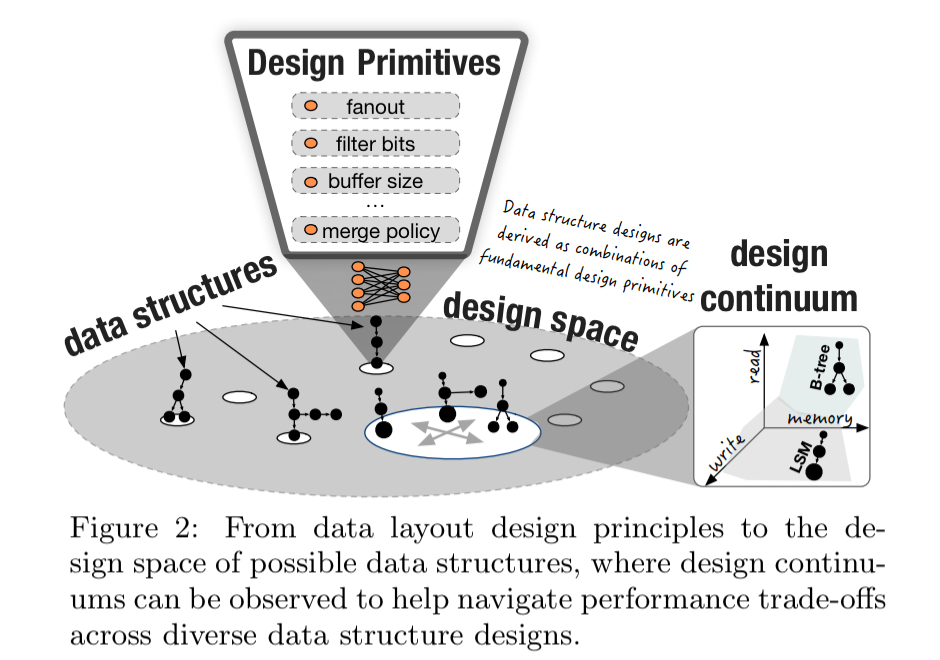
A properly constructed design continuum has a small set of design parameters forming a continuous performance tradeoff for fundamental performance metrics.
Constructing design continuums
A design continuum has five main elements.
Firstly there are a set of environment parameters which give us critical information about the workload and the environment (e.g. hardware) it runs on. For the key-value store design continuum, the authors use the following environment parameters:
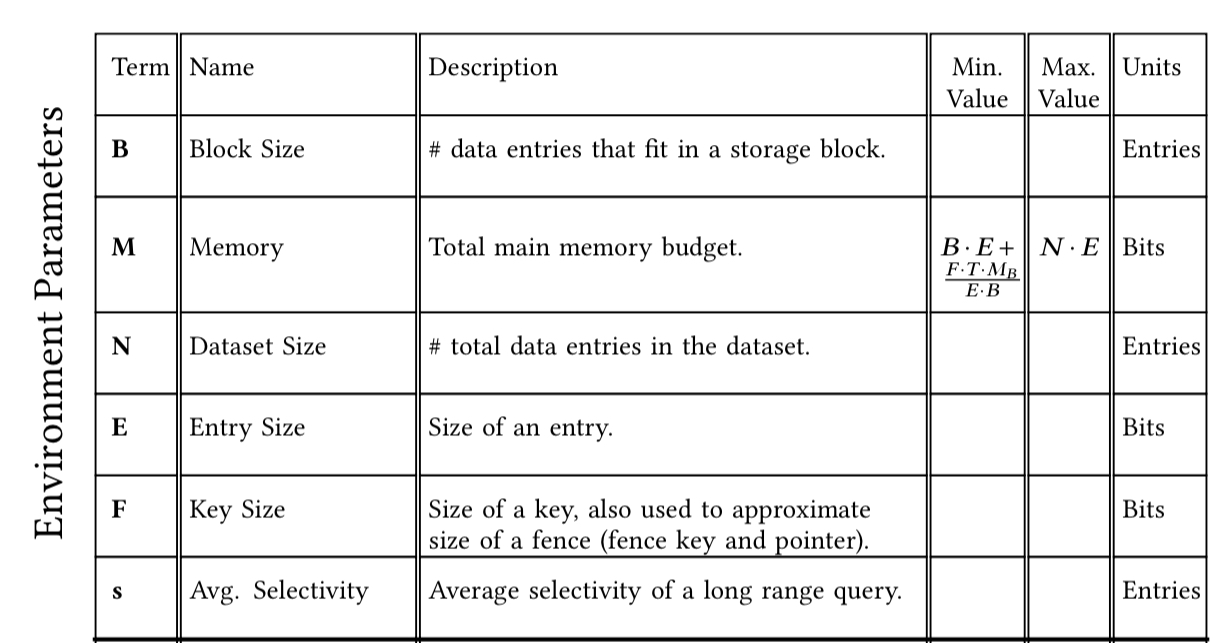
Secondly, a super-structure shows how design primitives can be combined in structured ways to create families of data structures. In the key-value store example, the super-structure is based on the founding idea of a number of layers or levels, with upper levels being hot, and lower levels progressively colder.
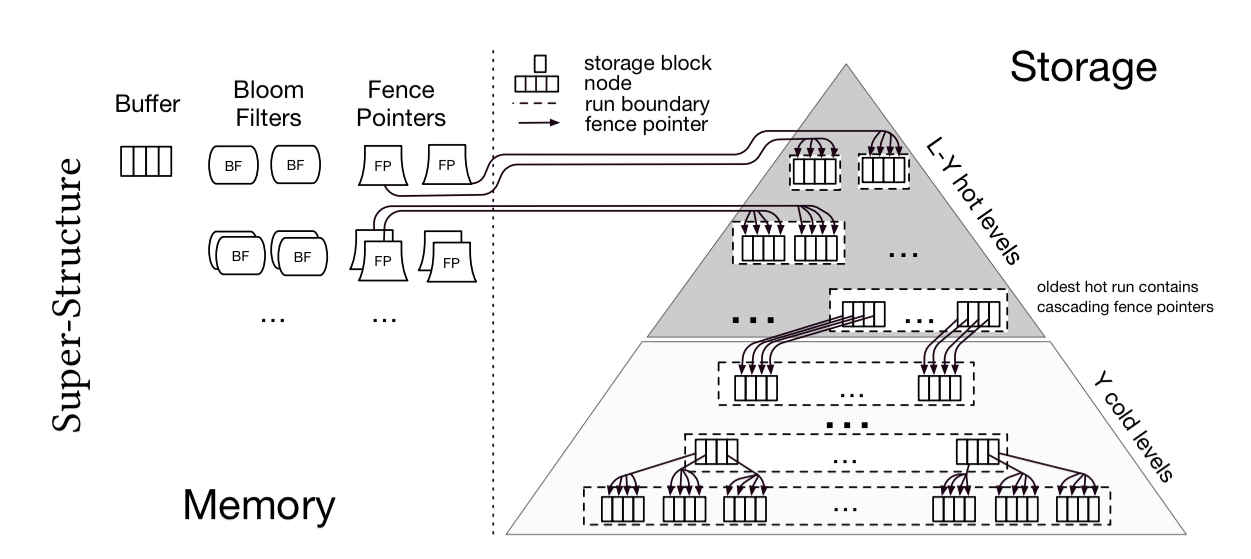
Third, a set of design parameters form the externalised ‘knobs’ that can be tuned to influence the design. The ideal is to have the smallest set of movable design abstractions that permit differentiating among target designs in the continuum.
Specifically, fewer design parameters (for the same target designs) lead to a cleaner abstraction which in turn makes it easier to come up with algorithms that automatically find the optimal design. We minimize the number of design parameters in two ways: 1) by adding deterministic design rules which encapsulate expert knowledge about what is a good design, and 2) by collapsing more than one interconnected design decisions to a single design parameter.
For the key-value store design continuum, we have the following design parameters:
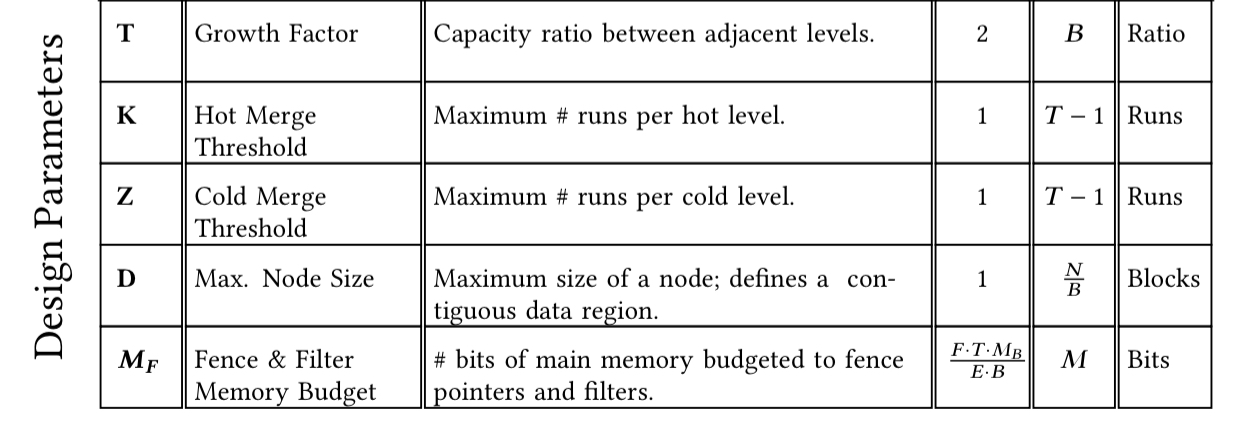
The design parameters inform, but do not themselves directly specify, the choices to be made within the super-structure. For this we have a set of design rules, parameterized by the environment and design parameters. “These rules enable instantiating specify designs by deterministically deriving key design aspects.” For example, in the key-value continuum one of the rules is that the capacity of levels grows exponentially at each level by a factor of T (a design parameter). And a memory budget will first be used for fence pointers, with the remainder assigned to Bloom filters. Here are the design rules for the KV continuum:
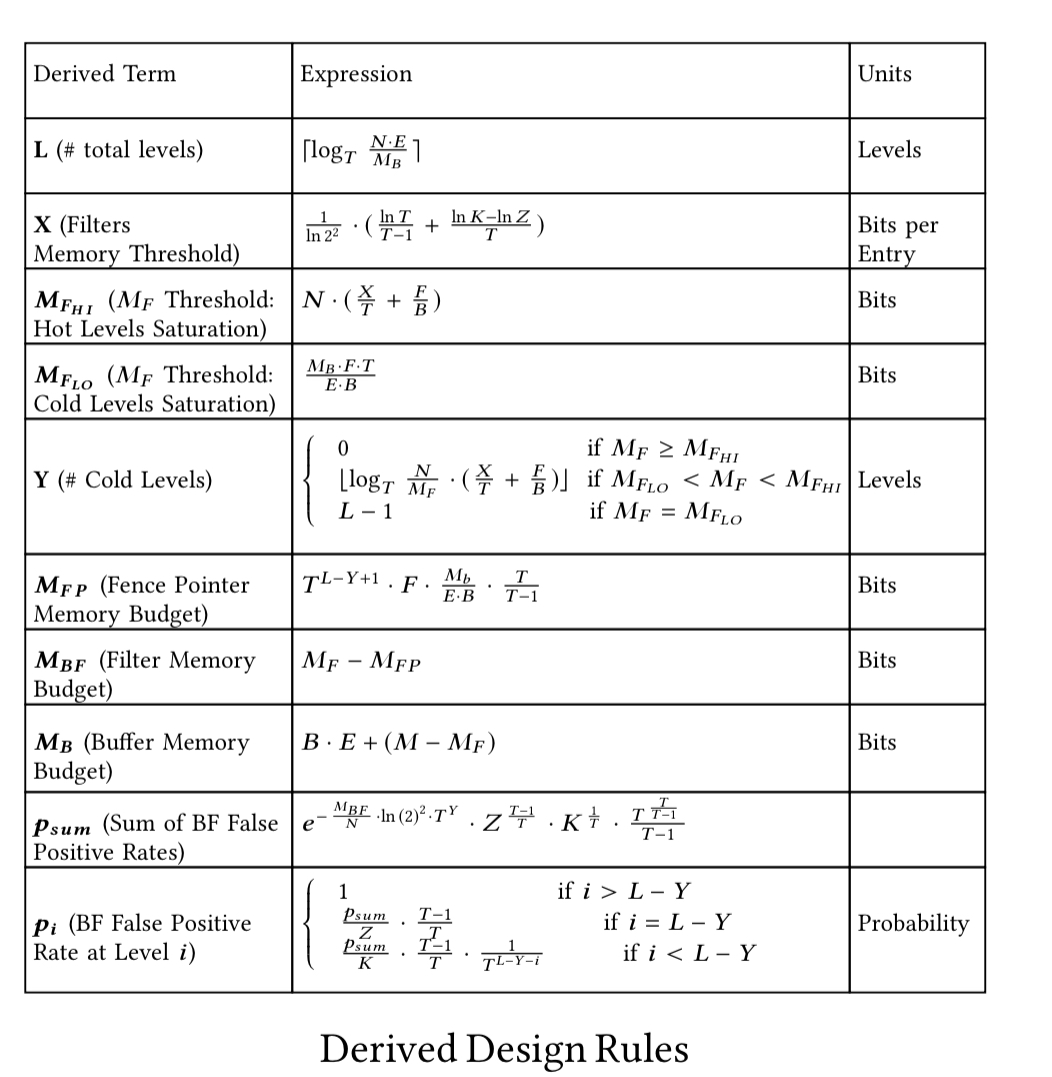
Finally, a cost model provides a closed-form equation for each one of the core performance metrics. The cost model provides an understanding of how changes in the design parameters (configuration tuning) impact the various performance metrics. The cost model for the KV continuum looks like this:
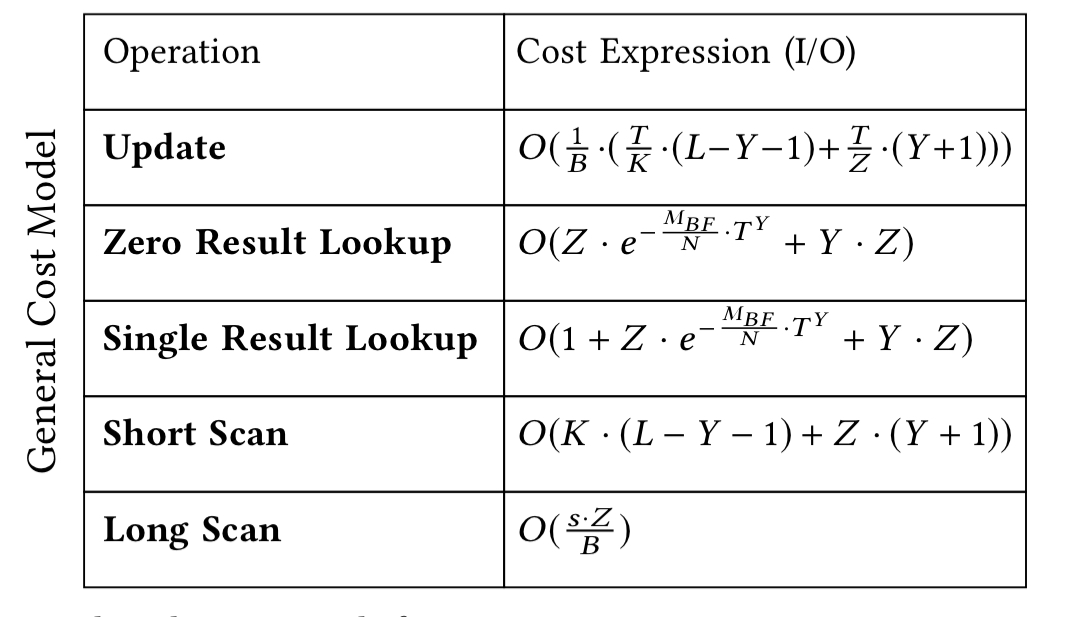
Using the cost model, a theory-of-constraints style approach can be used to find an optimal design: iteratively finding the current limiting factor and the knobs that can be tweaked to alleviate it.
The overall process of putting together a design continuum looks like this, where we proceed from left to right:
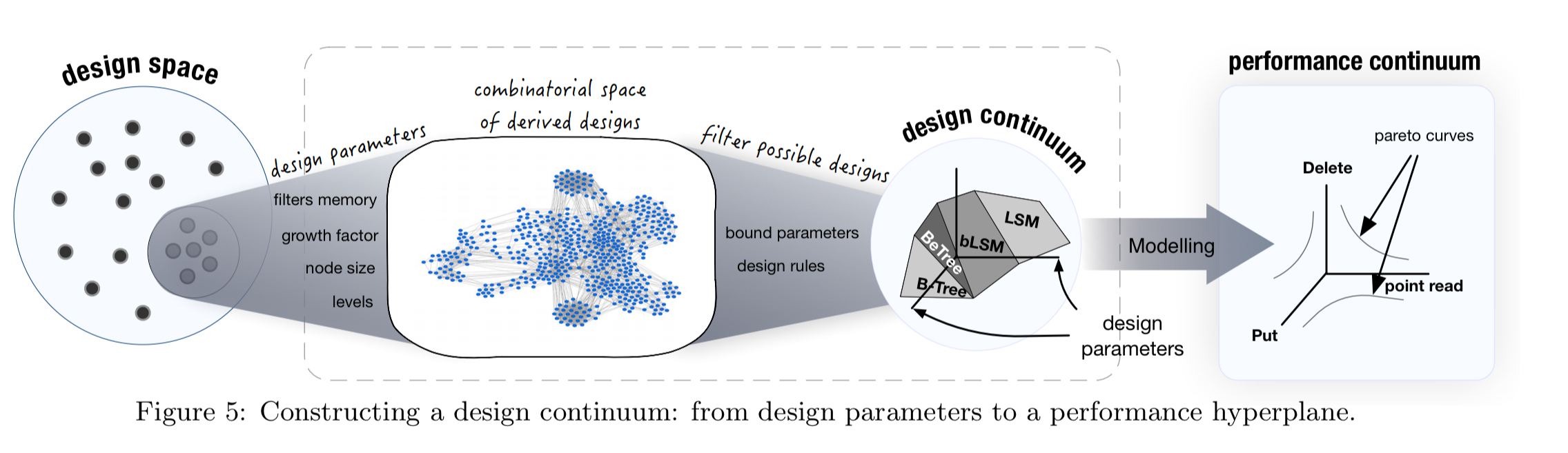
An ideal design continuum has six key properties:
- It is functionally intact; all possible designs should be able to support all operation types (i.e., are substitutable).
- It is pareto-optimal. There should be no two designs such that one of them is better than the other on one or more of the performance metrics (and vice versa) while being equal on all the others.
- It has a one-to-one mapping from the domain of design knobs to the co-domain of performance and memory trade-offs (bijective).
- It enables a diverse set of performance properties.
- The time complexity for navigating the continuum to converge on an optimal or near-optimal design should be tractable. (I.e., it is navigable).
- It is likely to be layered in order to provide a trade-off between diversity and navigability.
Growing a design continuum
One way to evolve a design continuum is to start with a small coherent core and then incrementally extend it. This is a three-step process: bridging, patching, and then costing. Bridging is the initial model extension, which in order of preference can take place by (1) introducing new design rules, (2) expanding the domains of existing design parameters, or (3) adding new design parameters. The bridging process may introduce many new intermediate designs, some of which may not be functionally intact (workable). Patching adds new design rules and/or constraints on permissible design parameter settings to avoid these broken designs. Care should be take that patching only constrains new parts of the continuum opened up by bridging. The final step is to generalize the cost model to account for all the new designs.
Self-designing systems
Knowing which design is the best for a workload opens the opportunity for systems that can adapt on-the-fly. While adaptivity has been studied in several forms including adapting storage to queries, the new opportunity is morphing among what is typically considered as fundamentally different designs, e.g. from an LSM-tree to a B+ tree, which can allow systems to gracefully adapt to a larger array of diverse workload patterns.
The authors identify three challenges on the way to such self-designing systems. Firstly, if we’re going to adapt on-the-fly, then we need way to physically transition among any two designs at runtime (and take into account the cost of those transitions). Secondly, we’ll need to generate tailored code for each design point. Given that we a continuum, it should be possible to write a single generalized algorithm for each operation that can instantiate the concrete algorithm used for that operation in each possible design. Finally, there will be limits to what we can do with rule-based tweaking of design parameters.
The path forward is to combine machine learning with the design continuum. Machine learning is increasingly used to tune exposed tuning knobs in systems. The new opportunity here is the native combination of such techniques with the system design itself… The net result in that design continuums can be blended with ML approaches to co-design a tailored system that both knows how to navigate a vast space of the design space and learns when needed to navigate design options that are hard to deterministically formulate how they will interact with the rest of the design.
The Key-Value store design continuum
I’ve hit my target word limit for a #themorningpaper post, and we haven’t really had a chance to dive into the KV continuum in any detail at all. In brief, the authors show how B+ trees, Log-Structured-Merge trees, and Log-Structured Hash-tables can be combined into one layered design continuum, with different instances falling out from different design parameter choices.
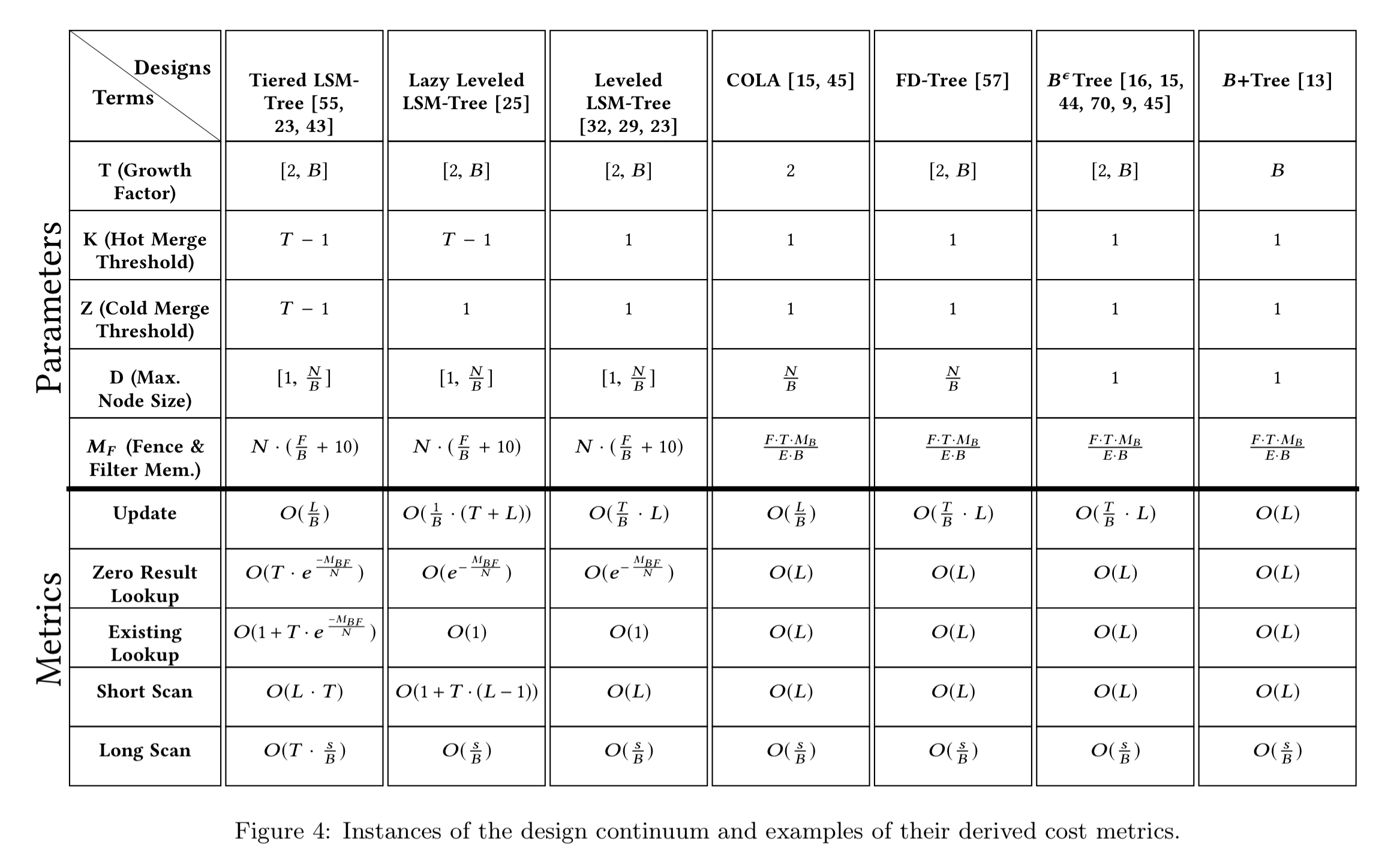
(Enlarge)
There’s a whole bunch of good detail here that’s interesting in its own right, so if the big ideas in the paper have caught your imagination, I definitely encourage you to go and check it out.

{kind=link}
3 thoughts on “Design continuums and the path toward self-designing key-value stores that know and learn”
Comments are closed.