BOAT: Building auto-tuners with structured Bayesian optimization Dalibard et al., WWW’17
Due to their complexity, modern systems expose many configuration parameters which users must tune to maximize performance… From the number of machines used in a distributed application, to low-level parameters such as compiler flags, managing configurations has become one of the main challenges faced by users of modern systems.
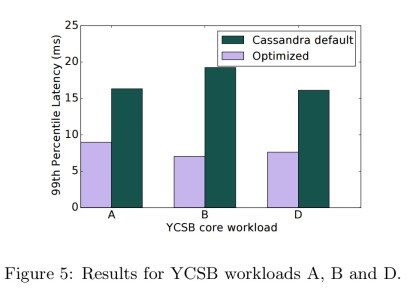
The time and expertise required to optimise configuration settings simply doesn’t exist in many DevOps teams focused on rapidly delivering application functionality. That’s a shame, because optimising the configuration (without changing a single line of application code) can have way bigger benefits than I ever would have imagined before I first starting looking into this space. Today’s paper choice, BOAT, provides further evidence of that, reducing 99%-ile latency from 19ms to 7ms for a Cassandra workload for an optimised setting vs the defaults. In addition, two hours spent tuning the configuration of a TensorFlow computation delivered at least a 2x speed-up in the median time per SGD iteration.
I also know this because I work with a company called Skipjaq. I should declare my interest here: Accel is an investor, I’m a personal investor and board member, and the (highly technical!) CEO is a long-standing friend of mine. So I probably couldn’t be more biased if I tried! Like BOAT (and CherryPick that we also looked at recently), Skipjaq use Bayesian Optimisation to auto-tune applications. As a recent example, after putting the Skipjaq-optimised configuration settings into production, one company observed a 50% reduction in 95%-ile page load times. And as many studies have shown, page load times have an inversely proportional relationship to revenue. I.e., the faster your page loads, the better the engagement and conversion rates.
For another data point, you might want to check out Ramki Ramakrishna from Twitter’s talk on “Continuous optimization of microservices using machine learning.” As Rami concludes, “continuous automated optimization of microservices is possible, even inevitable.”
Hopefully you’re now feeling sufficiently motivated to learn a little more about how BOAT, the BespOke Auto-Tuner works!
Challenges in auto-tuning
… we consider the task of automatically tuning configuration parameters associated with system performance. This can include any parameter for which the optimal value is dependent on the hardware or software context, ranging from low level parameters such as compiler flags or configuration files, to higher level ones like the number of machines used in a computation.
Two primary challenges make this difficult:
- Each performance run is expensive, which means that evolutionary or hill-climbing approaches often requiring thousands of evaluations cannot be applied. One answer to this, as we saw with Cherry Pick, is to use Bayesian optimisation.
- The configuration space of most real world problems is too complex. “Bayesian optimization tends to require fewer iterations to converge than other optimisers, but fails to work in problems with many dimensions (more than 10).”
In the neural network case study included in the parameter, BOAT is applied to a problem with over 30 dimensions. (Skipjaq have also had success using an approach based on Bayesian optimisation, with around 30 dimensions).
Structured Bayesian Optimisation
We covered the basic idea of Bayesian optimisation in the CherryPick write-up a couple of weeks ago, so I’ll just give the briefest of recaps here. Bayesian optimisation incrementally builds a probabilistic model (typically a Gaussian process) of the objective function being minimised. In each iteration it finds a candidate point in the exploration space to explore using an acquisition function (for example, based on expected improvement), and then takes a measurement of the objective function at that point (i.e., runs a performance test in this case). The probabilistic model is then updated using this new measurement.
A key failure mode for Bayesian optimisation is when the probabilistic model fails to accurately capture the objective function landscape after a reasonable number of iterations. This can happen when there are too many dimensions in the model.
Enter structured Bayesian optimisation. The central idea is to improve the accuracy of the probabilistic model (as used by the acquisition function) by exploiting some basic knowledge of the problem at hand instead of starting with a blank slate Gaussian process.
Structured Bayesian optimization (SBO) extends the Bayesian optimization methodology to take advantage of the known structure of the objective function. It uses a structured probabilistic model, provided by the developer, instead of a simple Gaussian process. In BOAT, those models are implemented in our probabilistic programming library.
The SBO process looks just like the standard Bayesian optimisation process, but with the the probabilistic program used to build the underlying model.
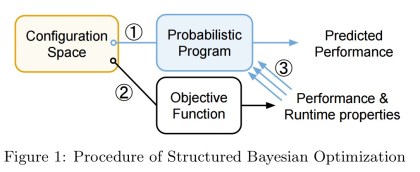
Using a bespoke model captures the user’s understanding of the behaviour of the system, which can drastically reduce the number of iterations needed for the model to converge towards the true objective function. It also allows for monitoring of runtime properties that are reflected in the model, so that they can be used for inference.
An example should help at this point. In the GC case study, the goal is to tune the JVM garbage collector for a Cassandra workload. This optimisation considers the three parameters young generation size, survivor ratio, and max tenuring threshold. The model that the team built included the rate and average duration statistics for minor collections, predicting both of these values given the configuration. It then predicted latency as a function of the configuration values, rate, and average duration.
When using the model in BOAT, we collected the true value of these statistics from the GC logs after each evaluation and used them for inference. Further, we declared how we believed each of the three model components behaved as a function of their inputs. For example, we noticed the rate of minor collections was inversely proportional to the size of the eden memory region in the JVM-heap, which is where objects are initially allocated. This intuition was included in the corresponding model by building a semi-parametric model, which can successfully combine a user-defined trend with empirical data.
Here’s what a model component for predicting rate looks like in code:
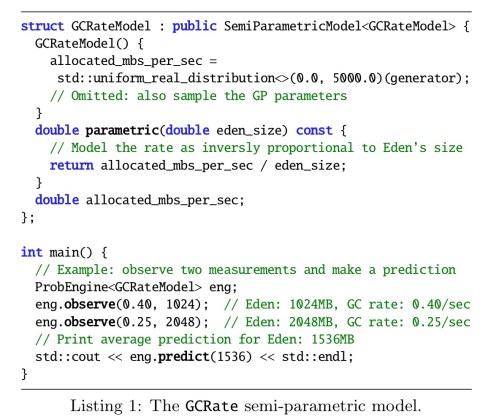
In practice, adding only a little structure can be sufficient to make the optimization converge in a reasonable time. This is useful as simpler models are able to adapt to a broad variety of behaviors, such as widely different hardware and workloads. This allows the construction of bespoke autotuners providing global performance portability.
Building probabilistic models in BOAT
The authors give two recommendations for building useful models. Firstly, models should consist of a combination of independent components, with each component predicting a single observable value. Secondly, each component should be a semi-parametric model. What’s that all about?
Consider a model predicting the time it takes to insert an element into a sorted vector. Imagine that so far we have taken five observations. If we are using a parametric model such as linear regression, we’ll try to fit a straight line, resulting in underfitting:
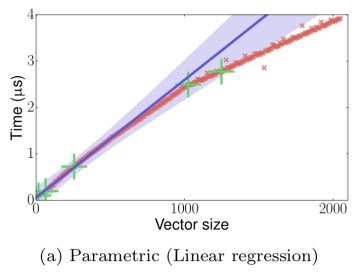
If on the other hand we use a non-parametric model such as a Gaussian process we may end up fitting the data points, but missing the general trend (overfitting):

Semi-parametric models combine parametric and non-parametric models. “The non-parametric model is used to learn the difference between the parametric model and the observed data.” For example, if we simply combine the previous two models, we arrive at our Goldilocks moment:
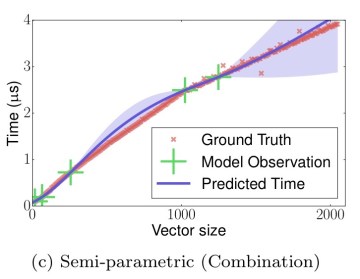
When building a model’s component in BOAT, we recommend starting with a non-parametric model and adding structure until the optimization converges in satisfactory time.
To combine several of these individual semi-parametric models (each predicting a single observable value) into a single global model, developers define the flow of data between them using a DAG. The example Cassandra model below combines rate, duration and latency.

Evaluation results
For the Cassandra optimisation, the BOAT auto-tuner using the model above was run for 10 iterations on YCSB workloads.
Our optimised configuration outperforms the Cassandra default configuration by up to 63%… Each optimization converges to within 10% of the best found performance by the second iteration.
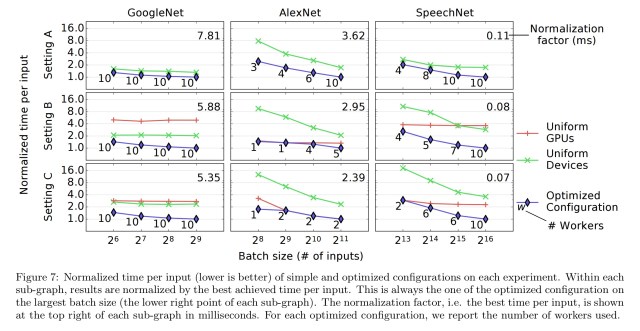
The second case study involves tuning a TensorFlow-based distributed computation.
Our tuner takes as input a neural network architecture, a set of available machines and a batch size. It then performs ten iterations, each time evaluating a distributed configuration, before returning the one with highest performance. The tuning always finishes within two hours which is small compared to the typical training time of neural networks.
The probabilistic model again contains three components:
- The individual device (CPU or GPU) computation time needed for a worker to perform its assigned workload
- The individual machine computation time for machines with multiple devices.
- The communication time based, on learning connection speed per type of machine and predicting communication time given the amount of data that must be transferred in each iteration by a given machine.
In our experiments, we tune the scheduling over 10 machines, setting 30-32 parameters. In our largest experiment there are approximately 10^53 possible valid configurations, most of which lead to poor performance.
Here you can see the results of the optimisation as compared to a uniform devices configuration which simply balances load equally among all devices, and a uniform GPUs configuration which balances load equally among all GPUs.
BOAT is open source and available at https://github.com/VDalibard/BOAT.
A blatant Skipjaq plug
If you like the sound of the performance optimisation that Bayesian optimisation-based auto-tuning of configuration can deliver, but don’t have the time or inclination to set up your own Bayesian optimiser, define load tests that mirror production workloads, and run performance tests in such a way that results give a true indication of likely production performance, then you might want to give Skipjaq a try to see what difference it can make with your own apps. Optimisation without any of the hassle. If you’re quick you might still be able to nab a place in the private beta!

2 thoughts on “BOAT: Building auto-tuners with structured Bayesian optimization”
Comments are closed.