Towards a hands-free query optimizer through deep learning Marcus & Papaemmanouil, CIDR’19
Where the SageDB paper stopped— at the exploration of learned models to assist in query optimisation— today’s paper choice picks up, looking exclusively at the potential to apply learning (in this case deep reinforcement learning) to build a better optimiser.
Why reinforcement learning?
Query optimisers are traditionally composed of carefully tuned and complex heuristics based on years of experience. Feedback from the actual execution of query plans can be used to update cardinality estimates. Database cracking, adaptive indexing, and adaptive query processing all incorporate elements of feedback as well.
In this vision paper, we argue that recent advances in deep reinforcement learning (DRL) can be applied to query optimization, resulting in a “hands-free” optimizer that (1) can tune itself for a particular database automatically without requiring intervention from expert DBAs, and (2) tightly incorporates feedback from past query optimizations and executions in order to improve the performance of query execution plans generated in the future.
If we view query optimisation as a DRL problem, then in reinforcement learning terminology the optimiser is the agent, the current query plan is the state, and each available action represents an individual change to the query plan. The agent learns a policy which informs the actions it chooses under differing circumstances. Once the agent decides to take no further actions the episode is complete and the agent’s reward is (ideally) a measure of how well the generated plan actually performed.
There are a number of challenges, explored in this paper, with making this conceptual mapping work well in practice. Not least of which is that evaluating the reward function (executing a query plan to see how well it performs) is very expensive compared to e.g. computing the score in an Atari game.
The ReJOIN join order enumerator
ReJOIN explores some of these ideas on a subset of the overall query optimisation problem: learning a join order enumerator.
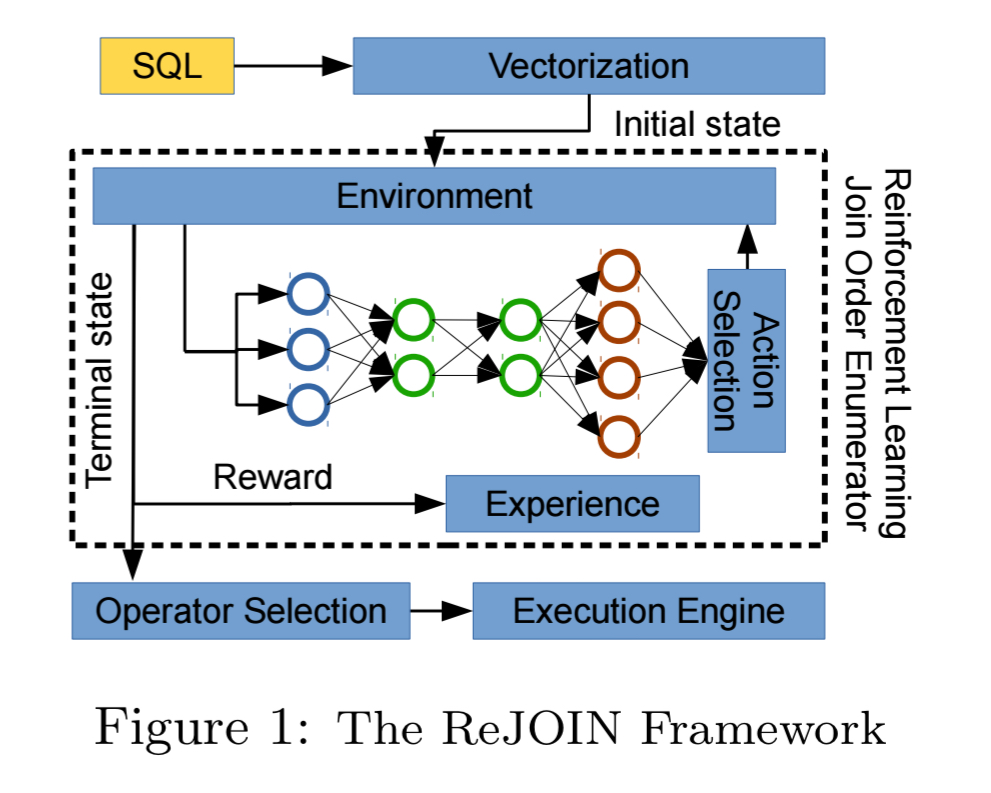
Each query sent to ReJOIN is an episode, the state represents subtrees of a binary join tree together with information about the query join and selection predicates. Actions combine two subtrees into a single tree. Once all input relations are joined the episode ends, and ReJOIN assigns a reward based on the optimiser’s cost model. It’s policy network is updated on the basis of this score. The final join ordering is passed to the optimiser to complete the physical plan.
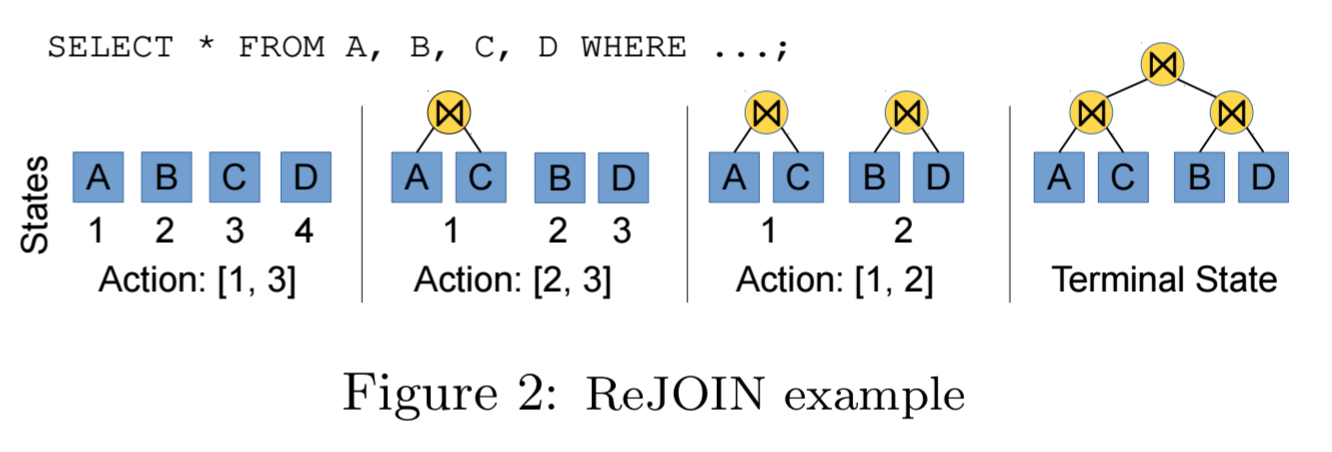
Using the optimiser’s cost model as a proxy for the ultimate performance of a generated query plan enables join orderings to be evaluated much more quickly.
The following chart shows how ReJOIN learns to produce good join orders during training. It takes nearly 9000 episodes (queries) to become competitive with PostgreSQL.
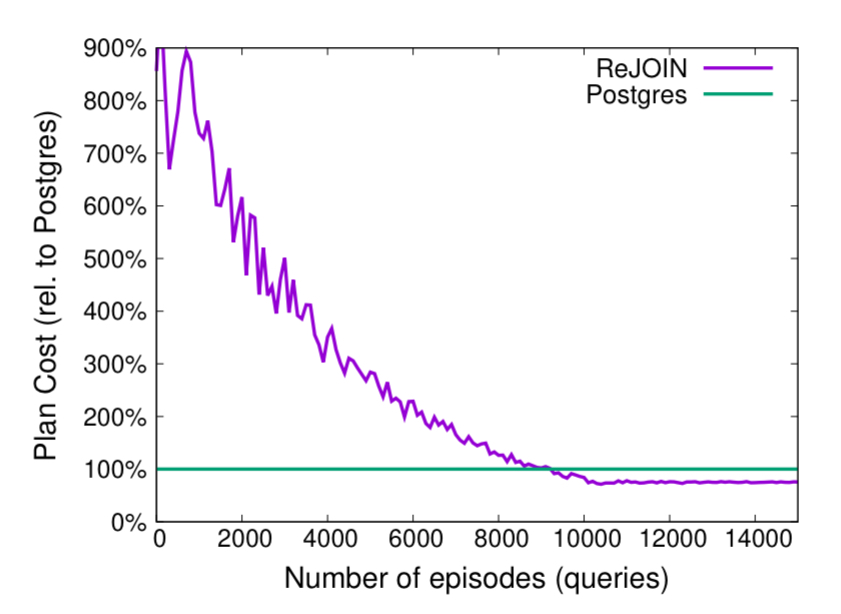
Once ReJOIN has caught up with PostgreSQL, it goes on to surpass it, producing orderings with lower cost.
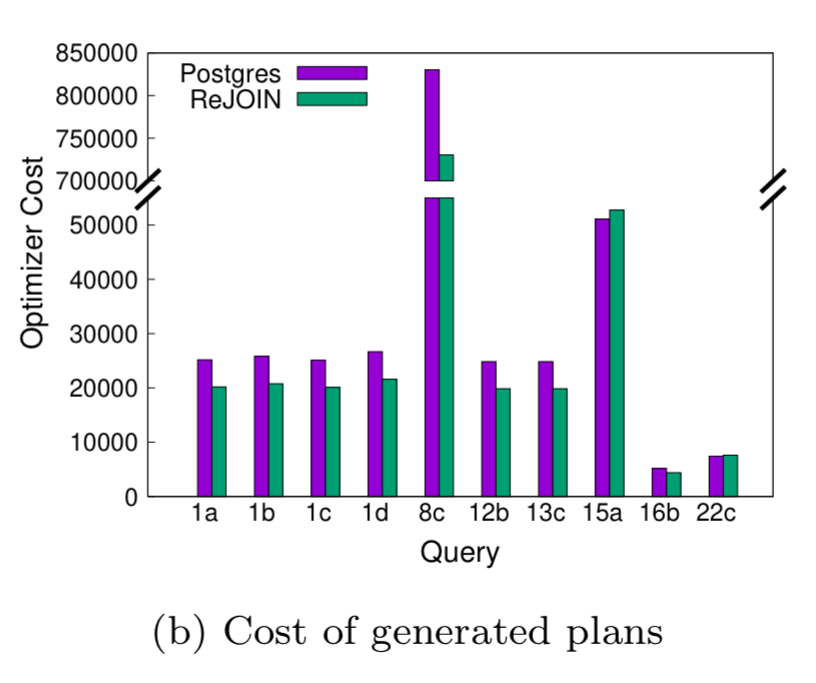
Also of note here is that after training, ReJOIN produces its query plans faster than PostgreSQL’s built-in join enumerator in many cases. The bottom-up nature of ReJOIN’s algorithm is 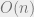
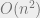
In addition to being limited to just join ordering, ReJOIN’s use of the query optimiser’s cost model to generate reward signals means that it is still dependent on a well-tuned cost model, which is a big part of the problem we wanted to solve in the first place. Ideally we’d like to extend the approach to handle full physical plan generation, and also remove the dependency on having an existing cost model.
Challenges in extending the approach
Once we go from just join ordering to the full search space including operator and access path selection etc., the approach from ReJOIN is unable to learn effective polities in reasonable time. An initial model failed to out-perform random choice even after 72 hours of training.
If we use actual query execution time to generate the reward, then initial policies which will often generate very inefficient plans will take a long time to obtain a reward signal. Thus we learn the slowest at exactly the point when we’d like to learn the fastest and the system takes a prohibitive amount of time to converge to good results. (An experiment with ReJOIN using real query latency instead of optimiser cost confirmed this).
Finally, query latency as a reward signal doesn’t meet the expectations of many DRL algorithms that the reward signal is dense and linear. A dense reward signal is one that provides incremental feedback with every action the agent takes (such as the score updating in an Atari game), not just at the end of the episode. The linear assumption means that an algorithm may attempt to maximise the sum of many small rewards within an episode.
We have identified how the large search space, delayed reward signal, and costly performance indicators provide substantial hurdles to naive applications of DRL to query optimization.
Should we just give up on the idea then? All is not lost yet! The last section of the paper details a number of alternative approaches that could overcome some of these hurdles.
Research directions
Three techniques that may help to make DRL-based query optimisation practical again are learning from demonstration, cost-model bootstrapping, and incremental learning. We’ll look at each of these briefly in turn next (there are no results from applying or evaluating these ideas as yet).
Learning from demonstration
In learning from demonstration, a model is first trained to mimic the behaviour of an existing expert, and then goes on to learn directly from its actions. In the context of query optimisation, we would first train a model to mimic the actions taken by an existing optimiser (indexes, join orderings, pruning of bad plans etc.), and then switch to optimising queries directly bypassing the ‘mentor’ optimiser. In this second phase the agent fine-tunes its own policy. The advantage of this strategy is that mimicking the existing optimiser in the early stages helps the optimiser agent to avoid the ‘obviously bad’ parts of the search space.
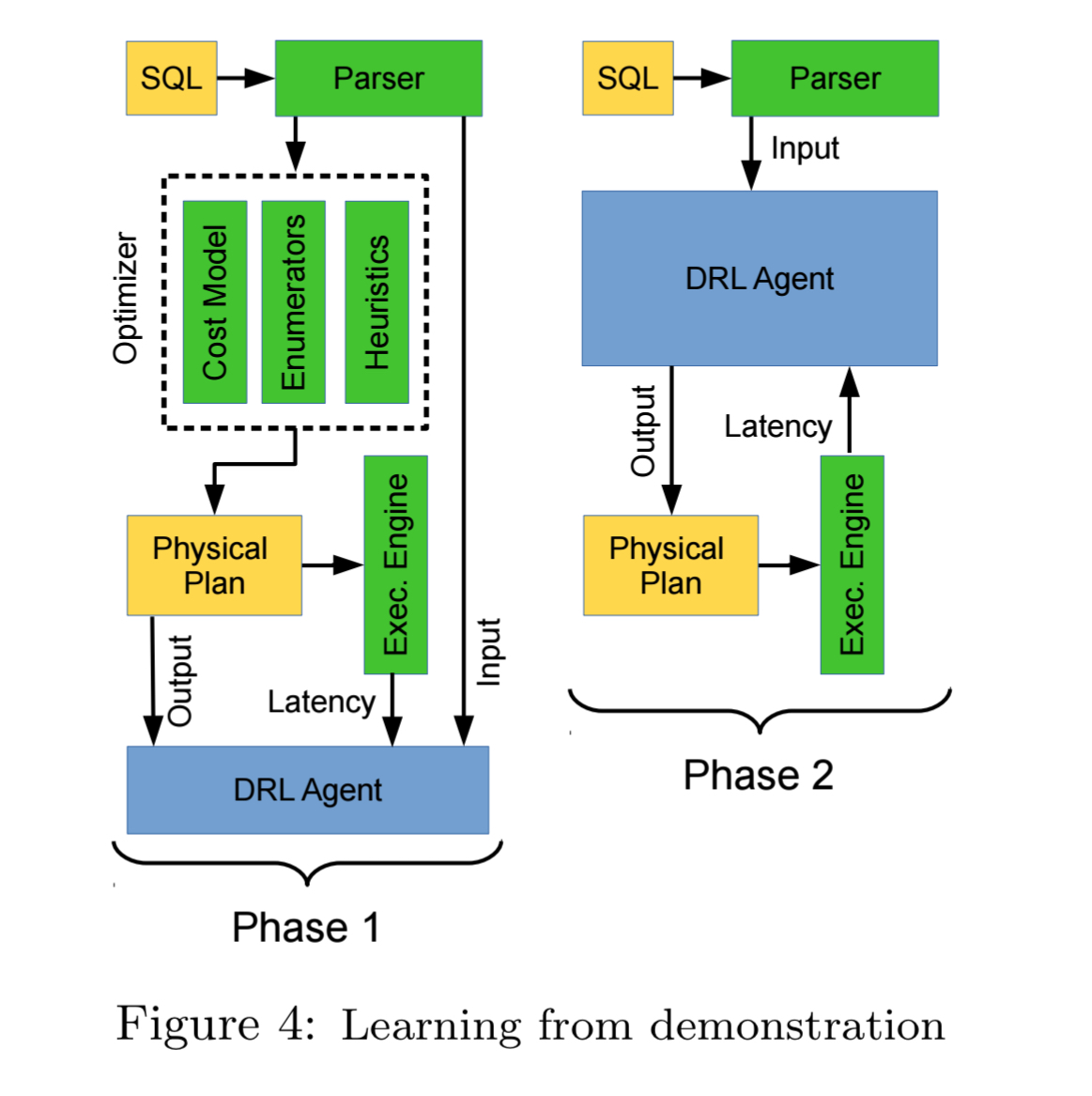
Since the behavior of the model in the second phase should not initially stray too far from the behavior of the expert system, we do not have to worry about executing any exceptionally poor query plans. Additionally, since the second training phase only needs to fine-tune an already-performant model, the delayed reward signal is of far less consequence.
Cost model bootstrapping
Cost model bootstrapping uses a very similar in spirit two-phase approach. In the first phase, instead of learning to mimic the actions of an existing expert optimiser, the judgements of the existing expert optimiser (i.e., it’s cost model) are used to bring the agent to an initial level of competence. The optimiser’s cost model is used as the reward signal during initial training, and once the agent has learned to produce good policies according to the cost model, it is then switched to learning from a reward based on actual query latency.
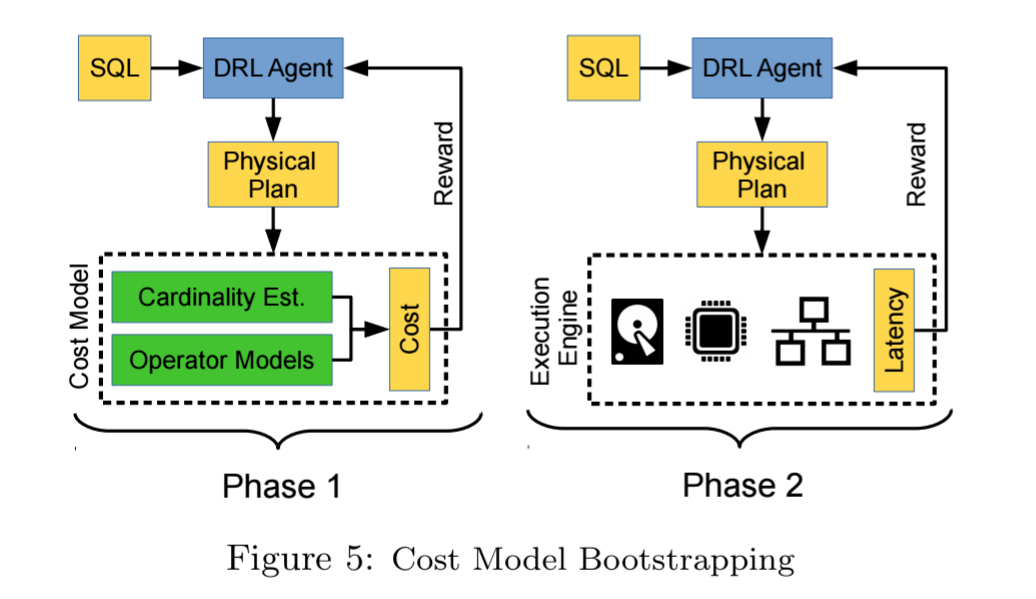
One complication is doing this is that the reward units (scale) need to be consistent across the costs produced by the query optimiser cost model, and the latency measurements of actual query executions. We could apply some kind of normalisation across the two, or alternatively transfer the weights from the first network to a new network (transfer learning).
Incremental learning
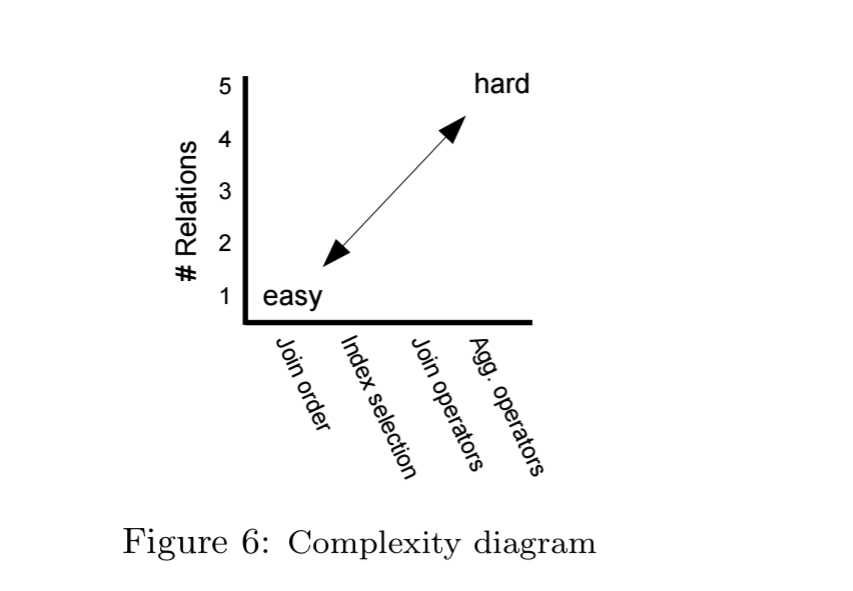
Incremental learning attempts to mitigate the issues stemming from poor query plans early in the learning cycle by beginning learning on simpler problems:
… incrementally learning query optimization by first training a model to handle simple cases and slowly introducing more complexity. This approach makes the extremely large search space more manageable by dividing it into smaller pieces.
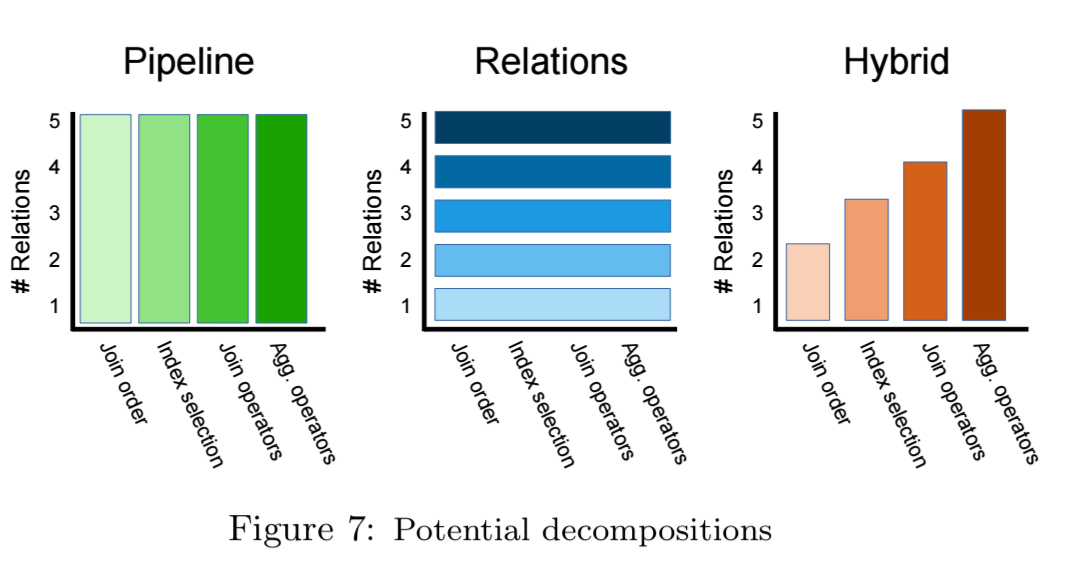
In the context of query optimisation, we can make problems easier by reducing the number of relations, or by reducing the number of dimensions to be considered. That leads to a problem space that looks like this:
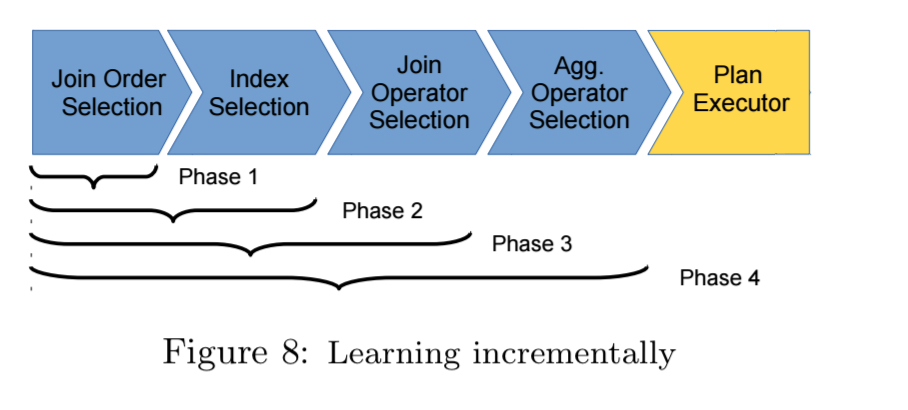
We could therefore try starting with a small number of pipeline phases and gradually introducing more, as shown in the following figure:
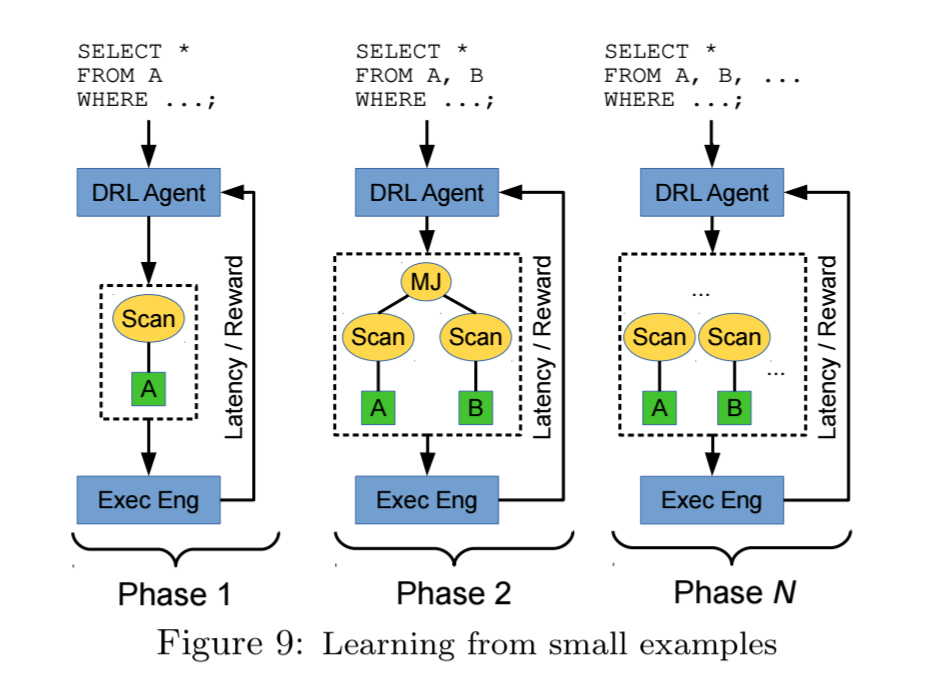
Or we could try starting with small examples and gradually focus on larger and larger queries.
Maybe a hybrid strategy will be best, starting with join order and small queries, and gradually increasing sophistication in both dimensions.

>
Excellent write-up!
if anyone is interested in the slides accompanying this paper at CIDR, they can be found here: http://rm.cab/cidr19