Debugging distributed systems with why-across-time provenance Whittaker et al., SoCC’18
This value is 17 here, and it shouldn’t be. Why did the get request return 17?
Sometimes the simplest questions can be the hardest to answer. As the opening sentence of this paper states:
Debugging distributed systems is hard.
The kind of why questions we’re interested in for this paper are questions of provenance. What are the causes of this output? Provenance has been studied in the context of relational databases and dataflow systems, but here we’re interested in general distributed systems. (Strictly, those where the behaviour of each node can be modelled by a deterministic state machine: non-deterministic behaviour is left to future work).
Why why-provenance doesn’t work
Relational databases have why-provenance, which sounds on the surface exactly like what we’re looking for.
Given a relational database, a query issued against the database, and a tuple in the output of the query, why-provenance explains why the output tuple was produced. That is, why -provenance produces the input tuples that, if passed through the relational operators of the query, would produce the output tuple in question.
One reason that won’t work in our distributed systems setting is that the state of the system is not relational, and the operations can be much more complex and arbitrary than the well-defined set of relational operators why-provenance works with.
There’s a second, deeper reason why why-provenance doesn’t work here as well:
Why-provenance makes the critical assumption that the underlying relational database is static. It cannot handle the time-varying nature of stateful distributed systems.
Why causal history buries the cause
We do have one tool in our distributed systems toolbox that can handle this issue of the state changing over time. Indeed, was designed explicitly to handle potential causes: the happens-before relationship and the notion of causality. The difficulty here is that the causal history of an event is a crude over-approximation, encompassing everything that was seen before. It tells us which events could potentially have contributed to the cause, but not which ones actually did. That can be a lot of extraneous noise to deal with when trying to debug a distributed system.
Wat should we do instead?
… causality lacks a notion of data dependence, and data provenance lacks a notion of time. In this paper, we present wat-provenance (why-across-time provenance): a novel form of data provenance that unifies ideas from the two. Wat-provenance generalizes the why-provenance from the domain of relational queries issued against a static database to the domain of arbitrary time-varying state machines in a distributed system.
Consider a server in a distributed system as a deterministic state machine that repeatedly receives requests, updates its state accordingly, and sends replies. Wat-provenance is defined in terms of the traces of such a system.
- The trace T of a system is the ordered sequence of inputs received by the state machine
- A subtrace T’ of T is an order-preserving sub-sequence of T (but the events in the sub-sequence don’t have to be contiguous).
- Given a subtrace T’ of T, then a supertrace of T’ is a substrace of T containing every element of T’.
For example:

Wat-provenance aims to formalize an intuitive notion of why the state machine M produces output o when given input i.
Since the state machines are deterministic, we can start with the notion that the cause of some output o must be contained in a subtrace of the input. E.g. if we have a KVS node with trace T = set(x,1);set(y,2) and a request i = get(x) then the subtrace T’ =set(x,1) is sufficient to explain the output 1. Such a subtrace is called a witness of o.
In this particular example, both T and T’ are witnesses of o, but note that T contains some additional inputs (set(y,2)) that are not needed to explain the output. So we’d like a minimal subtrace.
If we’re not careful about what we leave out though, we can end up creating false witnesses. Consider a server maintaining a set of boolean-valued variables all initialised to false. We have a trace T = set(a); set(b); set(c) and a request i producing output (a && !b) || c. The reason this outputs true is that c is true. So set(c) is a genuine witness. But if we considered just the subtrace set(a) (so we’re in the state a= true, b = c = false) then set(a) would also appear to be a witness, even though it isn’t. To avoid false witnesses, we add the rule that every supertrace of T’ in T must also be a witness of o. In such an instance we say that the witness T’ of o is closed under supertrace in T. Since the supertrace set(a);set(b); is not a witness of o, we exclude the subtrace set(a) through this rule.
Sticking with the boolean server, suppose we have a simpler scenario where i produces an output o equal to (a && d) || (b && c). In this case a trace T = set(a);set(b);set(c);set(d) contains two subtraces that can both be a cause of the true output: set(a);set(d) and set(b);set(c). Thus we notice that the cause of an output can be a set of witnesses.
And so we arrive at:
[wat-provenance] consists of every witness T’ of o such that (1) T’ is closed under supertrace in T, and (2) no proper subtrace of T’ is also a witness of o that satisfies (1).
When computing wat-provenance, it’s important that we first compute the set of witnesses closed under supertrace in T, and only then remove the non-minimal elements. If you try to remove non-minimal elements first it’s possible to over-prune. (See the worked example in §3.5 of the paper).
Wat-provenance refines causality, and subsumes why-provenance.
Black box, simple interface
Automatically computing the wat-provenance for an arbitrary distributed system component, which we dub a black box, is often intractable and sometimes impossible…. (But) … we can take advantage of the fact that many real-world black boxes are far from arbitrary. Many black boxes have complex implementations but are designed with very simple interfaces.
Instead of trying to infer wat-provenance by inspecting an implementation, we can specify it directly from an interface. A wat-provenance specification is a function that given a trace T and a request i, returns the wat-provenance Wat(M, T, i) for a black box modeled as state machine M.
For example, for Redis (~50K LOC) the wat-provenance specification for a get request to a key just needs to consider the most recent set to that key, and all subsequent modifying operations (e.g. incr, derc). It takes surprisingly few lines of code to write these wat-provenance specifications for interesting subsets of real-world systems:

Not every system is so amenable though. The authors give as an example a state machine implementing some machine learning model whereby clients can either submit training data (for online model updating) or submit an input for classification. Here a wat-provenance specification would likely be just as complex as the system itself.
Watermelon
Watermelon is a prototype debugging framework using wat-provenance and wat-provenance specifications. It acts as a proxy intercepting all communication with the service and recording traces in a relational database. When messages are sent between Watermelon’d processes, Watermelon can connect the send and the receive such that multiple black boxes can be integrated into the same Watermelon system.
With the proxy shim in place, a developer can write wat-provenance specifications either in SQL or in Python.
To find the cause of a particular black box output, we invoke the black box’s wat-provenance specification. The specification returns the set of witnesses that cause the output. Then, we can trace a request in a witness back to the black box that sent it and repeat the process, invoking the sender’s wat-provenance specification to get a new set of witnesses.
Evaluation
The evaluation is currently the weakest part of the paper. Wat-provenance specifications are written for 20 real-world APIs across Redis, the POSIX file system, Amazon S3, and Zookeeper (see table 1 above). Debugging ease is then qualitatively evaluated against using printf statements and against SPADE (a framework for collecting provenance information from a variety of sources including OS audit logs, network artifacts, LLVM instrumentation, and so on). This leads to the following table:
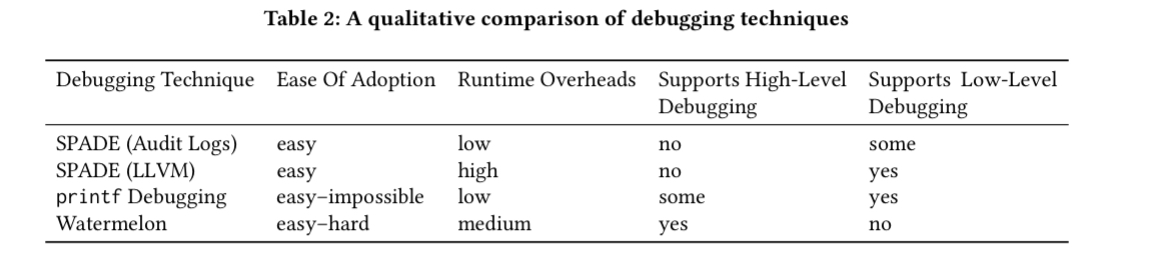
What it would be lovely to see is an evaluation of using wat-provenance to debug real-world problems. Future work perhaps?
Wat-logs
A final thought from me is that rather than a proxy, it’s pretty common (and not unreasonable a request if not) for a server process to log incoming requests and their responses. In which case given a suitable logging system it ought to be possible to ask wat-provenance questions directly of the logs. That would fit quite well with existing troubleshooting workflows that often start with something that doesn’t look quite right in the logs and explore why that is from there.

Seems to me as an outsider that there’s a race going on between developments in analytic automated sense-making (like this) and in associative automated sense-making (like ML). Which makes me wonder, has anyone written anything interesting about the relationship between the two of them?
Hi Francis. What is “ML” short for in this context?