Unikernels as processes Williams et al., SoCC’18
Ah, unikernels. Small size, fast booting, tiny attack surface, resource efficient, hard to deploy on existing cloud platforms, and undebuggable in production. There’s no shortage of strong claims on both sides of the fence.
See for example:
- Unikernels: library operating systems for the cloud
- Jitsu: just-in-time summoning of unikernels
- IncludeOS: A minimal, resource efficient unikernel for cloud systems,
- My VM is lighter (and safer) than your container, and
- Unikernels are unfit for production
In today’s paper choice, Williams et al. give us an intriguing new option in the design space: running unikernels as processes. Yes, that’s initially confusing to get your head around! That means you still have a full-fat OS underneath the process, and you don’t get to take advantage of the strong isolation afforded by VMs. But through a clever use of seccomp, unikernels as processes still have strong isolation as well as increased throughput, reduced startup time, and increased memory density. Most importantly though, with unikernels as processes we can reuse standard infrastructure and tools:
We believe that running unikernels as processes is an important step towards running them in production, because, as processes, they can reuse lighter-weight process or container tooling, be debugged with standard process debugging tools, and run in already virtualized infrastructure.
So instead of a battle between containers and unikernels, we might be able to run unikernels inside containers!
Unikernels today
Unikernels consist of an application linked against just those parts of a library OS that it needs to run directly on top of a virtual hardware abstraction. Thus they appear as VMs to the underlying infrastructure.
In the case of Linux and KVM, the ukvm monitor process handles the running of unikernels on top of KVM. (Like a version of QEMU, but specialised for unikernels). The ukvm monitor is used by several unikernel ecosystem including MirageOS, IncludeOS, and Rumprun.
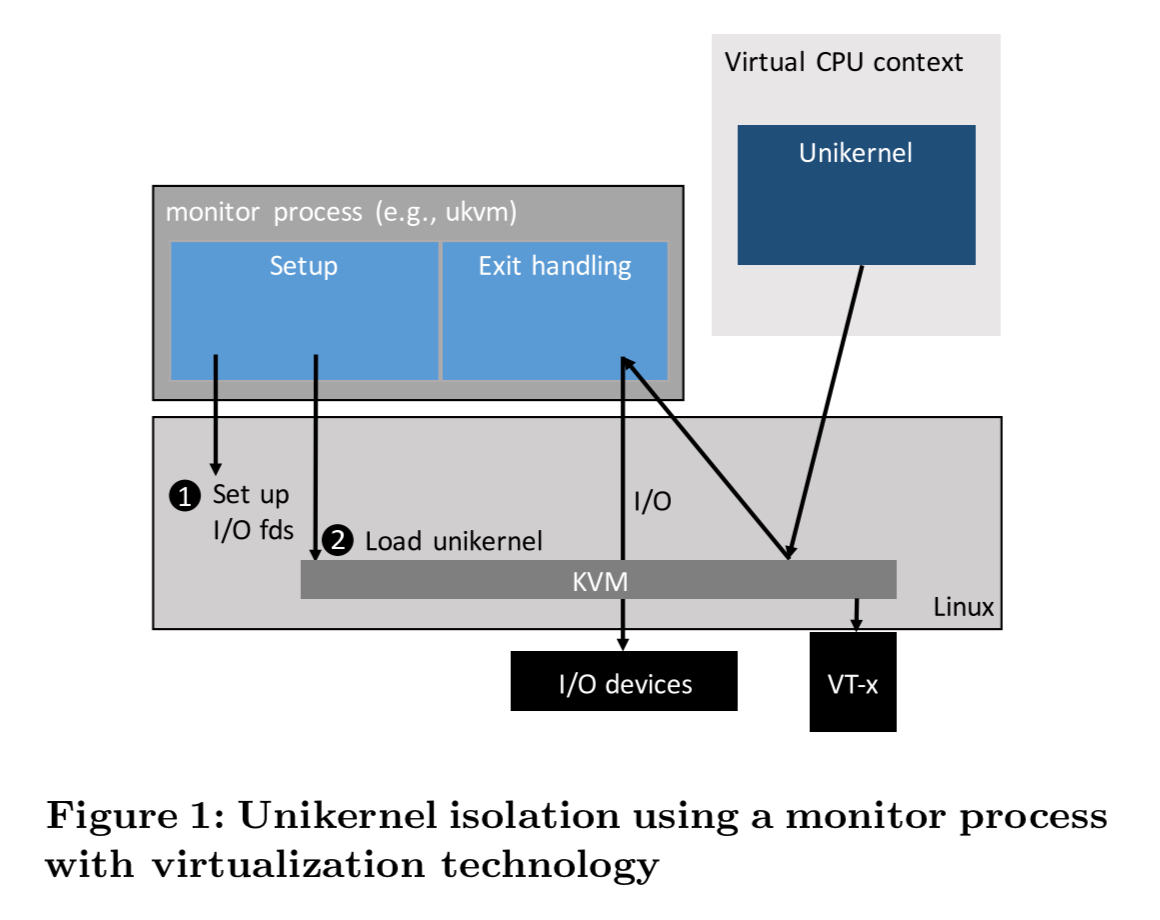
The userspace ukvm monitor process handles setup (e.g. allocating memory and virtual CPU, opening file descriptors) and exit. During execution, the unikernel exits to the monitor via hypercalls, usually to perform I/O.
When using virtualization technology, isolation is derived from the interface between the unikernel and the monitor process. This interface is this: the unikernel can exit to ukvm via at most 10 hypercalls.
The argument for enhanced security (isolation) comes from the narrowness of this interface. If an attacker did break through the interface into the monitor process, then of course they would then be able to launch attacks across the entire Linux system call interface. For comparison, Linux has over 300 system calls, and Xen has about 20 hypercalls.
Unikernels as described above have some drawbacks though: there is no guest OS, so no familiar debugging tools. Memory density can suffer as all guests typically perform file caching independently; and every hypercall involves a context switch, doubling the cycles consumed compared to a direct function call. Finally, when an existing infrastructure-as-a-service offering is used as a base on which to build higher-level offerings (e.g. serverless platforms), then unikernels can’t be deployed without nested virtualisation, which is itself difficult and often not supported.
Unikernels as processes
When using a unikernel monitor as described above, unikernels are already very similar to applications.
A running unikernel is conceptually a single process that runs the same code for its lifetime, so there is no need for it to manage page tables after setup. Unikernels use cooperative scheduling and event loops with a blocking call like
pollto the underlying system for asynchronous I/O, so they do not even need to install interrupt handlers (nor use interrupts for I/O).
If we think of a unikernel in this way as a specialised application processes, then maybe we can get the same narrow interface afforded by the exposed hypercalls of ukvm in some other way….
Many modern operating systems have a notion of system call whitelisting allowing processes to transition into a mode with a more restricted system call interface available to them. For example, Linux has
seccomp.
The traditional difficulty with seccomp is figuring out the set of system calls that should be allowed. E.g., Docker runs containers under a default policy that allows them to perform more than 250 system calls. When we have a unikernel as our process though, we can lock the set of calls right down.
So that’s how unikernels as processes work. In place of the ukvm monitor there’s a component the authors call a tender. The tender is responsible for setup and exit handling as the ukvm monitor is. However, once file descriptors etc. are setup, the tender dynamically loads the unikernel code into it’s own address space. Then it configures seccomp filters to only allow system calls corresponding to the unikernel exits for I/O, and makes a one-way transition to this new mode. Finally it calls the entry point of the loaded unikernel.
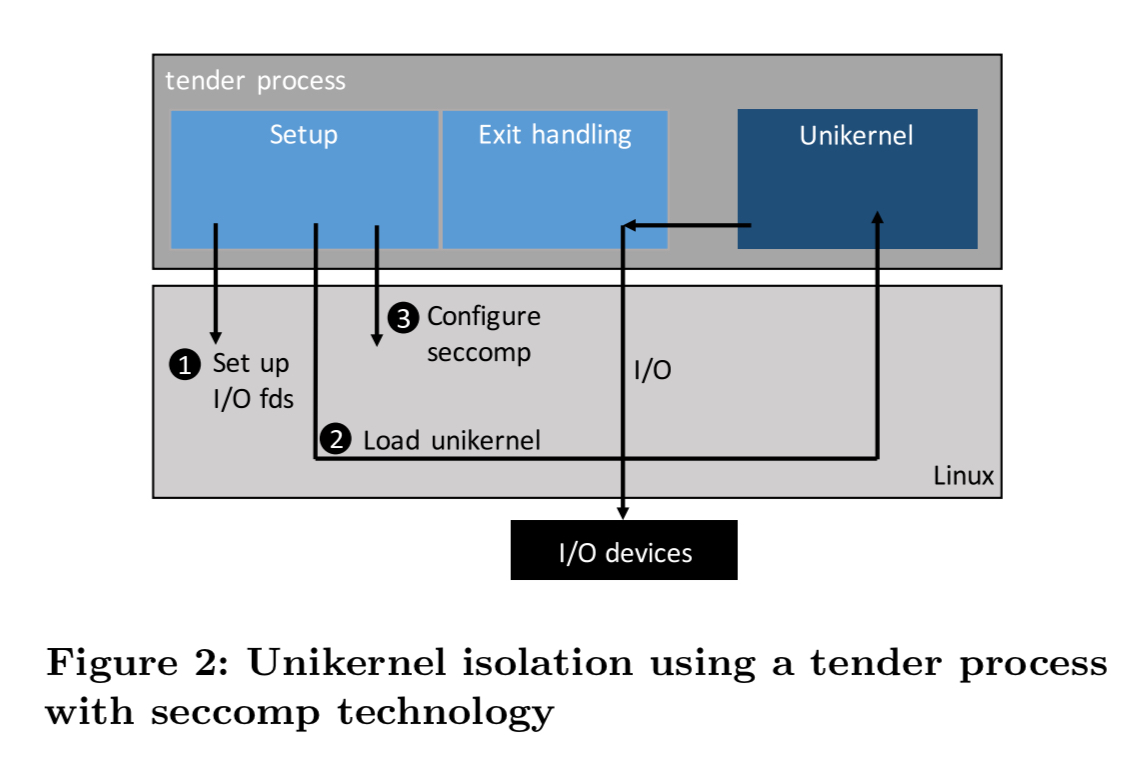
… the unikernel executes as usual, but instead of invoking hypercalls when necessary, the unikernel simply does a normal procedure call to the hypercall implementation in the tender. The hypercall implementation in the tender is identical to the monitor implementation in the virtualization case; the tender will likely perform a system call to Linux, then return the result to the unikernel.
The table below shows the mapping from hypercalls to system calls for ukvm-based unikernels.

Isolation properties come from the interface between the tender and the host, since the tender becomes the unikernel when it first jumps to guest code. Seccomp filters allow the tender to specify file descriptor associations at setup time, and other checks such as constraints on the arguments to blkwrite can also be specified.
We therefore consider unikernels as processes to exhibit an equal degree of isolation to unikernels as VMs.
By being processes, unikernels as processes can also take advantage of ASLR, common debugging tools, memory sharing, and architecture independence for free.
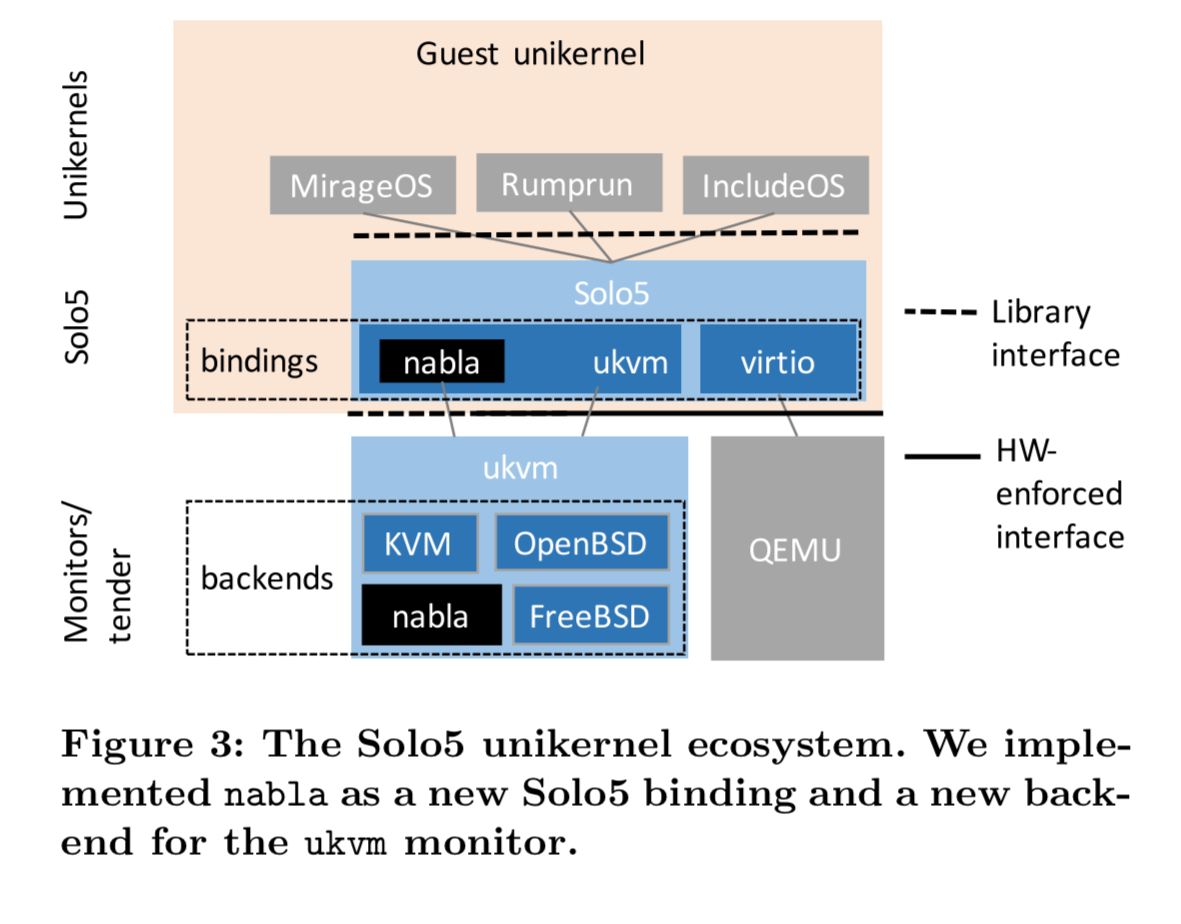
Introducing nabla
Solo5 provides a unikernel base layer upon which various library OSes run such as MirageOS, IncludeOS, and Rumprun. ukvm is distributed with Solo5. The authors extend Solo5 and ukvm by adding a new backend to ukvm enabling it to operate as a tender, and changing the Solo5 ukvm binding to eliminate some hardware specific setup and use a function call mechanism rather than a hypercall mechanism to access the tender. The resulting prototype system is called nabla. With that, we’re good to go…
Evaluation
Using a variety of workloads, the authors explore the isolation and performance characteristics of nabla. The evaluation compares unikernels running under ukvm, nabla, and vanilla processes.
Nabla runs the systems using 8-14 times fewer system calls than the corresponding native process:
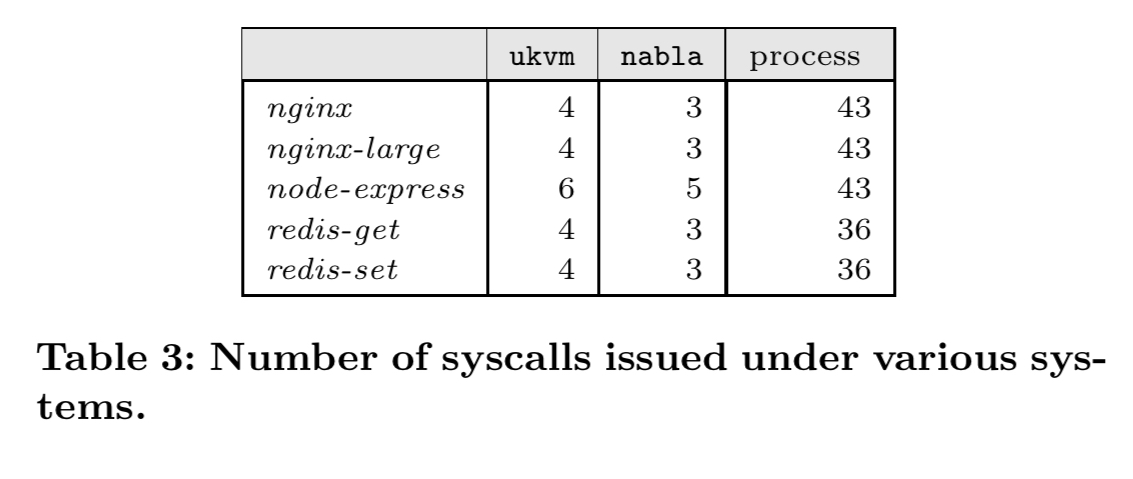
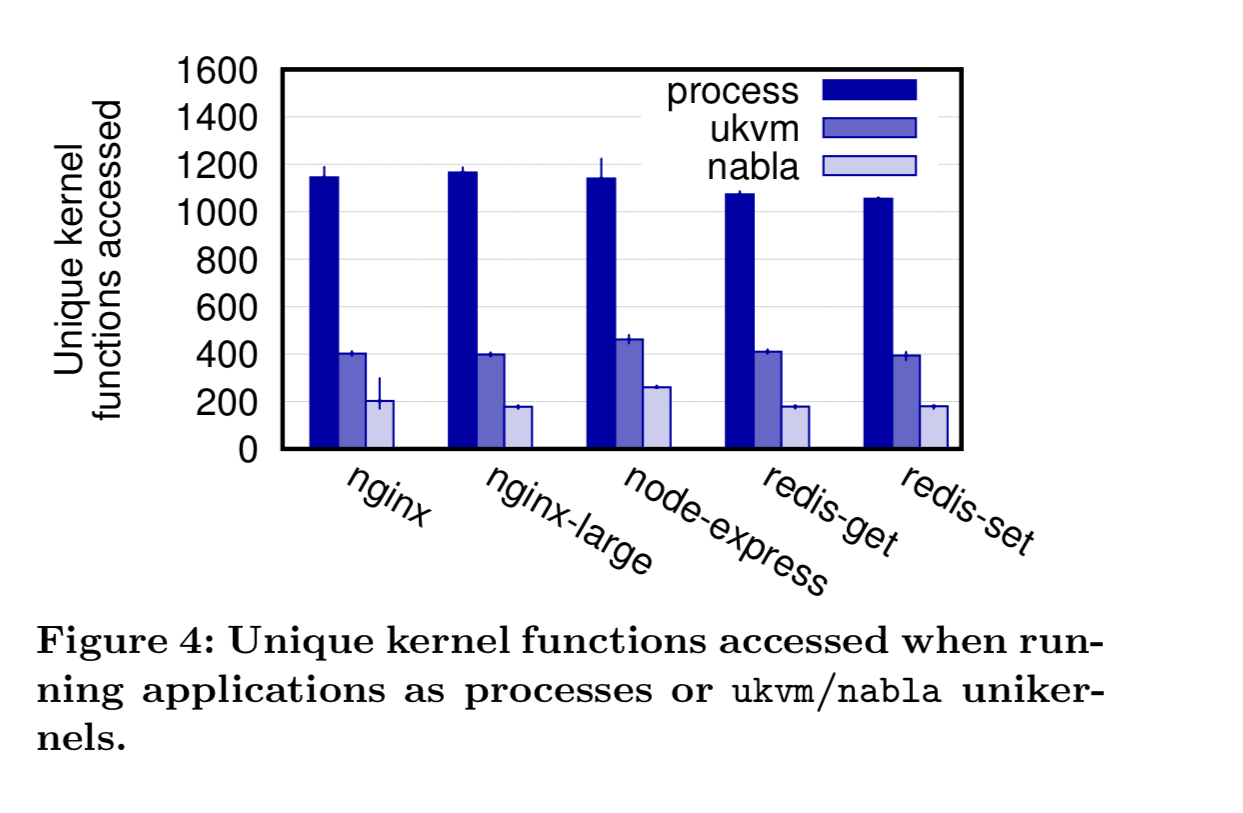
It also accesses about half of the number of kernel functions accessed by ukvm unikernels (mostly due to nabla avoiding virtualization related functions).
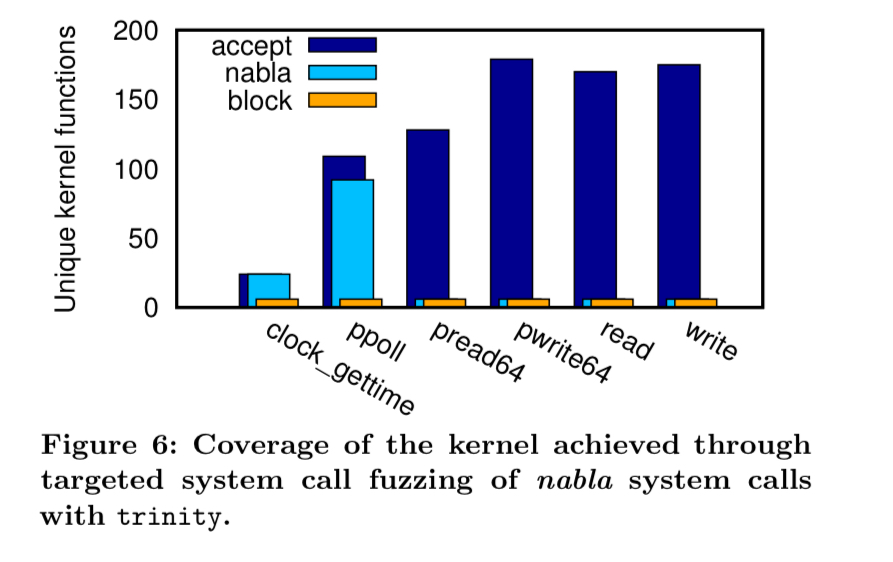
Using a fuzzer, the authors also explored how much of the underlying kernel is reachable through the nabla interface. Compared to a seccomp policy that accepts everything, nabla reduces the amount of kernel function accessible by 98%.
Nabla also achieves higher throughput than ukvm in all cases:
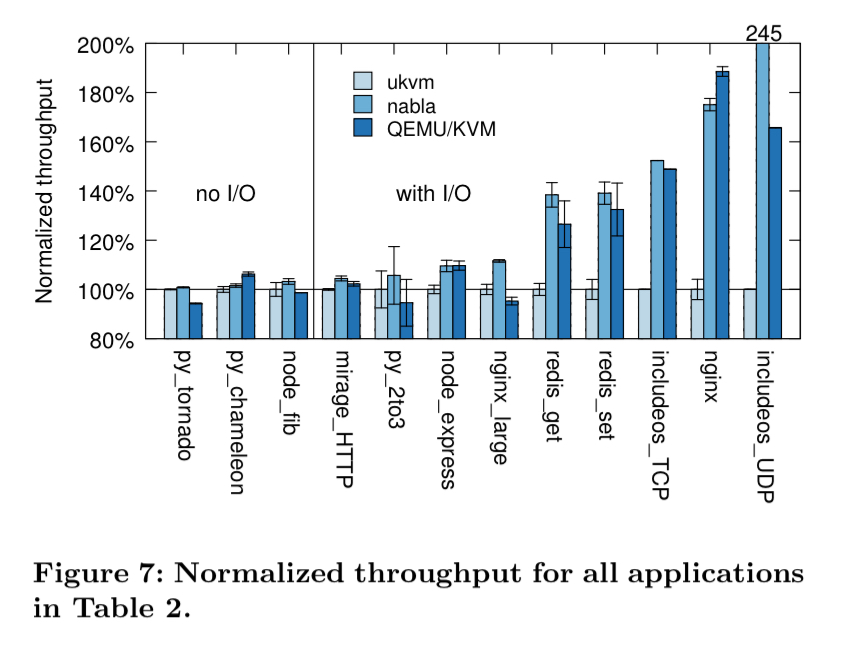
Running unikernels as processes increases throughput by up to 245%, reduces startup times by up to 73%, and increases memory density by 20%. It all adds up to an exciting new set of options for unikernel projects and deployments.
The last word
In this paper, we have shown that running unikernels as processes can improve isolation over VMs, cutting their access to kernel functions in half. At the same time, running unikernels as processes moves them into the mainstream; unikernels as process inherent many process-specific characteristics— including high memory density, performance, startup time, etc— and tooling that were previously thought to be necessary sacrifices for isolation. Going forward, we believe this work provides insight into how to more generally architect processes and containers to be isolated in the cloud.

One thought on “Unikernels as processes”
Comments are closed.