DeepTest: automated testing of deep-neural-network-driven autonomous cars Tian et al., ICSE’18
How do you test a DNN? We’ve seen plenty of examples of adversarial attacks in previous editions of The Morning Paper, but you couldn’t really say that generating adversarial images is enough to give you confidence in the overall behaviour of a model under all operating conditions. Adversarial images approach things from a ‘think like an attacker’ mindset. We want to ‘think like a tester.’ For example, the work on DeepXplore which uses model ensembles to find differences in outputs that suggest bugs. The importance of testing DNNs is especially obvious when it comes to applications such as autonomous driving. Several of the ideas from DeepXplore are used in DeepTest, which looks specifically at testing of autonomous driving system. I think you could apply the DeepTest techniques to test other kinds of DNNs as well.
…despite the tremendous progress, just like traditional software, DNN-based software, including the ones used for autonomous driving, often demonstrate incorrect/unexpected corner-case behaviours that lead to dangerous consequences like a fatal collision.
DeepTest is a system designed to aid in the testing of autonomous driving models. When used to test three of top performing DNNs from the Udacity self-driving car challenge, it unearthed thousands of erroneous behaviours, many of which could lead to potentially fatal crashes.
Testing challenges in autonomous driving
We’re interested in testing the Deep Neural Network(s) at the core of an autonomous driving system. These take inputs from a variety of sensors, and actuate car systems such as steering, braking, and accelerating.
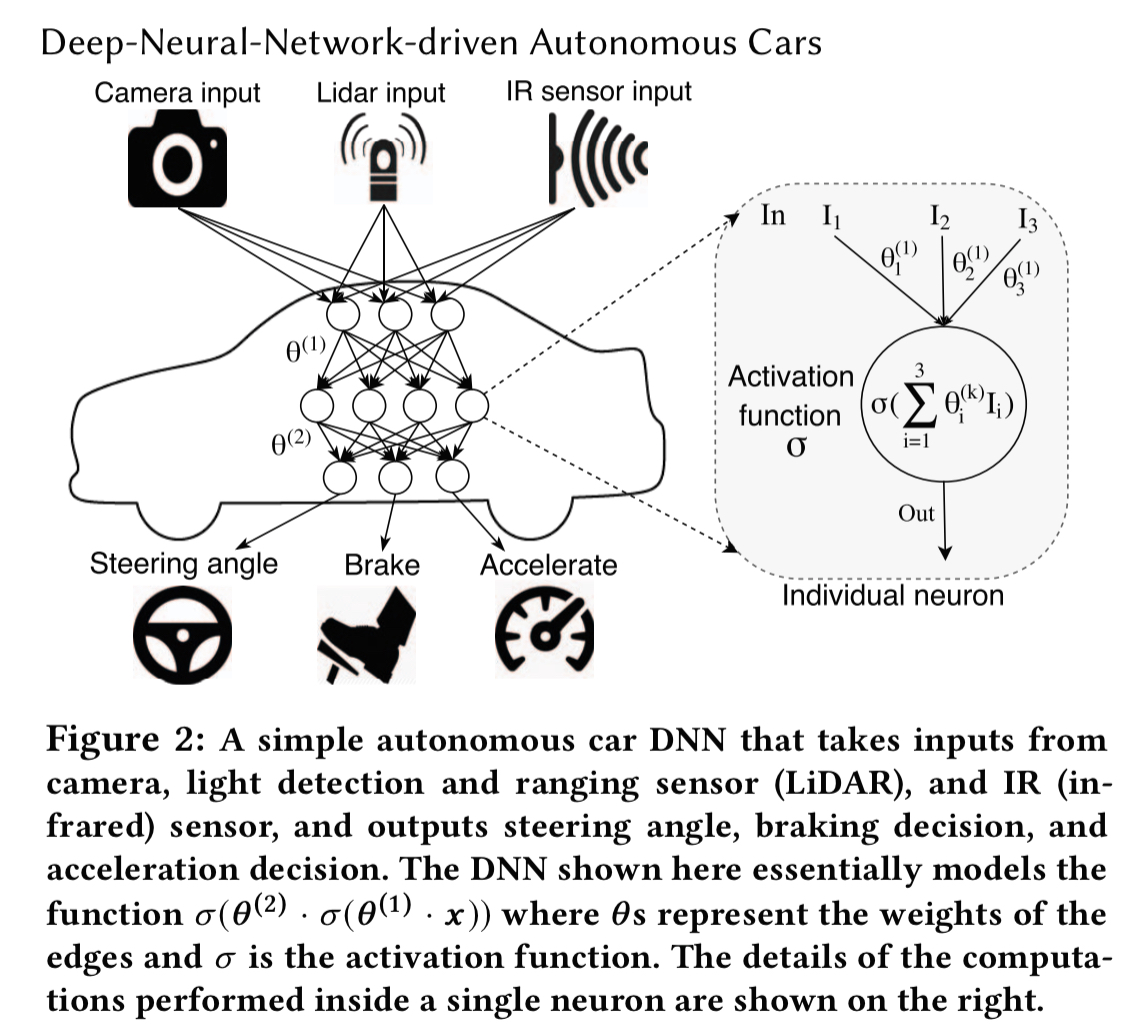
This paper focuses on the camera input and the steering angle output. We can’t apply traditional measures such as statement coverage to understand how well tested a DNN is, so we need to find an alternate metric. Borrowing from DeepXplore, DeepTest uses a notion of neuron coverage. Another interesting challenge is how you know whether the output of the model is correct in any given scenario. DeepXplore introduced the notion of using an ensemble of models to detect models making unusual predictions for a given input. DeepTest has a neat twist on this, using an ensemble of inputs which should all lead to the same output (e.g. the same road in different weather and visibility conditions) to detect erroneous outputs.
How do you measure test coverage?
The input-output space (i.e., all possible combinations of inputs and outputs) of a complex system like an autonomous vehicle is too large for exhaustive exploration. Therefore, we must devise a systematic way of partitioning the space into different equivalence classes by picking one sample from each of them. In this paper, we leverage neuron coverage as a mechanism for partitioning the input space based on the assumption that all inputs that have similar neuron coverage are part of the same equivalence class (i.e., the target DNN behaves similarly for these inputs).
Neuron coverage is simply the fraction of neurons that are activated across all test inputs. Since all neurons eventually contribute to the output, if we maximise neuron coverage we should also be maximising output diversity. For RNN/LSTM models that incorporate loops, intermediate neurons are unrolled to produce a sequence of outputs, with each neuron in an unrolled layer treated as a separate individual neuron for the purpose of coverage computation.
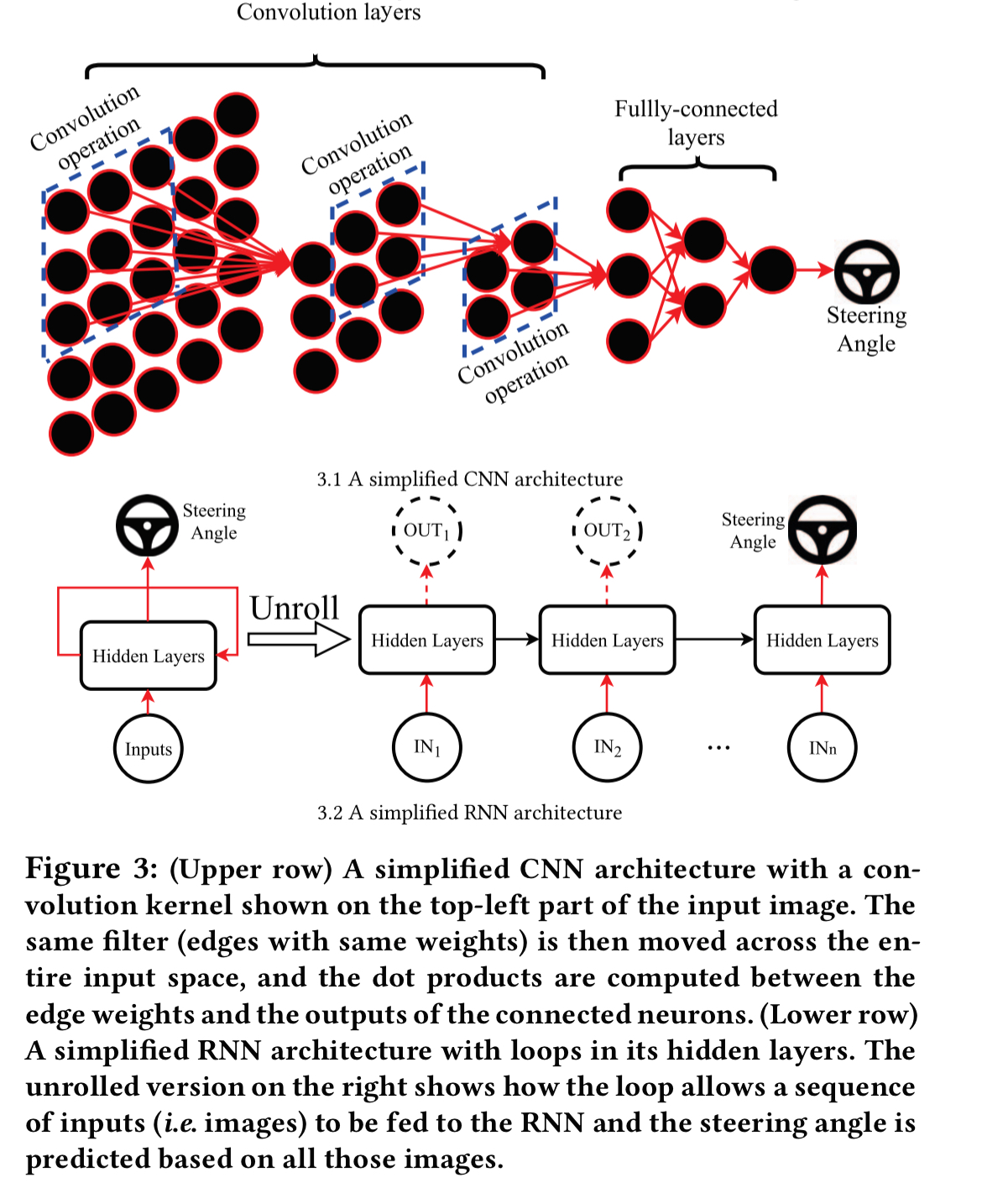
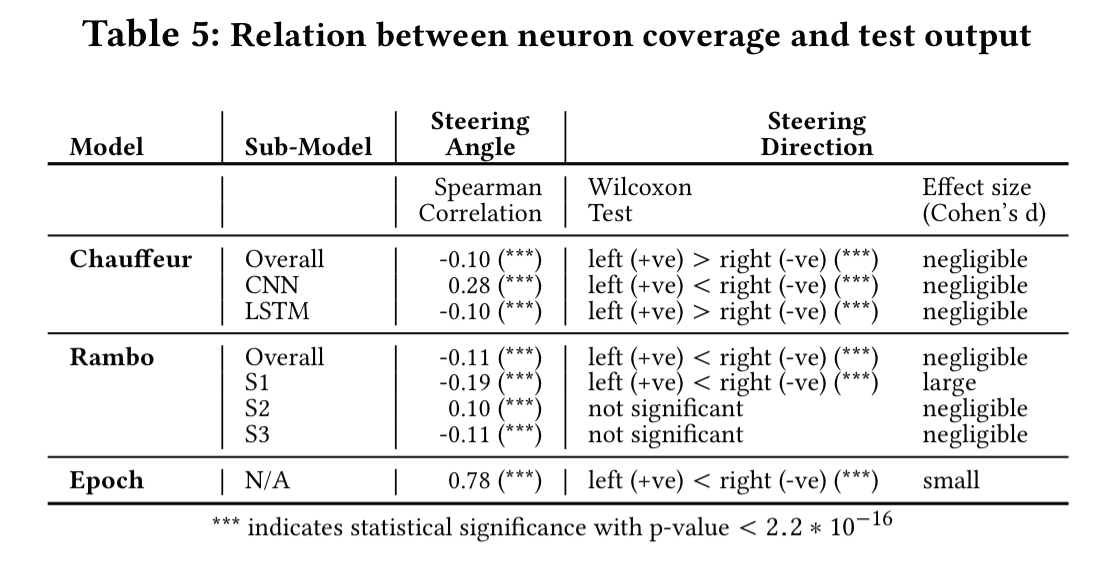
To see whether neuron coverage really is a useful metric in practice, experiments are done with three different DNNs:

The models are fed a variety of inputs, and the neuron coverage, steering angle, and steering direction (left or right) outputs are recorded. Spearman rank correlation shows a statistically significant correlation between neuron coverage and steering angle outputs. Different neurons get activated for different outputs, indicating neuron coverage is a a good approximation for testing input-output diversity. Steering direction also correlates with neuron coverage.
How can you systematically improve test coverage?
As testers, our goal is to improve the neuron coverage. But how? Synthetic inputs are of limited use, so DeepTest borrows a trick often used to increase diversity in training sets: it applies image transformations to seed images to generate new inputs.
… we investigate nine different realistic image transformations (changing brightness, changing contrast, translation, scaling, horizontal shearing, rotation, blurring, fog effect, and rain effect). These transformations can be classified into three groups: linear, affine, and convolutional.
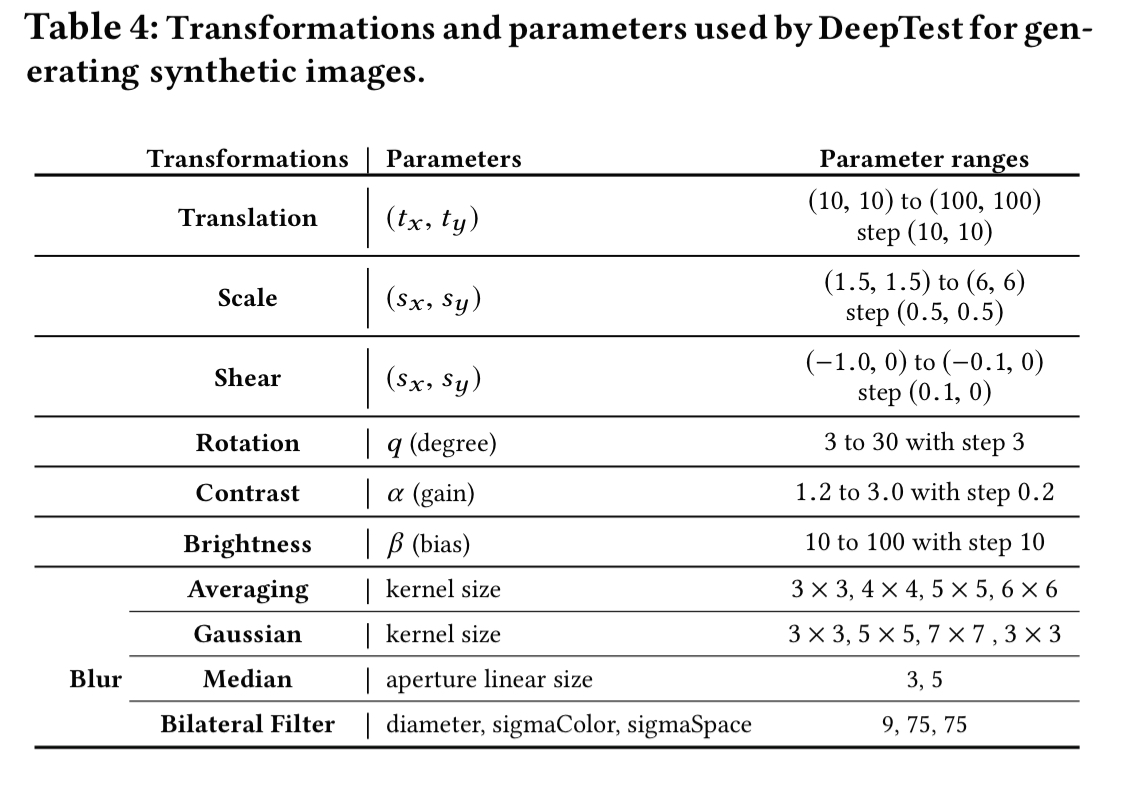
Starting with 1000 input images, and applying seventy transformations to each (taken from the core set of transformations, but with varying parameters), a set of 70,000 synthetic images are generated. The results show that transforming an image does indeed improve neuron coverage:
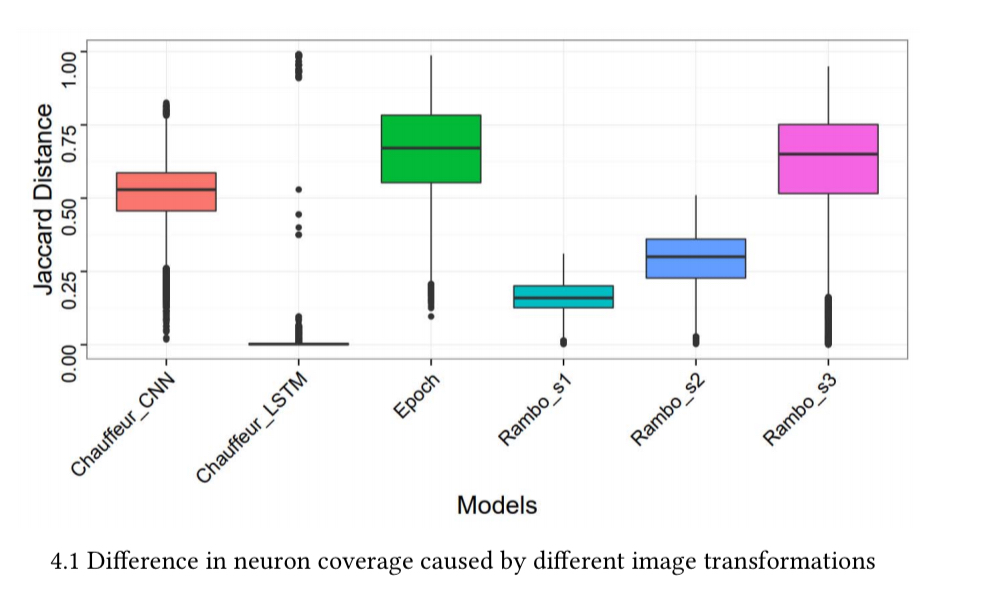
And here’s the drill-down by transformation type:
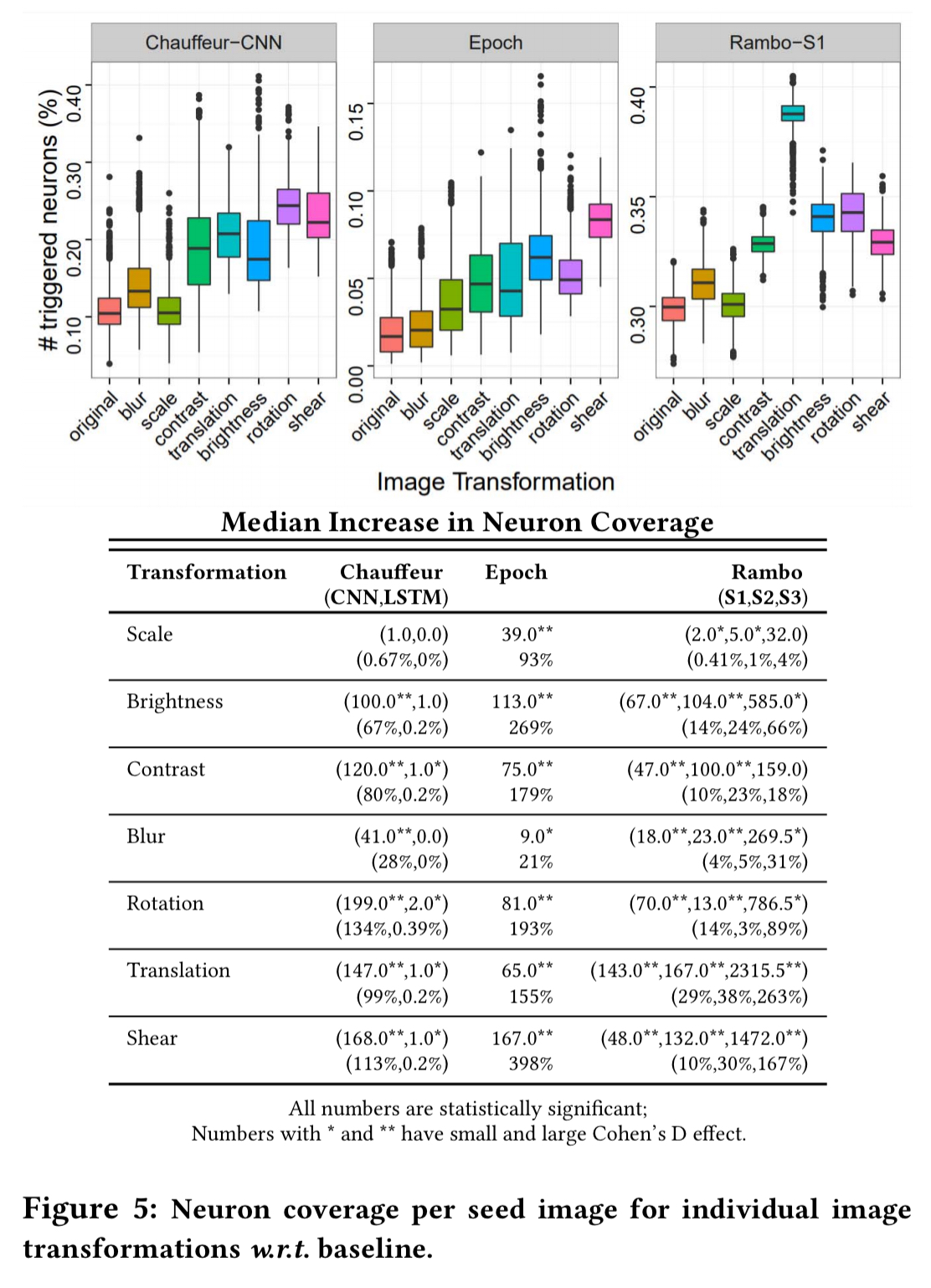
If one transformation is good, what about applying multiple transformations at the same time to generate a synthetic image? The following chart shows the effect on neuron coverage as we successively apply a sequence transformations to a given seed image. The results indicate that different image transformations tend to activate different sets of neurons.
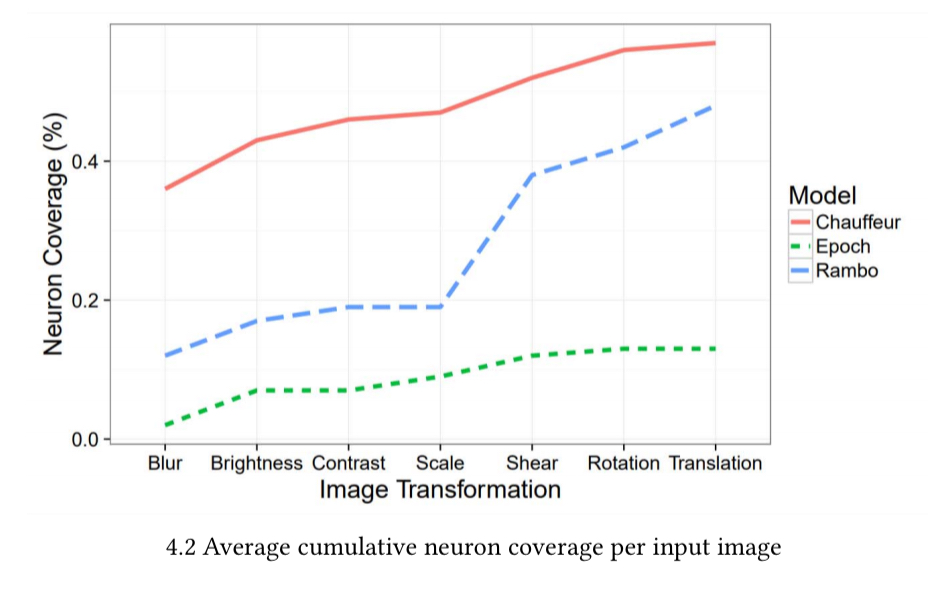
Our results demonstrate that different image transformations can be stacked together to further increase neuron coverage. However, the state space of all possible combinations of different transformations is too large to explore exhaustively. We provide a neuron-coverage-guided greedy search technique for efficiently finding combinations of image transformation that result in higher coverage.

The algorithm keeps track of transformations that successfully increase neuron coverage for a given image, and priortises those transformations while generating more synthetic images.
These guided transformations increase coverage across all models, as shown in the following table. Rambo S-3 doesn’t improve very much, but note that is was on 98% coverage to start with!
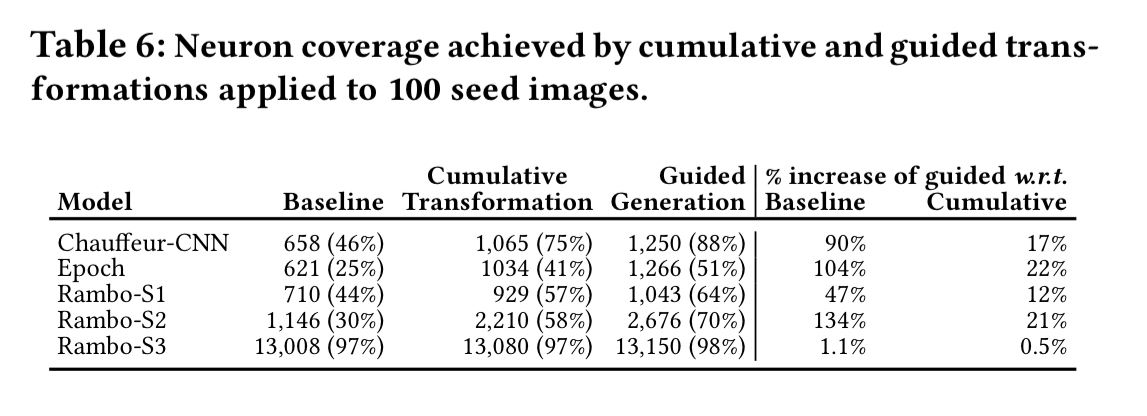
How do you know whether a model output is correct?
We know how to generate inputs that will increase neuron coverage. But how do we know whether or not those inputs reveal a flaw in the network?
The key insight is that even though it is hard to specify the correct behavior of a self-driving car for every transformed image, one can define relationships between the car’s behavior’s across certain types of transformations.
If we change weather or lighting conditions, blur the image, or apply affine transformations with small parameters values (metamorphic relations), we don’t expect the steering angle to change significantly. There is a configurable parameter λ that specifies the acceptable deviation from the original image set results, based on mean-squared-error versus labelled images in the training set.
As we can see in the figure below, the transformed images produce higher error rates – i.e., they are diverging from the non-transformed output behaviours.
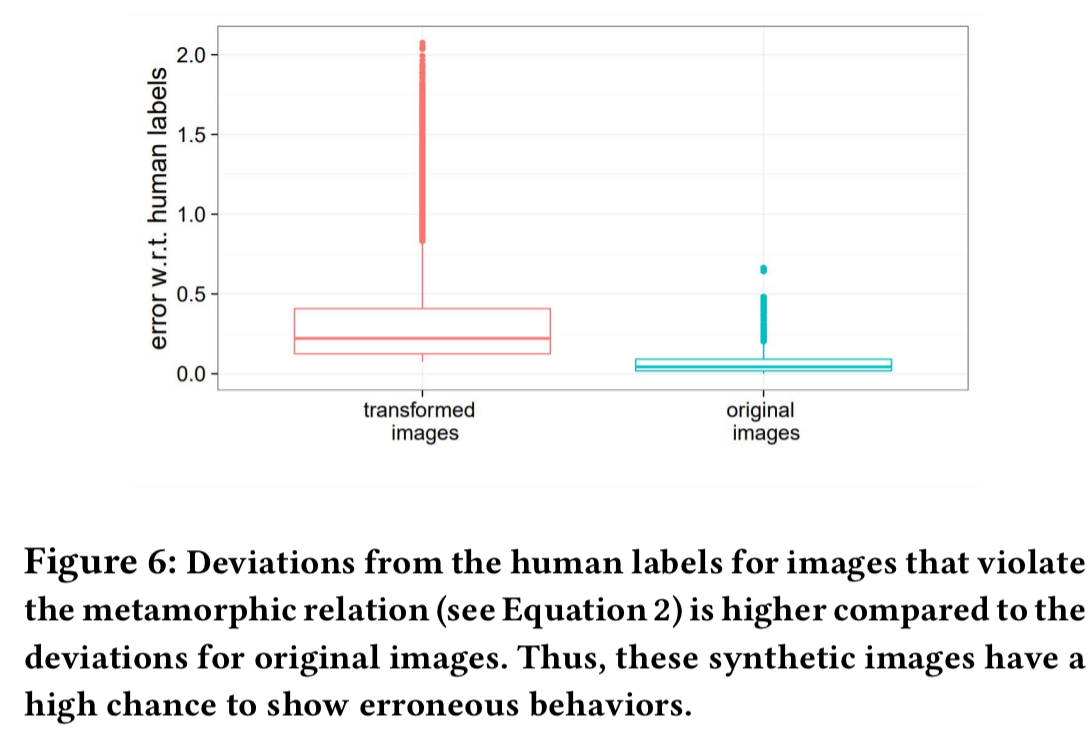
Results from testing autonomous driving DNNs
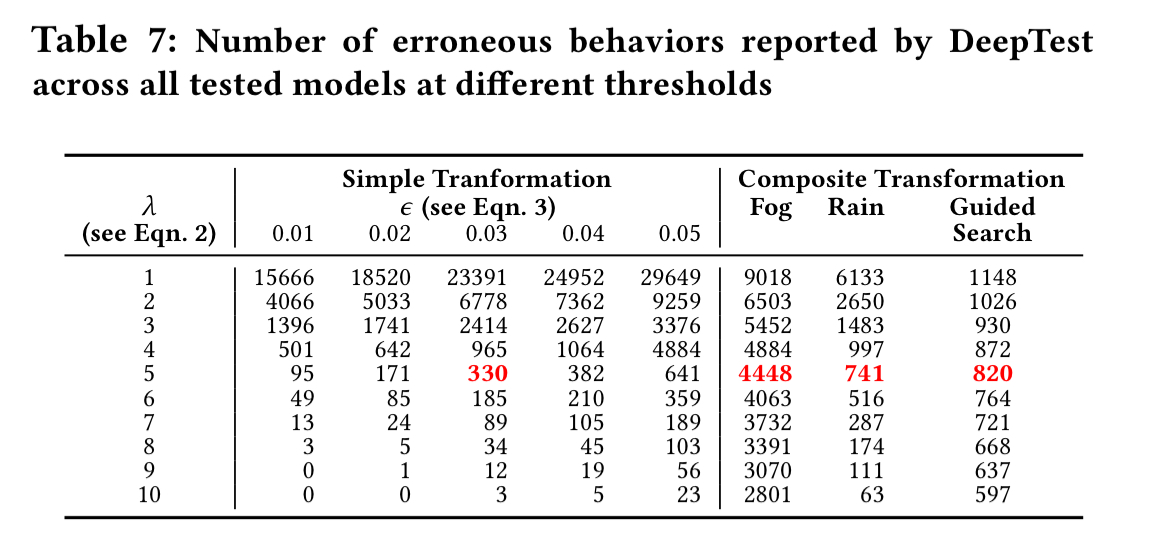
Using this metamorphic-relation-based test, we can look for differences in model outputs caused by the transformations. DeepTest is able to find quite a lot of them!
Here are some sample images from the failing tests. You can see more at https://deeplearningtest.github.io/deepTest/.

(Enlarge)
Manual checking reveals two false positives where DeepTest reports erroneous behaviours but the outputs (as assessed by the authors) actually are safe.

Fixing test failures
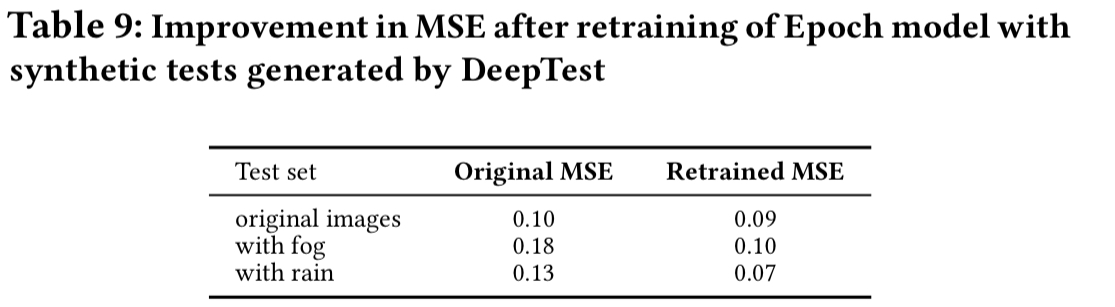
Retraining the DNNs with some of the synthetic images generated by DeepTest makes them more robust, as shown in the table below.
What about your DNN?
We use domain-specific metamorphic relations to find erroneous behaviors of the DNN without detailed specification. DeepTest can be easily adapted to test other DNN-based systems by customizing the transformations and metamorphic relations. We believe DeepTest is an important first step towards building robust DNN-based systems.

{kind=link}
Hi there! Thank you for nice post.
I wonder how did you apply rain/fog effects to image inputs? Are there any automatic/semi-automatic tool which can apply rain/fog effects to huge datasets?
Thank you again :)
The authors say that they compose “multiple filters provided by Adobe Photoshop” to simulate the rain and fog effects…