DeepXplore: automated whitebox testing of deep learning systems Pei et al., SOSP’17
The state space of deep learning systems is vast. As we’ve seen with adversarial examples, that creates opportunity to deliberately craft inputs that fool a trained network. Forget adversarial examples for a moment though, what about the opportunity for good old-fashioned bugs to hide within that space? Experience with distributed systems tells us that there are likely to be plenty! And that raises an interesting question: how do you test a DNN? And by test here, I mean the kind of testing designed to deliberately find and expose bugs in corner cases etc., not the more common (in ML circles) definition of a test set that mostly focuses on demonstrating that the mainline cases work well.
How do you even know when you have done enough testing? Code coverage is clearly not a useful metric here: even one or a very small number of inputs to a DNN might achieve 100% code coverage. Instead the authors define a neuron coverage metric that looks at the percentage of neurons which are activated during execution of a test suite.
Even more fundamentally perhaps, how do you know what the correct output should be for a given test case? Using manually labelled real-world test data it’s very hard to get good coverage. Instead, DeepXplore uses differential testing, the notion of comparing multiple different systems and seeing where their outputs differ. Although not mentioned in the paper, this is very close to the idea of an ensemble, but here we’re deliberately looking for cases where the ensemble is not unanimous. When we use an ensemble, we’re essentially saying “I know that no one model is likely to be uniformly good everywhere, so let me use a collection of models and majority voting to improve accuracy overall.” Differences between the models on some inputs is treated as normal and expected. DeepXplore looks at things differently: if n other models all make one prediction for a given input, and one model makes a different prediction, then that model has a bug.
And what happens when you explicitly test state-of-the-art DL models in this way?
DeepXplore efficiently finds thousands of incorrect corner case behaviors (e.g., self-driving cars crashing into guard rails and malware masquerading as benign software) in state-of-the-art DL models with thousands of neurons trained on five popular datasets including ImageNet and Udacity self-driving challenge data. For all tested DL models, on average DeepXplore generated one test input demonstrating incorrect behavior within one second while running only on a commodity laptop.
That’s worth repeating: give me your fully-trained state-of-the-art deep learning system, and in one second on my laptop I can find a way to break it!!
The following test case found by DeepXplore nicely highlights why this is a problem:

Unfortunately, DL systems, despite their impressive capabilities, often demonstrate unexpected or incorrect behaviors in corner cases for several reasons such as biased training data, overfitting, and underfitting of the models… Therefore, safety- and security-critical DL systems, just like traditional software, must be tested systematically for different corner cases to detect and fix ideally any potential flaws or undesired behaviors.
How DeepXplore works
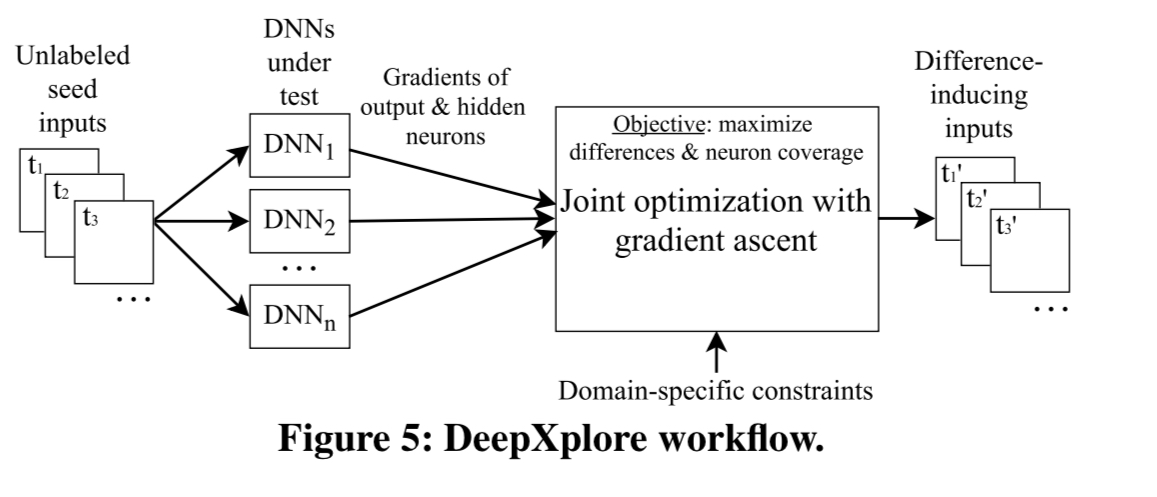
DeepXplore is based on differential testing, so it requires at least two DNNs with the same functionality. Depending on what you’re trying to do, that may be a limiting factor. “However, our evaluation shows that in most cases multiple different DNNs, for a given problem, are easily available as developers often define and train their own DNNs for customisation and improved accuracy.” Given two or more models, DeepXplore begins to explore the model space starting from a seed set of test inputs:
DeepXplore takes unlabeled test inputs as seeds and generates new tests that cover a large number of neurons (i.e., activates them to a value above a customizable threshold) while causing the tested DNNs to behave differently.
While generating new tests, DeepXplore tries to maximise both neuron coverage and the discovery of tests that cause the DNNs to behave differently. Both goals are necessary for thorough testing that exposes erroneous corner cases. It’s also possible to give DeepXplore constraints that ensure generated test cases stay within given bounds (for example, image pixel values must be between 0 and 255).
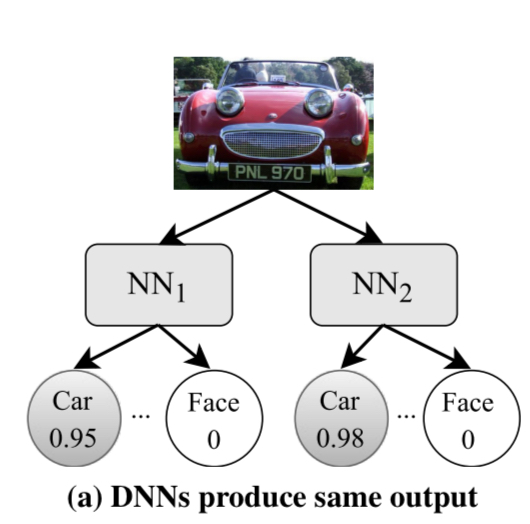
Consider a toy example of two DNNs designed to classify images as either cars or faces. We might start out in a situation like this where both networks classify an image as car with high probability:
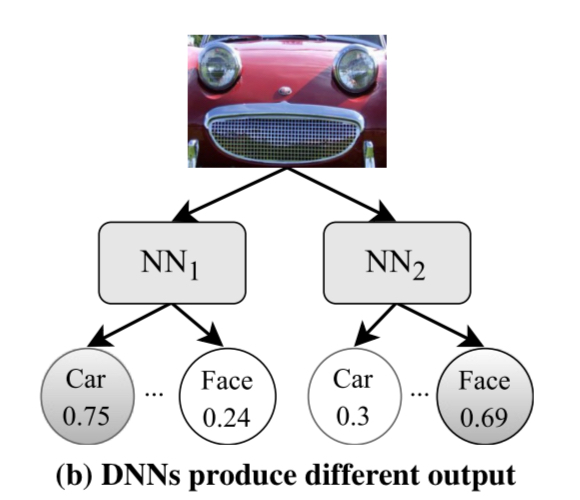
DeepXplore then tries to maximise the chances of finding differential behaviour by modifying the input such that one network continues to classify the input as a car, while the other one thinks it is a face.
In essence, it is probing for parts of the input space that lie between the decision boundaries of the DNNs:
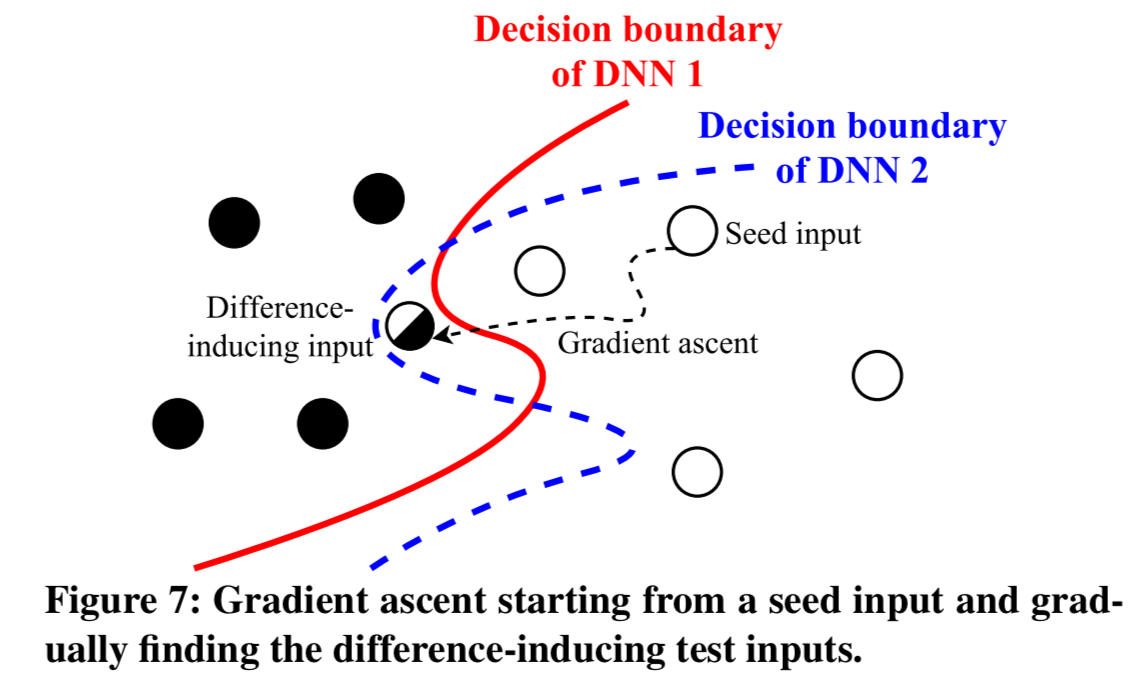
Remember that the network has already been trained at this point, so the weights are fixed. DeepXplore solves a joint optimisation problem for neuron coverage and differential behaviour maximisation using gradient ascent:
First, we compute the gradient of the outputs of the neurons in both the output and hidden layers with the input value as a variable and the weight parameter as a constant. Such gradients can be computed efficiently for most DNNs… Next, we iteratively perform gradient ascent to modify the test input toward maximising the objective function of the join optimization problem…
The joint objective function looks like this:
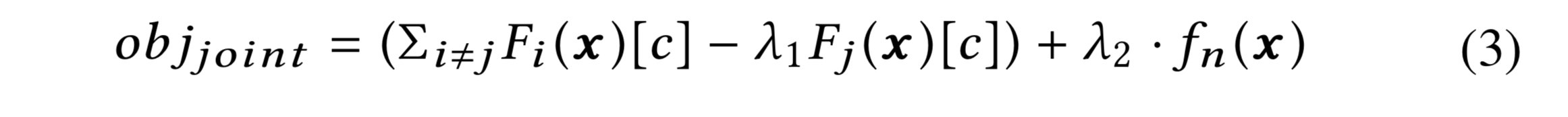
- In the first term, we try to move the input in a direction such that one model makes a different prediction while the others maintain their current prediction. The
hyperparameter balances the relative importance of these two factors.
- In the second term, we try to maximise the activation of an inactive neuron to push it above a threshold
.
- The
hyperparameter balances the relative importance of these two objectives.
Let 


The full algorithm looks like this:

The full implementation is 7,086 lines of Python code using Keras and TensorFlow.
Testing DNNs with DeepXplore
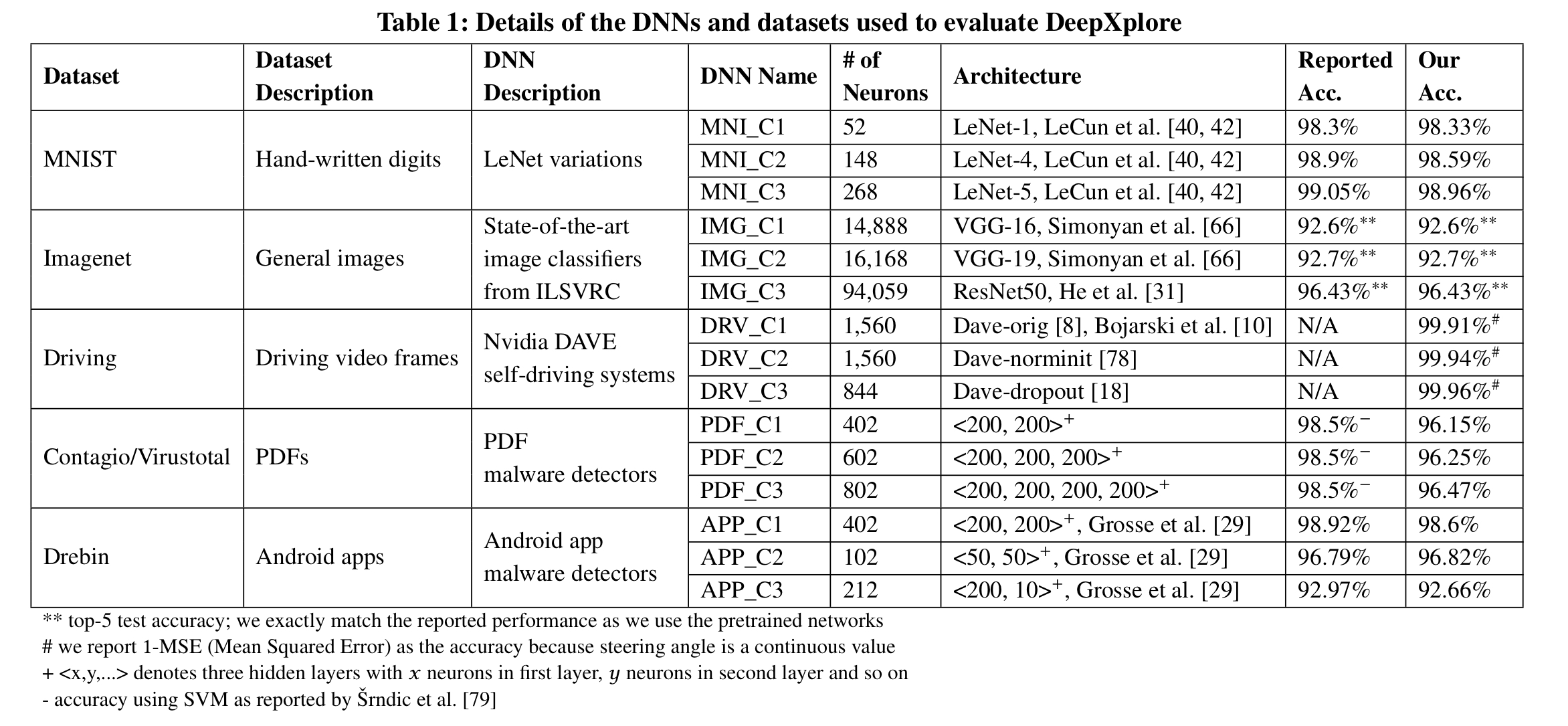
DeepXplore is tested using three DNNs for each of five different datasets:
For the image based problem domains three different constraints are explored:
- The first constraint simulates the effect of different lighting conditions: DeepXplore can make the image darker or brighter, but cannot change the content. In the figure below, the top row shows original seed inputs, and the bottom row shows difference inducing test inputs found by DeepXplore. The arrows highlight which way the self-driving car decides to turn.

- The second constraint simulates a camera lens that is accidentally or deliberately occluded by a single small rectangle.

- The third constraints simulates the effect of multiple specs of dirt on the lens by permitting occlusion using multiple tiny black rectangles.

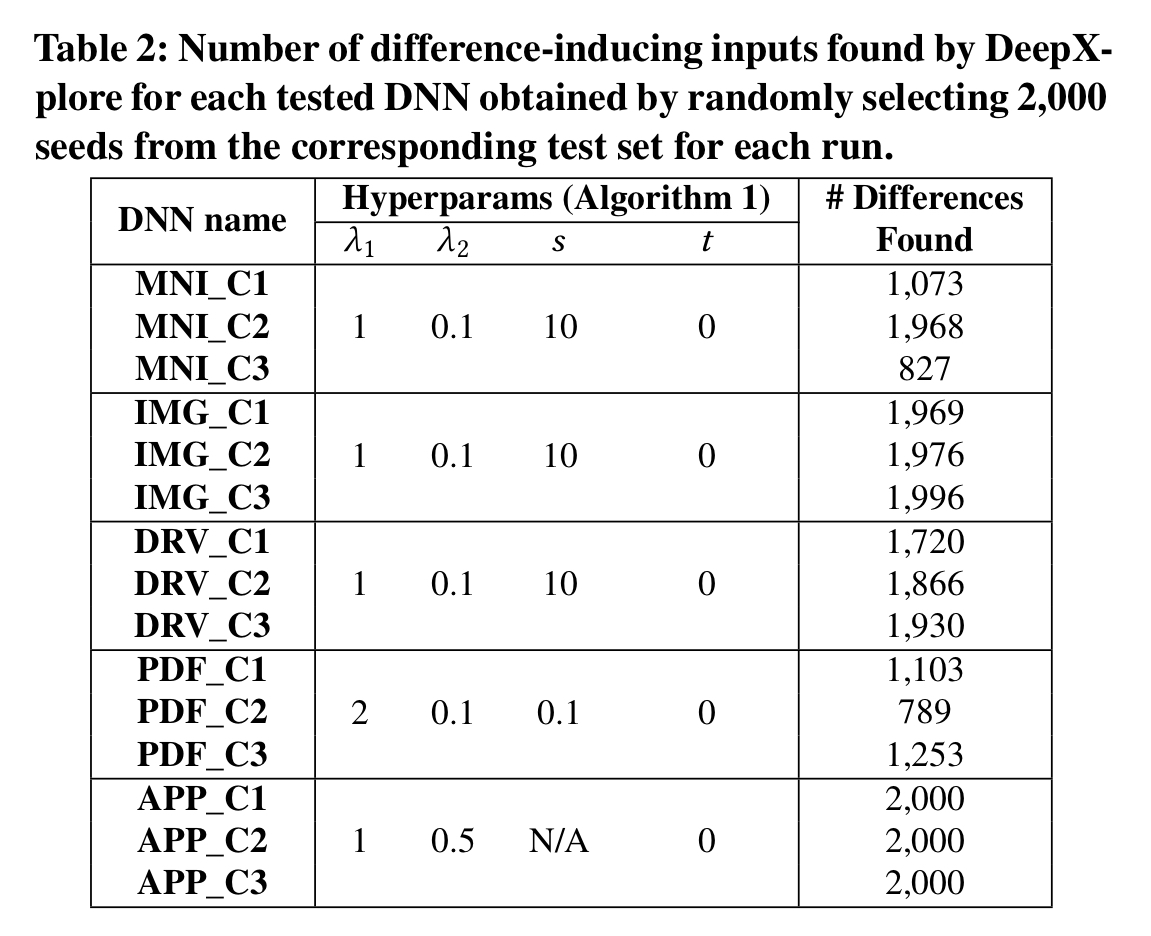
DeepXplore found thousands of erroneous behaviours in all the tested DNNs. Table 2 (below) summarizes the numbers of erroneous behaviours found by DeepXplore for each tested DNN while using 2,000 randomly selected seed inputs from the corresponding test sets.
The following table highlights the importance of including neuron coverage in the objective function as a way of increasing input diversity:
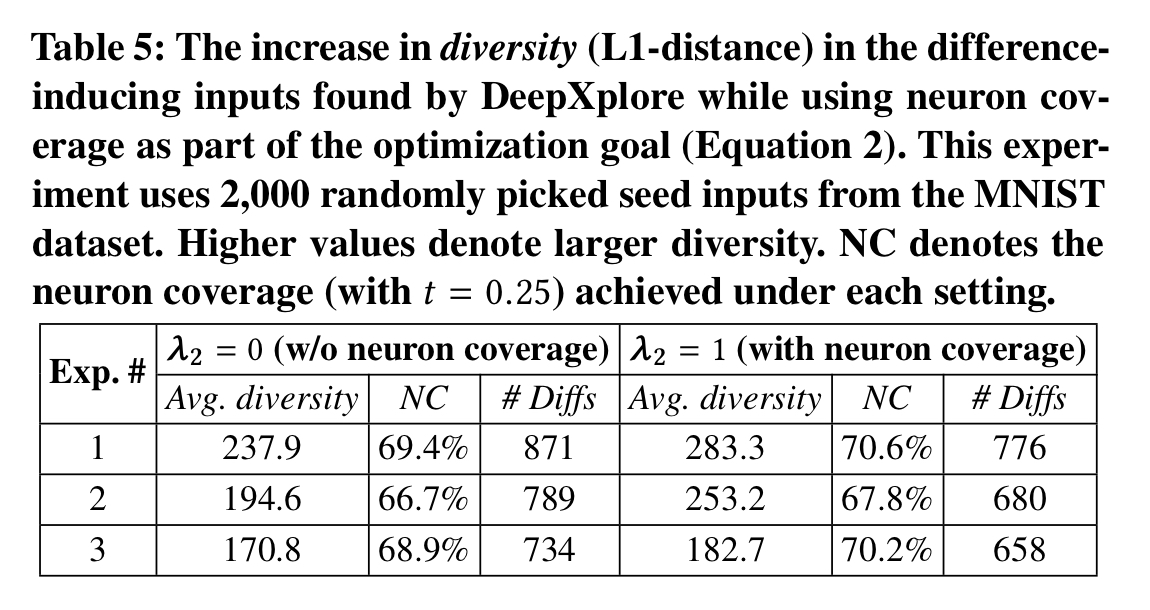
On average, DeepXplore achieves 34.4% more neuron coverage than random testing, and 33.2% more than adversarial testing.
For most models, DeepXplore can find the first difference-inducing inputs in seconds:
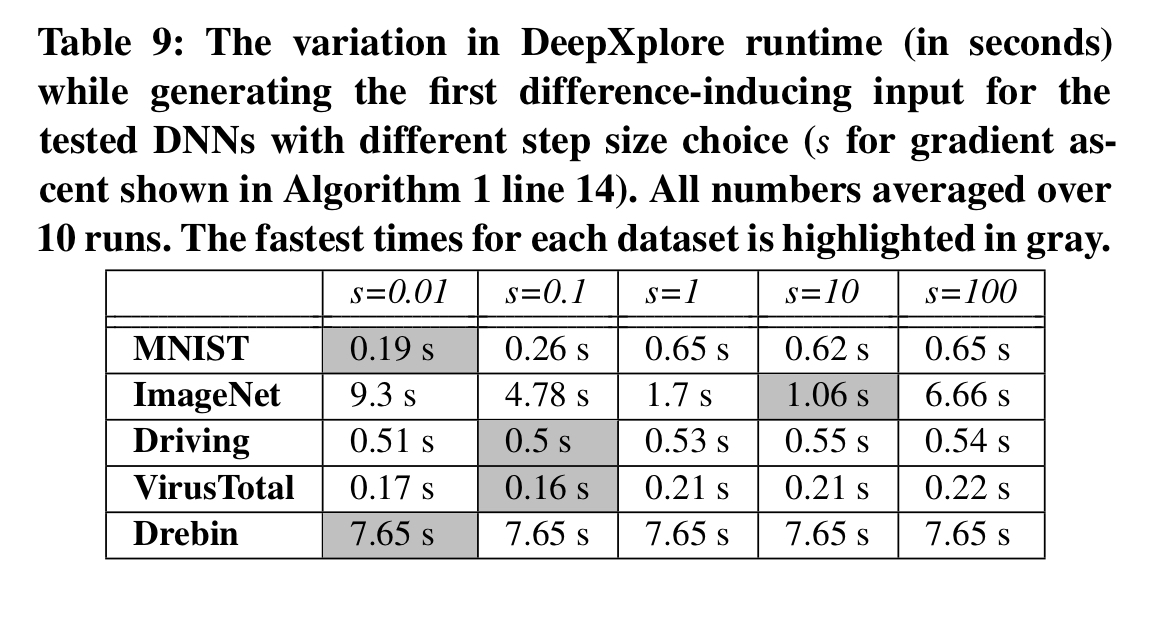
If we think of the set of DNNs like an ensemble, and use majority voting, then have an automated labelling system for the generated test cases. Using these as new labeled training examples improves accuracy by 1-3%.

2 thoughts on “DeepXplore: automated whitebox testing of deep learning systems”
Comments are closed.