JavaScript for extending low-latency in-memory key-value stores Zhang & Stutsman, HotCloud’17
Last year we looked at RAMCloud, an ultra-low latency key-value store combining DRAM and RDMA. (Also check out the team’s work on patterns for writing distributed, concurrent, fault-tolerant code and how to support linearizable multi-object transactions on RAMCloud with RIFL). Now the RAMCloud research group is looking to use use RAMCloud as a platform to build other higher-level services on top, and this is where the simple key-value interface has started to become a limitation.
Developing new systems and applications on RAMCloud, we have repeatedly run into the need to push computation into storage servers.
- Applications that chase inter-record dependencies (fetching one record, then using the returned value to fetch other records) need multiple round trips, and even the 5
µs round trip time RAMCloud offers is too high under these conditions. In fact, 5µs turns out to be a very awkward amount of time: too long for spinning without killing throughput, and too short to context switch without losing most of the gains in switching overhead. - Applications that are throughput bound can’t push down operations like projection, selection, and aggregation, causing way too much data to be shipped to the client for filtering there.
So, RAMCloud needs a way to run more of an application’s computation on the server-side (i.e., stored procedures or similar). This paper is an investigation into how this could be supported. It’s interesting for the conclusion that an embedded JavaScript engine might be the way to go, even in an environment as latency-sensitive as RAMCloud.
The team have five key criteria for a server-side user code model:
- Near native performance. RAMCloud keeps all data in DRAM and uses kernel bypass networking with operations dispatched in 1.9
µs. Low latency is what it’s all about, sacrificing that makes no sense in a RAMCloud world. - Low invocation overhead. With potentially millions of stored procedure invocations per second, just a few cache misses on each could reduce server throughput by 10% or more.
- The ability to add and remove procedures at runtime without restarting the system.
- Inexpensive isolation. A large RAMCloud cluster is likely to support multiple tenants, switching between protection domains must be low overhead.
- Low installation overhead – no expensive compilation phase to add procedures (the design should support ‘one-shot’ procedures).
What would you do?
The authors considered three candidate approaches: SQL, C++/native code, and JavaScript. And I have to say here, even though it’s not what they ended up with, I think there’s an awful lot going for the SQL option. For the cases that really matter, I have a hunch a good SQL query optimiser is going to produce a much faster solution than anything I’m going to write by hand. If you look again at the cited use cases above they boil down to joins, selection, projection, and aggregation – all very well addressed by SQL! However, for the full spectrum of data processing challenges that the team ultimately want to address with RAMCloud, SQL was felt to be too limiting:
Overall, the SQL’s main drawback is that it is declarative. For most workloads, this is a benefit, since the database can use runtime information for query optimization; however, this also limits its generality. For example, implementing new database functionality, new operators, or complex algorithms in SQL is difficult and inefficient.
Let’s just go with the flow, and assume that the ability to write your own imperative stored procedures absent of SQL is required. That way we can get onto the interesting JavaScript engine parts!
With SQL ruled out, the default option is probably native code:
Since the high performance of DRAM exposes any overhead in query execution, we initially expected that native code execution with lightweight hardware protections would be essential to the design.
The procedure mechanism incurs three forms of invocation overhead:
- The one-off cost to compile / install a procedure
- The cost to invoke the procedure
- The cost for the procedure to invoke database functionality.
The tricky part with native code turns out not to be the cost of running procedures, but the cost of providing the required isolation: “we considered several approaches including running procedures in separate processes, software fault isolation, and techniques that abuse hardware virtualization features. These techniques show little slow down while running code, but they greatly increase the cost of control transfer between user-supplied code and database code.”
Enter JavaScript: it’s safe and sandboxed, doesn’t require hardware protections that slow down domain switches, and the JIT can make compute-bound tasks fast.
In their microbenchmarks, creating a new JavaScript context for the first time takes 889 ns, whereas in the C++ case a new process can be forked in 763 ns. The js context can be reused by a tenant across calls so its overhead is quickly amortised. The big win is that invoking a JavaScript procedure from C++ takes only 196 ns, whereas invoking a procedure in another hardware protected process takes 2 x 1,121 ns – JavaScript is 11.4x faster on this key metric! Adding hardware protection to the C++ solution adds further overhead and leads to JavaScript being 72x faster.
Hosts of V8 can multiplex applications by switching between contexts, just as conventional protection is implemented in the OS as process context switches… A V8 context switch is just 8.7% of the cost of a conventional process context switch… V8 will allow more tenants, and it will allow more of them to be active at a time at a lower cost.
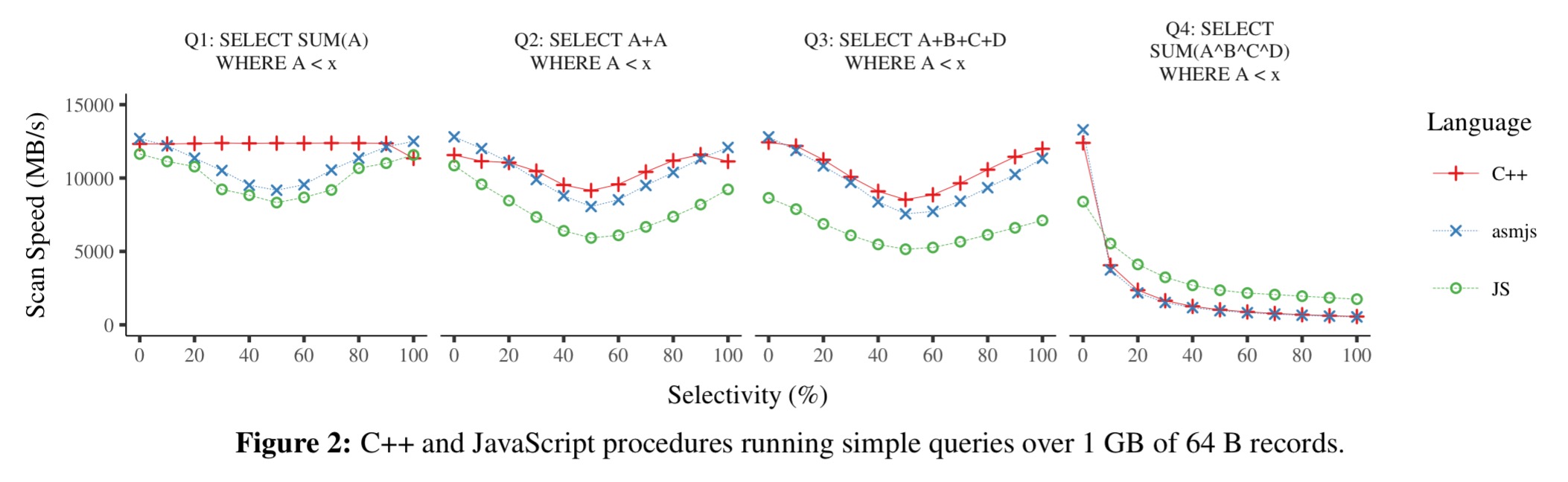
The authors also discuss the option of compiling procedures written in C++ to asm.js. “Asm.js code loads fast, runs fast, and it retains the isolation benefits of the JavaScript runtime.” A set of query benchmarks show that asm.js is within 2-10% of native code performance.
The paper doesn’t discuss WebAssembly at all, nor does it mention anywhere (that I spotted) what version of V8 the tests were run with. I note that WebAssembly is even faster than asm.js, and can also support Non-Web Embeddings. If you’re using V8 though as per this paper, you may not even need to do anything special to take advantage of WebAssembly – as of the recently created v6.1 development branch (August 2017) V8 will transpile any valid asm.js code to WebAssembly. (Ok, strictly embedders do need to do one small thing – enable the --validate-asm flag).
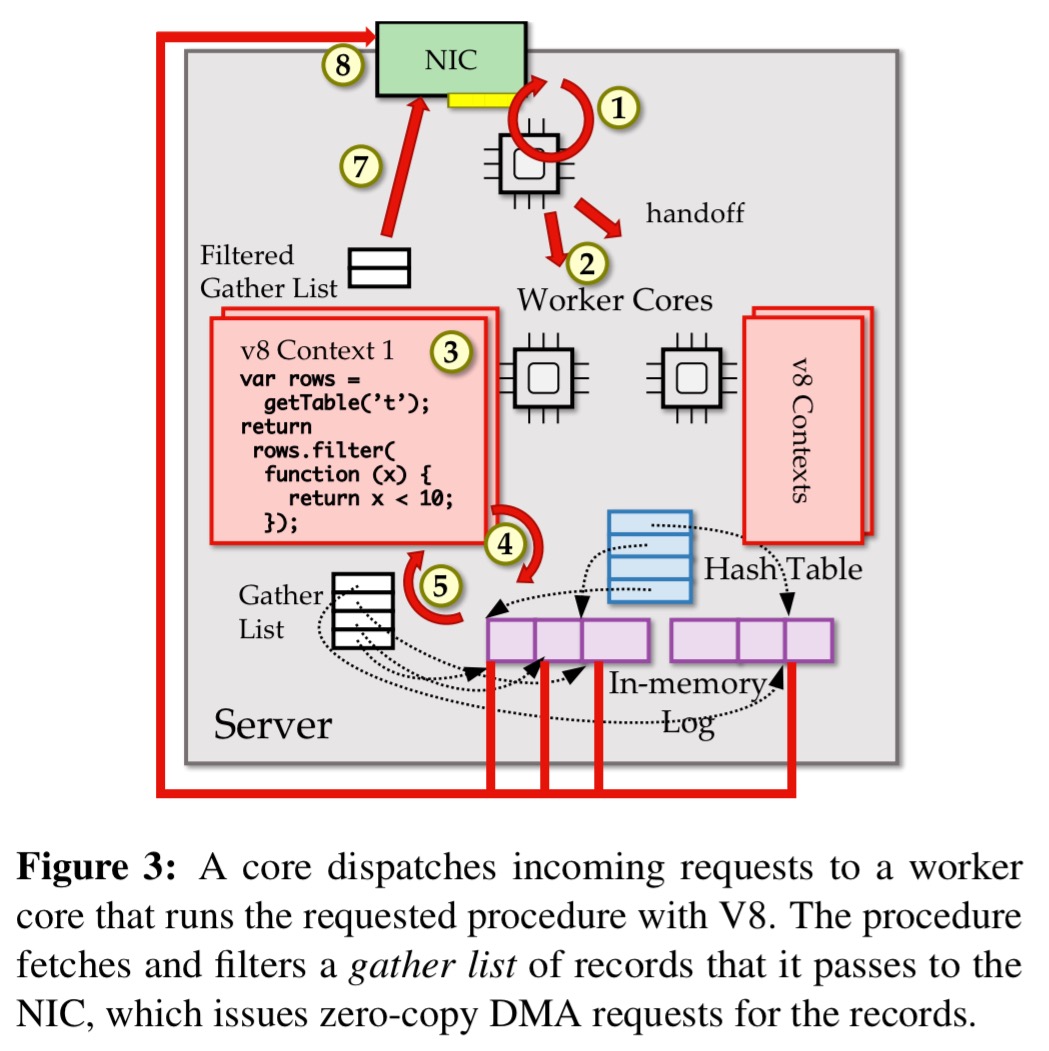
With procedure invocation and database interactions 11.4-72x faster, and code only 2-10% slower than native even before considering WebAssembly, JavaScript looks promising. Embedding V8 in RAMCloud would look something like this. All the magic happens in step 6 ;).
Five key design features help to achieve good performance:
- Relying on Javascript runtime enforcement to provide direct fine-grained access to database records. This also allows the JIT to exploit instruction-level parallelism, SIMD instructions and so on.
- Minimise data movement – JavaScript procedures will be able to return results to clients over the network card using zero-copy DMA without the involvement of the CPU.
- Exploit procedure semantics for efficient garbage collection. Most procedures complete quickly and this can be exploited to minimise garbage collection.
- Expose database abstractions to JavaScript, such as recovery logging features. “For example, JavaScript procedures may be able to implement transactions, indexes, triggers, and pub/sub callbacks.“
- Lightweight per tenant state for fast protection domain switching.
Our next goal is to embed V8 into the RAMCloud server; to develop a smart API for procedures that exposes rich, low-level database functionality; and to begin experimenting with realistic and large scale applications.
And what might those applications be? We have some specific applications in mind:
- distributed concurrency control operations
- relational algebra operators
- materialized view maintenance
- partitioned bulk data processing as in MapReduce
- custom data models such as Facebook’s TAO.

Very, very interesting read. Loved the concept of Zero-copy DMA. Have even started reading the patent that was published. BTW, where is the 6th step? Am I missing something?
Thanks.
There is no 6th step in the figure that I could see :). I think the authors just mis-labeled it.
There are a lot of cool programming languages able to be transpiled to JS
– ocaml
– scala
– haxe
The only drawback i see is the limits of JS in terms of array size for example.
Thanks for your article!
I have one question: when you mentioned about RAMCloud, you said “an ultra-low latency key-value store combining DRAM and RDMA”. But is it true that RAMCloud leverages RDMA?
Sorry, no! That’s my mistake. RAMCloud is straight RPC assuming a fast network.
Thanks. There is no 6th whole tone in the name that I could see to it :).
Thanks. There is no 6th pace in the public figure that I could ensure :).