Paracloud: bringing application insight into cloud operations Nadgowda et al., HotCloud’17
We’ll be looking at a selection of papers from HotCloud’17 this week. The HotCloud workshop focuses on new and emerging trends in cloud computing, and the CfP particularly encourages position papers that describe novel research directions and work that is in its formative stages.
With Paracloud, Nadgowda et al. seek to go one step deeper into what it means to be a cloud native application by enabling cloud applications to participate in platform management decisions.
The critical inference here is that applications have intimate knowledge of their own operating state parameters, which are typically different for every application. The cloud platform cannot gauge these parameters reliably for all applications. Paracloud can help bridge this gap and provide a shared-responsibility model, where all the cloud functions like auto-scaling, migration, load-balancing etc., are implemented by the platform with application insight and cooperation through APIs.
Applications know best?
The authors chart three generations of application runtime as shown below: physical, virtual, and containerised.
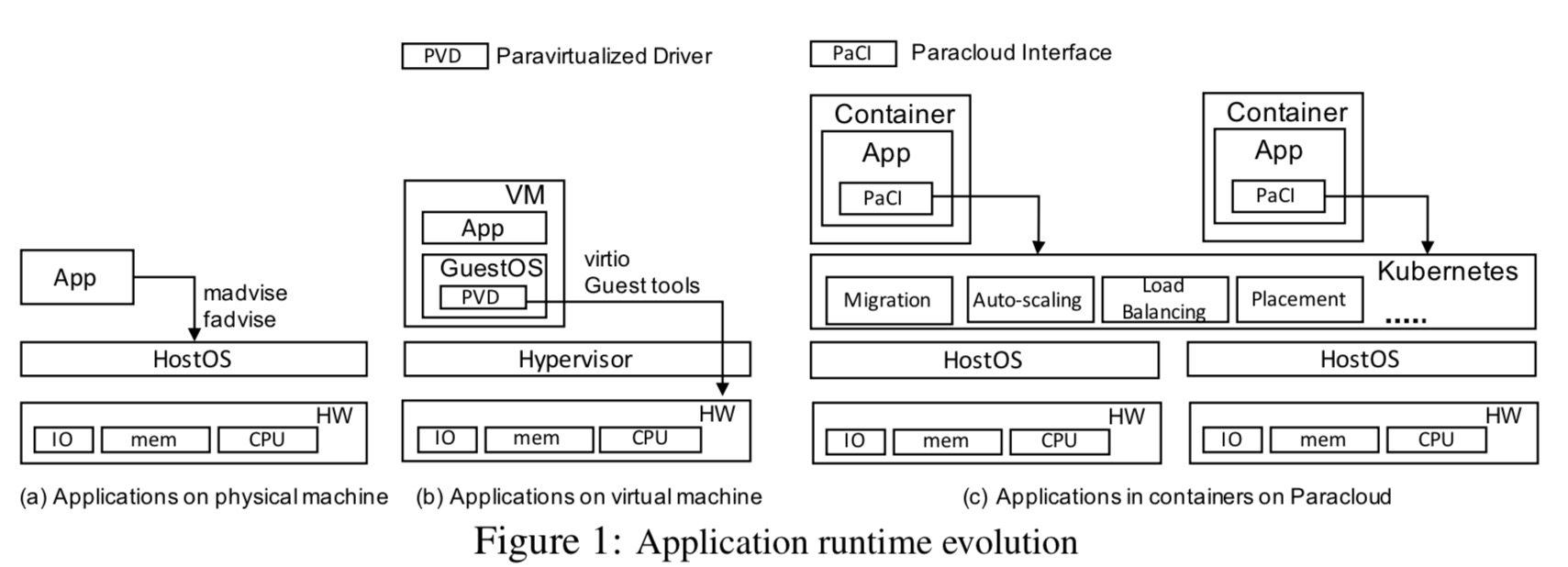
When applications were deployed to physical infrastructure, the assumption typically was that they would be long running with dedicated resources. So it made sense for example to allocate large buffer caches on startup. Applications provided hints to the Linux kernel using system calls such as fadvise and madvise, which enabled the kernel to choose appropriate read-ahead and caching techniques.
When such applications were moved to the cloud using virtual machines, techniques that made sense under physical resource assumptions such as allocating large buffers no longer fit so well with vm migrations (e.g., for maintenance or for load balancing). Since the applications knew nothing about the underlying cloud platform, the relevant information needed to be extracted from them:
… different techniques have been employed to extract application level knowledge for aiding management operation. This includes installing paravirtualization drivers, in-guest controller agents (both referred to as PVD in the above figure), leveraging or extending language runtime capabilities like apache modules or JDBC interfaces, or modifying the application directly.
Today the shift to container-based deployment is well underway. This doesn’t alleviate the need for application awareness in platform management operations though, if anything it makes this need even more pressing…
With containers, the principle of ‘application knows best’ does not change. What does change is the nature of the interface between applications and the hosting layer, which becomes closer to the traditional systems with the removal of the guestOS abstraction of VMs. Also, the scale of management operations grows, owing to an even greater flexibility and elasticity afforded by the container abstraction.
This principle of ‘application knows best’ will be much easier to develop an intuition for once we’ve looked at a few use cases.
Application in-the-loop orchestration use cases
The authors discuss three use cases: migration, auto-scaling, and load-balancing.
Migration
Although migration may seem redundant for stateless application containers, it is still pertinent to several stateful microservice applications like databases, message brokers, and coordination services amongst others.
When large memory buffers or heaps are allocated by applications, they can present a problem when the application containers are to be migrated. For example, in stop-and-copy based migration application downtime may increase while non-dirty, unused, speculatively cached, or to-be-garbage collected pages are copied. The application is in by far the best position to minimise its state ahead of any checkpointing or transfer.
… we propose signaling an application container to be migrated and allowing a short migration grace-period for ‘preparation’. This allows the application to minimize its memory footprint, for example by running its garbage collector to release heap-memory, flushing its IO buffers, and releasing all temporary resources like temp files.
When the container is restored at the target, it can likewise be signaled to reconfigure itself to the new environment.
Auto-scaling
From outside of an application, it can be hard to distinguish between a genuine need for auto-scaling, and opportunistic use of resources by an app.
For example, most database applications tend to perform various auxiliary functions besides storing and accessing data, like periodic log rotation, data compaction, data pruning, auditing and consitency checks, etc. These function are commonly designed to exploit slack. They consume resources over the actual workload processing when there are free cycles and can cause false-positive auto-scaling triggers.
As another example, ElasticSearch tries to keep as much of its index in memory as possible – an autoscale policy that tries to keep a certain amount of memory free will always be fighting against this.
In contrast, Paracloud provides a way for an application to indicate whether it really desires new instances to be forked, given its current operational state. The auto-scaler on sensing an increased usage beyond the set threshold, can signal the container indicating an up-coming scaling operation, allowing it to optionally dictate its intention. The application can validate the trigger against its actual state, and try to minimize usage of some resources if its operational state allows.
The authors also suggest an application should be able to provide proactive hints to the autoscaler, as well as specifying the kind of resources (sibling instances) it needs.
Load balancing
During high resource contention, a management platform may choose to kill or migrate certain containers. One common practice is to kill those consuming the most resources – but these may be the very containers that are the most active and/or may be stateful. It would be more effective to kill other less-active and/or stateless application instances.
Such scenarios can be handled better by tying Paracloud with cloud load balancers… we propose to expose an
appYieldinterface between containers and the cloud platform, enabling applications to yield themselves temporarily during high resource contention, similar to Linux’sched_yield-based co-operative scheduling.
Applications (replica sets) that are notified can either decide to yield, releasing the contented resource, or risk termination.
The Paracloud extensions to Kubernetes
…we believe it is the right time to make applications aware of the characteristics of their cloud platforms and revisit and revise their assumptions about them.
The Paracloud interfaces are implemented on top of Kubernetes, extending the existing PostStart and PreStop container hooks.
…we motivate the extension of the scope of cluster-native application beyond just lifecycle events to critical cloud operations like auto-scaling, migration, and load-balancing. We have currently designed six new interfaces for Kubernetes…
- The preMigrate container hook is called at_most_once after the container is scheduled for migration but before it is checkpointed.
- The postRestore container hook is called at_most_once after the container is restored to a running state and before it is reported as available.
- The reqYield container hook is called at_least_once on containers running on heavily loaded nodes.
- A container that has received a reqYield notification may invoke the appYield API if it decides to yield resources. If load has subsequently dropped to an acceptable level, such calls are ignored.
- The chkAutoscale hook is called to validate a scaling request whenever an autoscale is triggered. It allows a configurable grace period for handler processing and mitigation actions. If the auto-scale condition still holds after this grace period, application scaling is implemented by the platform.
- An application can call hotScale if it wants to hot scale (as opposed to cold scale) by creating a clone of of one its running instances.
The hook handlers and the Kubernetes client for API calls are implemented in sidecar containers.
Autoscaling evaluation
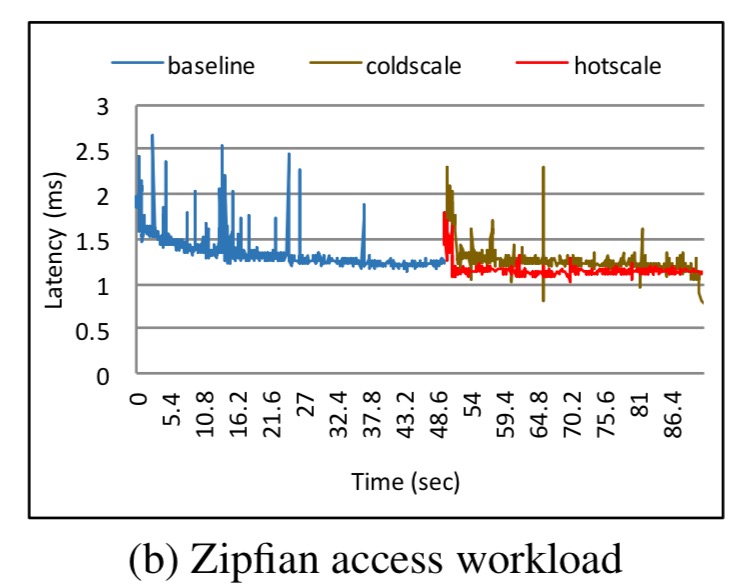
The only evaluation so far is of the autoscaling use case, using MySQL 5.7.15 from DockerHub with the YCSB benchmark. The Kubernetes cluster triggers an autoscale when the container uses more than 80% of the available memory for more than 30 seconds. The experiments are performed with both a uniform and zipfian access pattern, and the study looks at the difference between requesting a hot scale and doing nothing (equivalent to requesting a cold scale).
For the zipfian access pattern, hot scaling works better than cold scaling.
For the uniform access pattern, cold scaling works better:
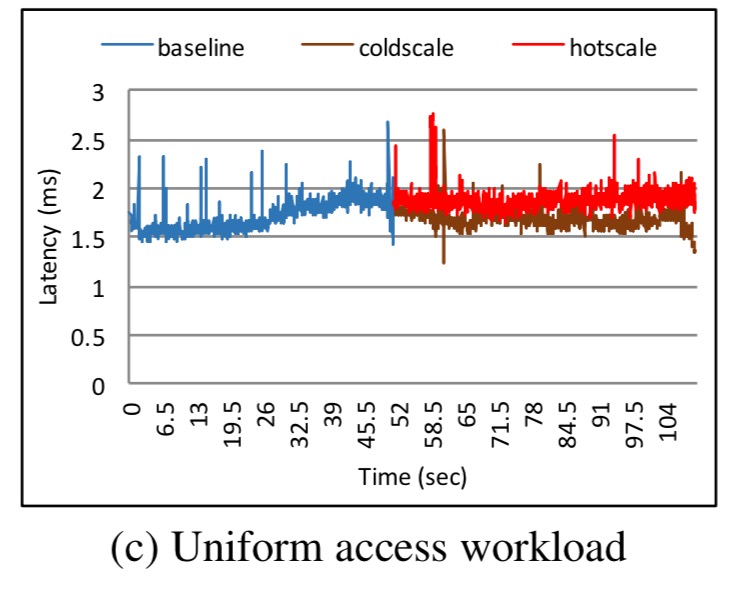
(Hot scaling under a uniform access pattern replicates a thrashing query cache).
These results demonstrate the substantial advantages with Paracloud providing application insight in cloud applications… Only judicious application of scaling techniques, driving by the applications themselves, can lead to net benefits.

4 thoughts on “Paracloud: bringing application insight into cloud operations”
Comments are closed.