Azure data lake store: a hyperscale distributed file service for big data analytics Douceur et al., SIGMOD’17
Today’s paper takes us inside Microsoft Azure’s distributed file service called the Azure Data Lake Store (ADLS). ADLS is the successor to an internal file system called Cosmos, and marries Cosmos semantics with HDFS, supporting both Cosmos and Hadoop workloads. Microsoft are in the process of migrating all Cosmos data and workloads onto ADLS.
Virtually all groups across the company, including Ad platforms, Bing, Halo, Office, Skype, Windows and XBOX, store many exabytes of heterogenous data in Cosmos, doing everything from exploratory analysis and stream processing to production workflows.
ADLS is not just used internally of course, it’s a part of the Azure cloud offerings, complementing Azure Data Lake Analytics.
ADLS is the first public PaaS cloud service that is designed to support full filesystem functionality at extreme scale… The largest Hadoop clusters that we are aware of are about 5K nodes; Cosmos clusters exceed 50K nodes each ; individual jobs can execute over more than 10K nodes. Every day, we process several hundred petabytes of data, and deliver tens of millions of compute hours to thousands of internal users.
Several aspects of the design stand out as noteworthy to me:
- ADLS stores files across multiple storage tiers with support for partial overlapping
- ADLS is architected as a collection of microservices, which themselves need to be scalable, highly available, have low-latency, and be strongly consistent. “The approach we have taken to solve the hard scalability problem for metadata management differs from typical filesystems in its deep integration of relational database and distributed systems technologies.”
- ADLS is designed ground up for security.
- ADLS has a fast path for small appends
Let’s go into each of these areas in more detail.
The structure of a file in ADLS
An ADFS file is referred to by URL and comprises a sequence of extents, each of which is in turn a sequence of blocks. Extents are the units of locality, blocks are the units of append atomicity and parallelism. All extents but the last one are sealed. Only an unsealed last extent may be appended to.
The notion of tiered storage is integral to ADLS. Any part of a file can be in one or more of several storage tiers.
In general, the design supports local tiers (including local SSD and HDD tiers), whose data is distributed across ADLS nodes for easy access during job computation, and remote tiers, whose data is stored outside the ADLS cluster.
ADLS has a concept of a partial file, which is a contiguous sequence of extents. A file is represented internally as an unordered collection of partial files, possible overapping, each mapped to a specific storage tier at any given time.
We move partial files between tiers through decoupled copying and deleting. To change the tier of a partial file, a new partial file is created in the target tier, by copying data from the source partial file. For a time, two separate partial files (in two different tiers) are represented in the Partial File Management service, containing identical data. Only then is the source partial file deleted. When a partial file is no longer needed, it is deleted, while ensuring that all extents in it also exist in some other partial file, unless the file itself is being deleted.
ADLS System Architecture and RSL-HK Rings
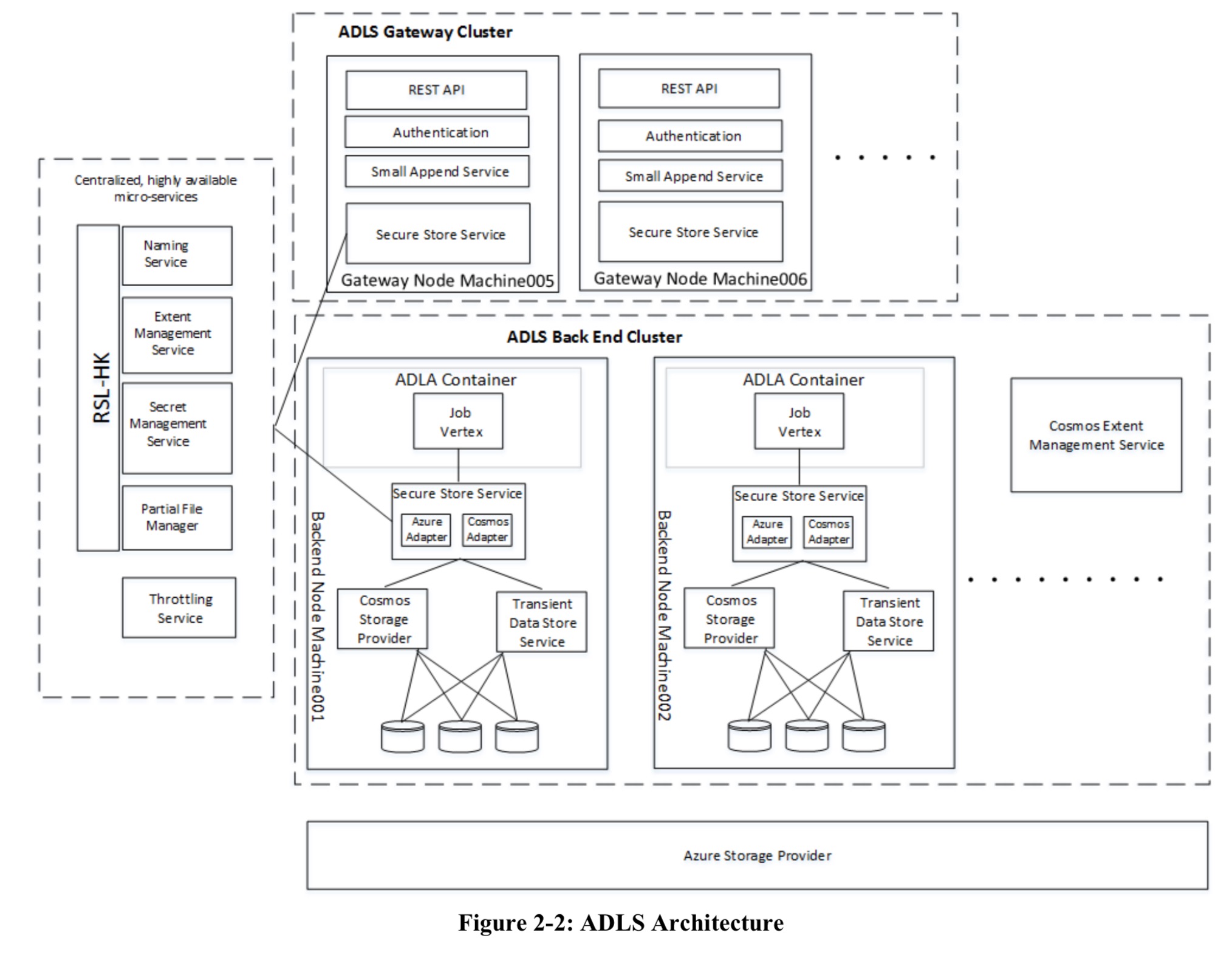
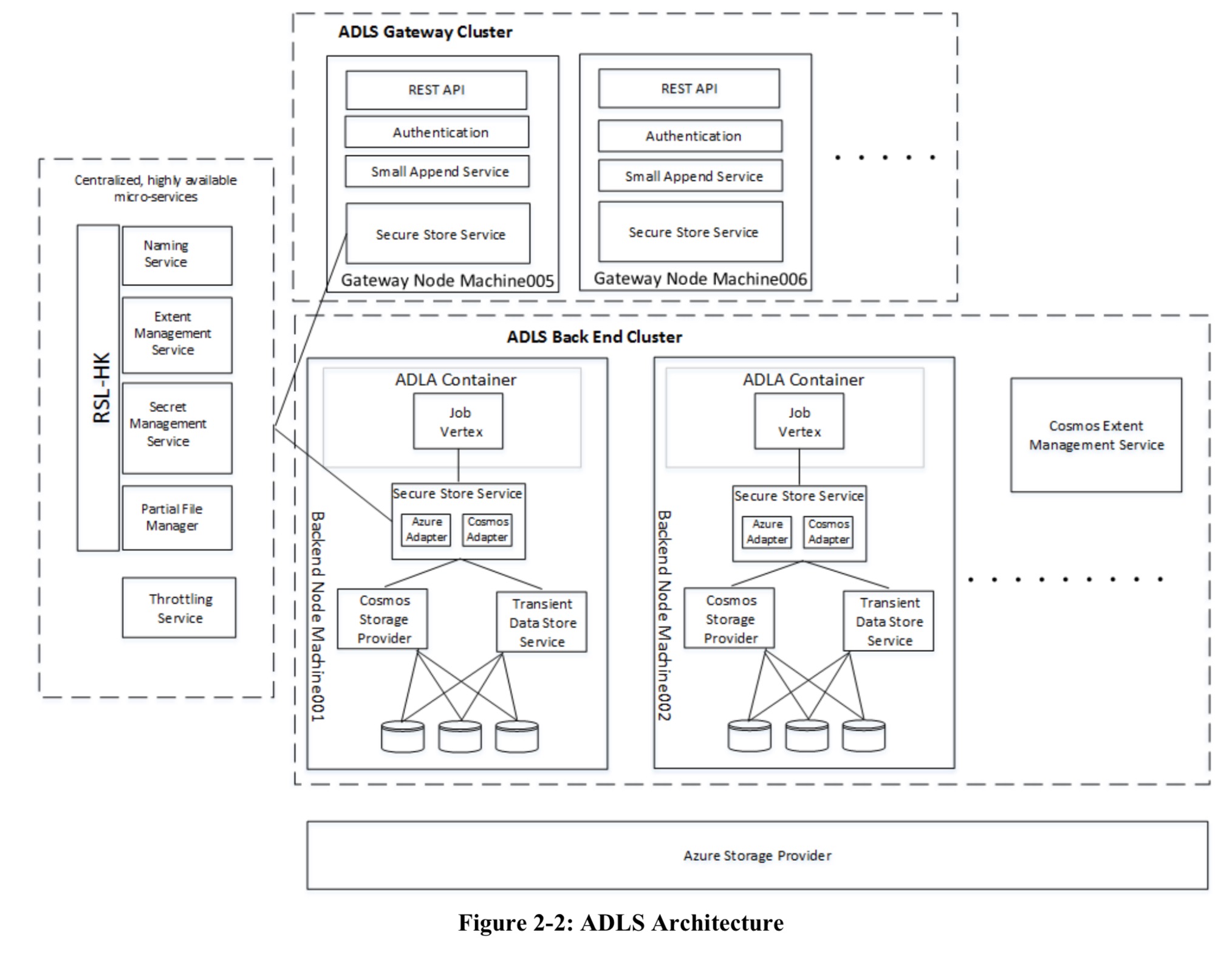
The big picture view of the ADLS architecture looks like this:
 (Enlarge)
(Enlarge)
The Secure Store Service (part of the Gateway Cluster) is the point of entry and security boundary between ADLS and applications.
It implements the API end points by orchestrating between metadata services and storage providers, applying lightweight transaction coordination between them when needed, handling failures and timeouts in components by retries and/or aborting client requests as appropriate, and maintaining a consistent internal state throughout and ensuring that a consistent state is always presented to clients.
There are a collection of core microservices, each of which needs to scalable, highly-available, low-latency and strongly consistent. These core microservices are all built on a foundation the authors call an RSL-HK ring. More on that in a moment. The core microservices are:
- The Naming Service, which maps mutable hierarchical paths to fixed references to objects in other ADLS metadata services. The Naming Service supports renames and moves of files and folders without copying data.
- The Extent Management Service tracks the location of every extent of every file in a remote storage provider.
- The Secret Management Service (SMS) handles all internal secrets needed for the functioning of the core microservices, as well as customer-managed secrets. It is both a secret repository and a broker to access external secret repositories (e.g., the Azure Key Vault). SMS also handles all compression, decompression, encryption, and decryption. The Trusted Software Module component of SMS handles all these data transactions in a separate process sat behind a dedicated proxy. As such, the way is paved to e.g., run the TSM inside a secure enclave in the future if so desired.
- The Partial File Manager looks after the mapping from file ID to a set of one or more partial files.
- The Throttling Service collects information from all of the Secure Store Service gateways every 50ms, identifying a list of accounts that should be throttled according to the quotas associated with them. The Secure Store Service uses this list to block indicated accounts for the next 50ms.
All of these microservices (except the throttling service) are themselves replicated systems. These take advantage of a Replicated State Library first built for Cosmos:
… we have long used the Replicated State Machine approach, based on a proprietary Replicated State Library (RSL) that implements the core underlying replication, consensus, checkpointing and recovery mechanisms. RSL implements Viewstamped Replication, with consensus based on Paxos and improvements described in [Tiered Storage. Architectural Note. Microsoft Nov 2012].
An RSL-based service is deployed in a quorum-based ring, usually made up of seven servers distributed across failure domains. RSL proved to be a useful building block, but service state management still required complex and custom code to use the RSL state management facilities efficiently. ADLS builds on the core RSL approach by adding a declarative state management layer based on the in-memory tables from the SQL Server Hekaton engine. This combination of RSL and Hekaton leads to RSL-HK rings.
- The persistent state of a service is maintained as replicated in-memory Hekaton tables and indices.
- Metadata (service) operations are written as transactions with ACID semantics via Hekaton optimistic concurrency support
- In this way, service developers get fault tolerance for all state changes including checkpointing, logging, and recovery.
A service developer defines the structure of the state by specifying the schema of Hekaton tables and any desired indexes on them for performance. The developer also then provides the callback functions for service operations, which execute as transactions on the Hekaton tables.
RSL-HK leverages Hekaton to give service developers a more declarative way to manage state, and transparently provides replication and recovery in an application-agnostic way, thereby freeing service developers to concentrate solely on the service’s external interface and its logic.
RSL-HK achieves high throughput and latencies less than 1ms for read transactions, and 10ms for write transactions. Here you can see the performance of RSL-HK underpinning the naming service:

Security
ADLS is architected for security, encryption, and regulatory compliance to be enforced at scale.
Authentication and role-based access control are performed through an integration with Azure Active Directory based on OAuth tokens from supported identity providers. Tokens are augmented with the user’s security groups, and this information is passed through all the ADLS microservices. Files and folders support POSIX-compliant permissions. Data flowing into and through ADLS is encrypted in transit and at rest.
ADLS provides encryption at rest for all data. Each append block is encrypted separately, using a unique key, ensuring that the amount of cypher text produced using any given key is small. The emphasis that ADLS places on extremely large files makes this especially important. The header for every block contains metadata to allow block-level integrity checks and algorithm identification.
There are three types of keys: a master encryption key (MEK), a data encryption key (DEK) and a block encryption key (BEK).
For user accounts, a user can generate a MEK and store in the Azure Key Vault, for service managed keys the Secret Management Service simply generates one on their behalf. The MEK is used to encrypt all other keys, so deleting the MEK “forgets” all of the data (best not to forget by accident!).
The DEK is generated by the Secret Management Service and is used as the root key for all subsequent file encryption keys. It is encrypted using the MEK and stored in the ADLS cluster.
The BEK is generated for each block using the account’s DEK and the block’s ID, and is used to encrypt the block.
Encryption and decryption might be expected to introduce significant overheads. However, in executing a board mix of U-SQL queries on ADLA, producing a 60/40 read/write mix of data traffic, encryption and decryption only added 0.22% in total execution time (on a baseline of over 3000 hours).
Small appends fast path
ADLS has a Small Append Service (SAS) that supports low-latency small appends (a weakness of HDFS).
Low-latency small appends are critical for transactional systems such as HBase on top of ADLS. HBase Write-Ahead Logging append latency directly impacts HBase transaction rate. The figure below shows the append latencies with and without SAS enabled.
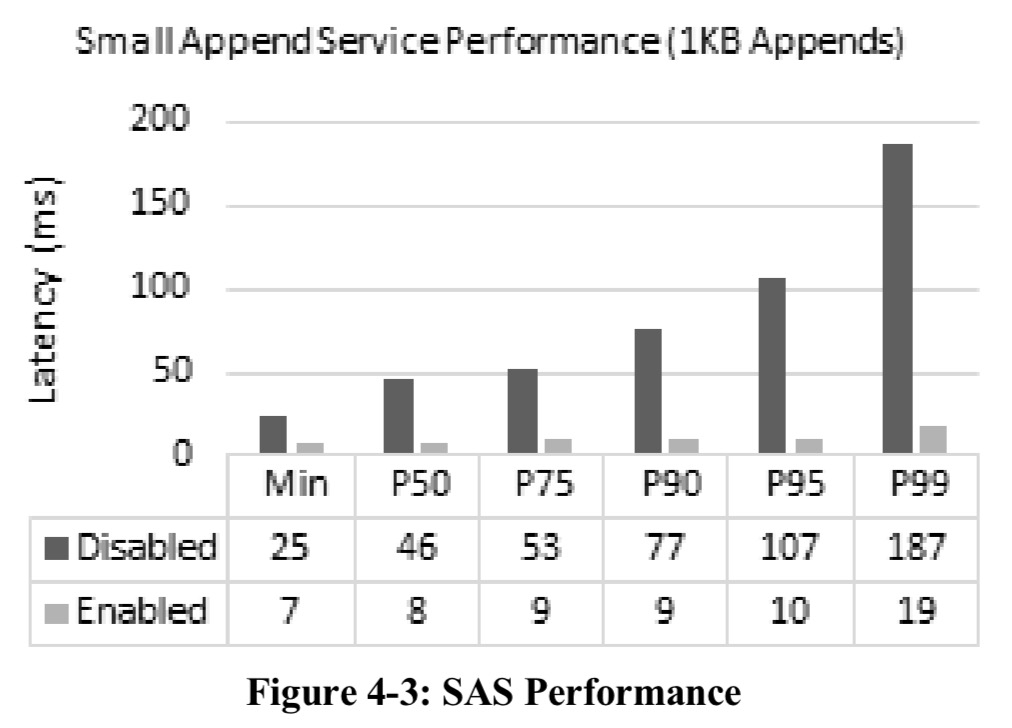
When SAS determines that a file’s append pattern is dominated by small appends, it switches them to the small append path which uses low-latency storage to store the payload. Such appends are durable once acknowledged. (Large appends are passed directly onto the downstream providers). Small appends are then collected asynchronously into larger append blocks before being moved to one of the storage tiers.
Other bits and pieces
There’s plenty more in the paper that I didn’t have space to cover here, including details of some of the other services, how ADLS works with storage providers, and a walkthrough of the overall flows for major operations. If you’re interested in the topic, it’s well worth checking out.

{kind=link}
Great Article. All information aligned at one place. Hyper scale distributed file service for Data Data analytics Microsoft are in the process of migrating all Cosmos data and workloads onto Azure Data Lake Store ADLS. Good Point and using figures we understood in-depth.
very well explain about three types of keys: Master encryption key, Data encryption key, Block encryption key. Am interested to know more about how ADLS works with storage providers and overall flows for major operations. Thanks for sharing information with us!
Thanks for such useful blog! I take a look at your blog it’s really great. Keep up the good work.
Thanks! Could you do a follow up with the public preview annoucement of ADLS Gen2? What differs between Gen1 and Gen2?
https://docs.microsoft.com/en-us/azure/storage/data-lake-storage/introduction