Efficient memory disaggregation with Infiniswap Gu et al., NSDI ’17
If we move performance numbers onto a human scale (let 1ns of processor time = 1 second of human time) then it’s easier to get an intuition – for me at least – of the relative cost of different operations. In this world, it takes about 10 seconds on blended average to read data from a register/L1/L2/L3 cache. Reading data from main memory takes about 70 seconds. How long does it take to read/write to disk? For a traditional spinning HDD, a staggering ~116 days! Make that an SSD, and you can do it in 1.3 days. Connect it via NVMe, and it comes down to about a day. Even in that case, it’s still a lot longer than the time it takes to read from memory. Which is one of the main reasons why your computer performs so badly when it starts paging (swapping memory pages out to disk). We’ll all just sit around for days and wait for you to get back to us…
In the context of a distributed system, as networks get faster, you might start to wonder if it makes more sense to page out not to disk, but to under-utilised memory of some other node in the cluster instead. That’s not an original thought, and several systems have tried it over the years. There are some challenges with knowing where in the cluster space might be available, coordinating page placement, and CPU overheads for managing remote pages. As RDMA (Remote Direct Memory Access) becomes more widely available (e.g., through RoCE), it’s the perfect foundation for network paging. The fastest version of RDMA, called 1-sided RDMA can read/write remote memory without involving the remote CPU at all (zero overhead), and it’s fast: about 23 minutes on our human scale. That sure beats hanging around for days. Today’s paper choice shows how to construct a complete and efficient solution for network paging over RDMA…
Infiniswap opportunistically harvests and transparently exposes unused memory to unmodified applications by dividing the swap space of each machine into many slabs and distributing them across many machine’s remote memory. Because one-sided RDMA operations bypass remote CPUs, Infiniswap leverages the power of many choices to perform decentralized slab placements and evictions.
Infiniswap presents itself to the OS as a virtual block device so it can be slotted underneath an existing OS with no changes required to the OS or to the applications that run on top of it. (Prior proposals for network paging have called for new architectures, hardware designs, or programming models).
In theory, and in practice
This all sounds great in theory, but for it to work well in practice we need a couple of prerequisites to be met:
- There must be a memory imbalance across cluster nodes, such that when one node wants to page, there’s a good chance of finding available space elsewhere in the cluster
- Memory utilisation at individual nodes must remain relatively stable over short time periods so that sensible placement decisions can be made.
The good (?) news is that analysis of two large production clusters (one from Google, and one from Facebook) shows that more than 70% of the time there are severe imbalances in memory utilisation across machines. Furthermore, memory utilisation does indeed remain relatively stable in short periods. In the Facebook cluster for example, the probability that the memory utilisation at a node will not change by more than 10% in the next 10 seconds is 0.74 (0.58 for 20 seconds, 0.42 for 40 seconds).
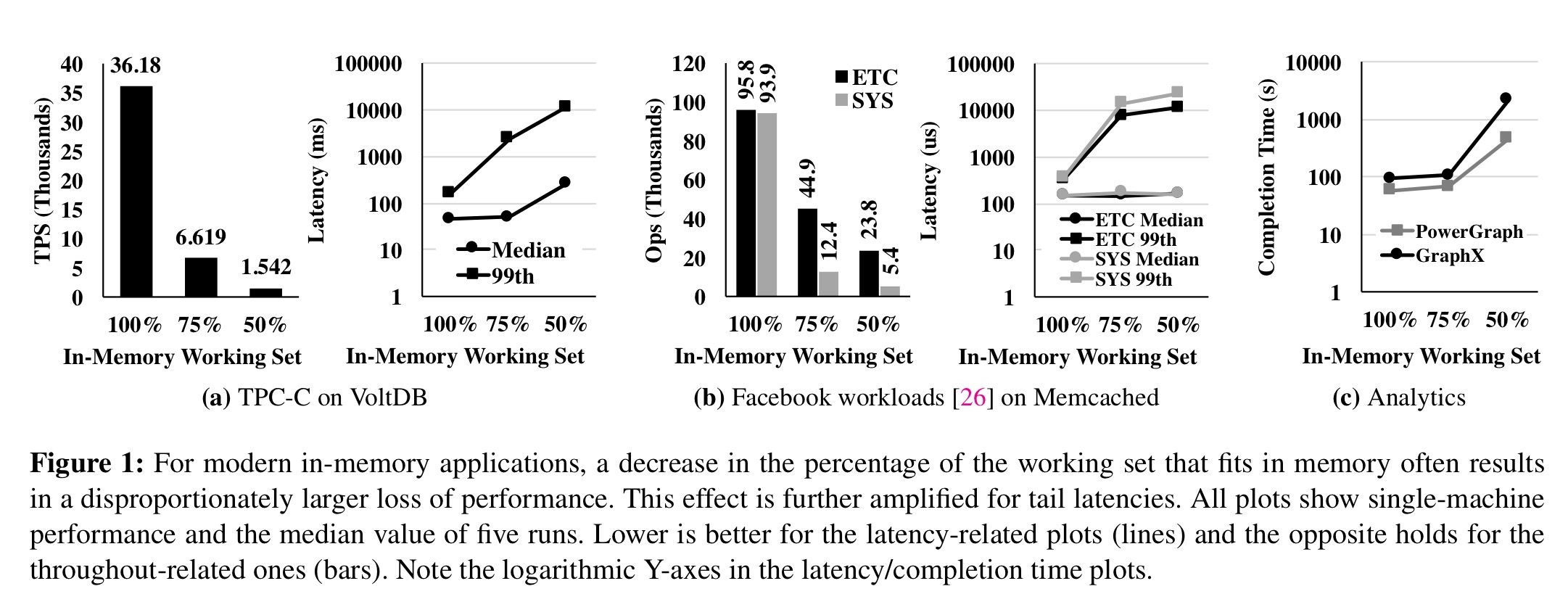
An analysis of VoltDB, Memcached, PowerGraph, and GraphX workloads shows that the potential benefits of improved paging should be very significant. Paging (as we all know from personal experience) has a significant non-linear impact on performance – for example, a 25% reduction in working set size for VoltDB and Memcached in the tests resulted in a 5.5x and 2.1x loss in throughput respectively. At the tail the impact is even worse – 99th percentile latencies increase by 71.5x and 21.5x respectively (and median latencies by 5.7x and 1.1x).
 )
)
These gigantic performance gaps suggest that a theoretical, 100%-efficient memory disaggregation solution can result in huge benefits… it also shows that bridging some of these gaps by a practical, deployable solution can be worthwhile.
So does Infiniswap result in big improvements in practice? Yes! On a 56 Gbps, 32-machine RDMA cluster using Infiniswap, the team evaluated VoltDB, Memcached, PowerGraph, GraphX, and Apache Spark workloads. Infiniswap delivers order of magnitude improvements in throughput and tail latency:
Using Infiniswap, throughputs improve between 4x and 15.4x over disk, and median and tail latencies by up to 5.4x and 61x respectively.
Memory heavy workloads see very limited performance difference even when paging, whereas CPU-heavy workloads do still experience some degradation under paging.
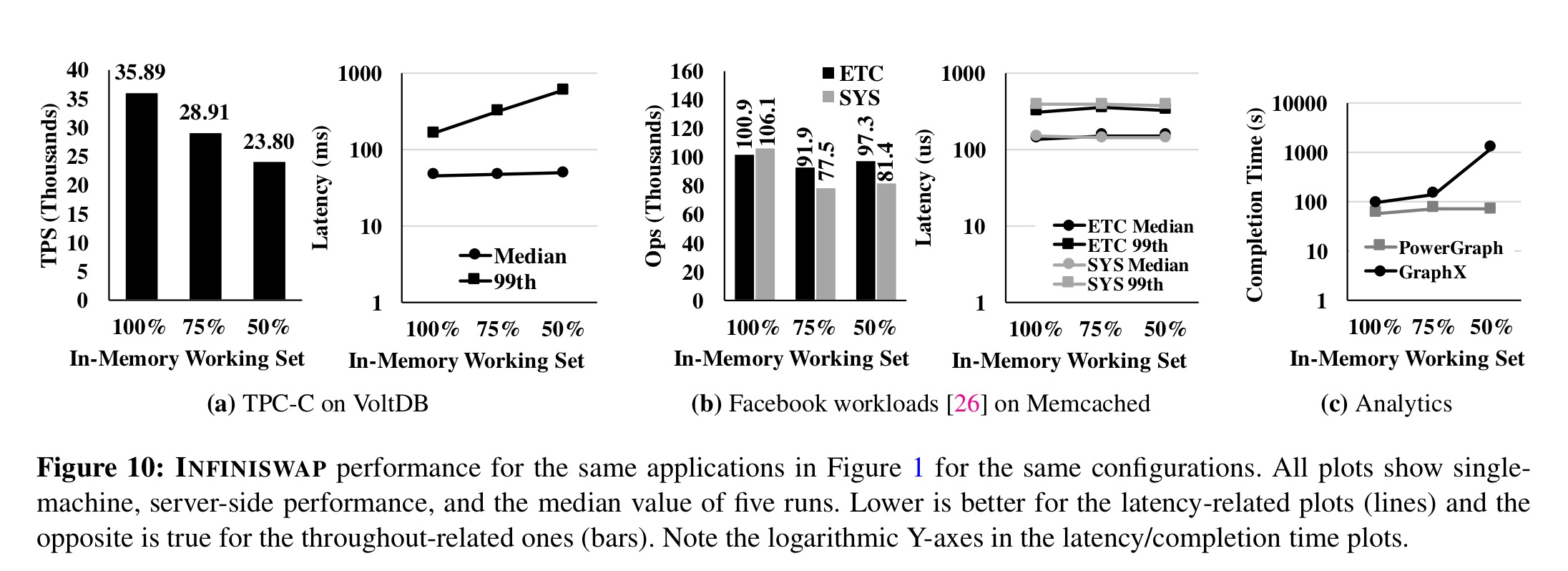
Infiniswap also increased cluster memory utilization by 1.47x (up to 60% from an average 40.8% without Infiniswap). That’s a big one of one of your most expensive resources. The maximum-to-minimum memory utilisation (imbalance) decreased from 22.5x to 2.7x. The overall performance gains of Infiniswap as seen by an application with 100%, 75%, and 50% respectively of its working set fitting in memory can be seen in the results below:

How Infiniswap works
The main goal of Infiniswap is to efficiently expose all of a cluster’s memory to user applications without any modifications to those applications or the OSes of individual machines. It must also be scalable, fault-tolerant, and transparent so that application performance on remote machines remains unaffected.
Infiniswap has two main components, present on every machine: a block device and a daemon. Each machine makes independent decisions with no central coordination.
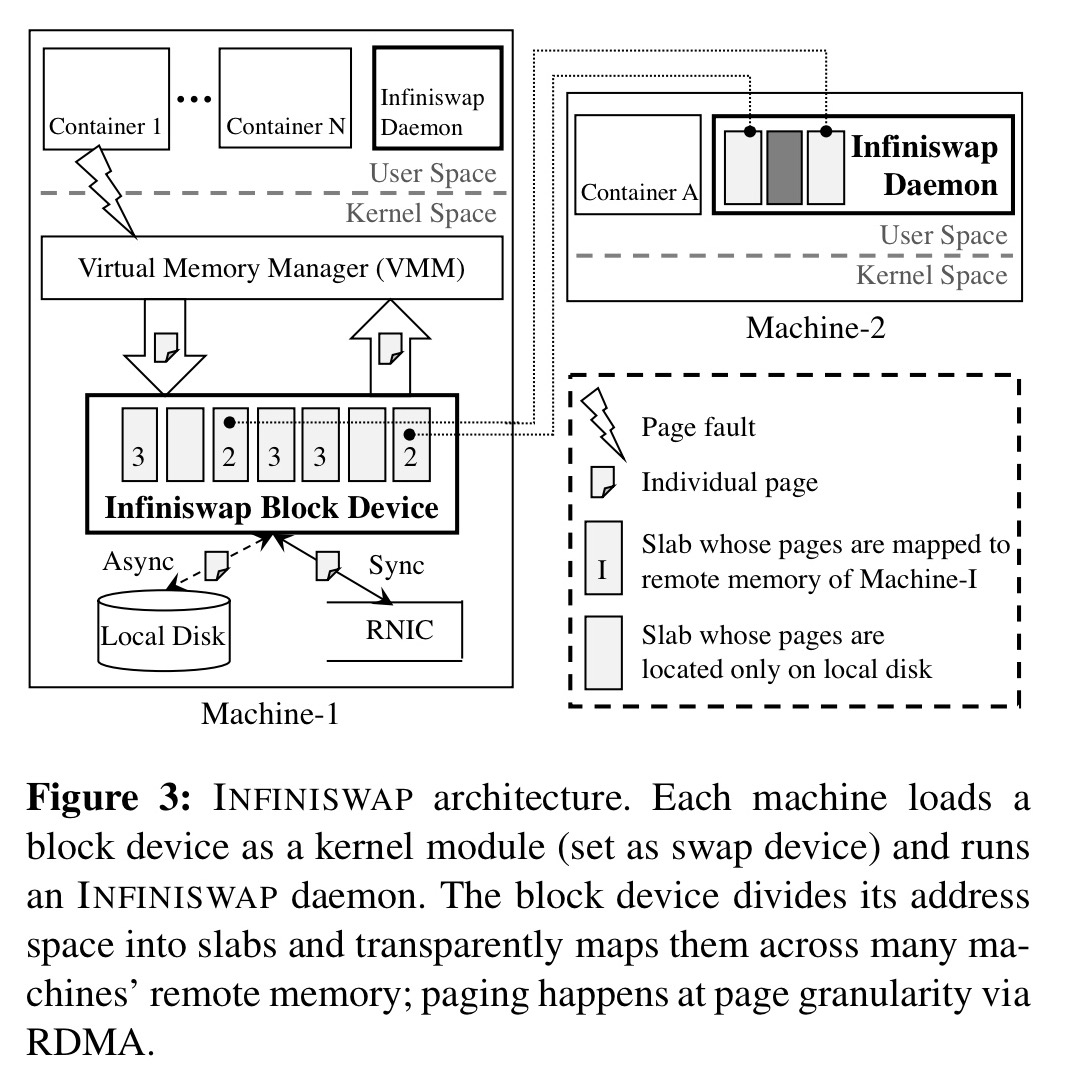
The block device exposes a conventional block device I/O interface to the Virtual Memory Manager (VMM) which treats it as a fixed-size swap partition. The address space is partitioned into slabs, which are the unit of remote mapping and load balancing. Slabs from the same device can be mapped to multiple remote machines’ memory for performance and load balancing. Slabs contain pages. All pages belonging to the same slab are mapped to the same remote machine.
You can think of the remote memory pages as a form of caching, since Infiniswap also always writes (asynchronously) to disk. When a slab is mapped to remote memory, page-out requests for its pages are written to remote memory with RDMA write, and also asynchronously written to local disk. For page-in requests, Infiniswap will read from remote memory if the slab is mapped, otherwise it reads from local disk.
The Infiniswap daemon manages the Infiniswap control plane: responding to slab mapping requests and managing local memory.
Because Infiniswap does not have a central coordinator, it does not have a single point of failure. If a remote machine fails or becomes unreachable, Infiniswap relies on the remaining remote memory and the local backup disk (§4.5). If the local disk also fails, Infiniswap provides the same failure semantic as of today
How does Infiniswap manage without a central coordinator? To understand that, we need to look at the memory management, slab management and placement algorithms…
Deciding when to remotely map a slab
The decision to remotely map a slab can be made entirely locally to the machine that owns it. Infiniswap keeps an exponentially weighted moving average of page activity on a one second basis. Slabs that exceed 20 page I/O requests/second are considered ‘hot’ and marked for remote mapping.
Deciding where to remotely map a slab
We want to map a slab to multiple remote machines to minimise impacts of future evictions, and we also want to balance memory utilisation across the cluster. Selecting a remote choice uniformly at random is known to cause load imbalance. So Infiniswap builds on a result known as “the power of two choices” to minimise memory imbalance. The basic steps are as follows:
- Divide all the machines into two sets, those that already have a slab of this block device (M_old), and those that do not (M_new). We know this locally of course.
- Contact two Infiniswap daemons, choosing first from M_new and then from M_old if needed, and ask for their current memory usage.
- Map the slab to whichever of these two has the lowest memory usage.
Why two choices? The 2001 paper “The power of two choices in randomized load balancing” by Michael Mitzenmacher contains a good explanation, with the key result being this:
Systems where items have two (or a small number of) choices can perform almost as well as a perfect load balancing system with global load knowledge. Indeed, because a system based on two choices can have significantly lower overhead, it is possible it may perform better than apparently better but more complicated load balancing algorithms.
Making space for remote slabs
The Infiniswap daemon monitors the total memory usage on its local machine with a one-second period estimated weighted moving average. It focuses on maintaining a HeadRoom (8 GB by default, ideally dynamically determined) of free memory in the machine by controlling its own total memory allocation.
When the amount of free memory grows above HeadRoom, Infiniswap proactively allocates slabs and marks them as unmapped.
Evicting slabs
When free memory falls below HeadRoom, the daemon releases slabs in two stages. Firstly, any allocated but unmapped slabs are released. Then if that’s not enough, it evicts E mapped slabs. Choosing which E of course is the tricky part!
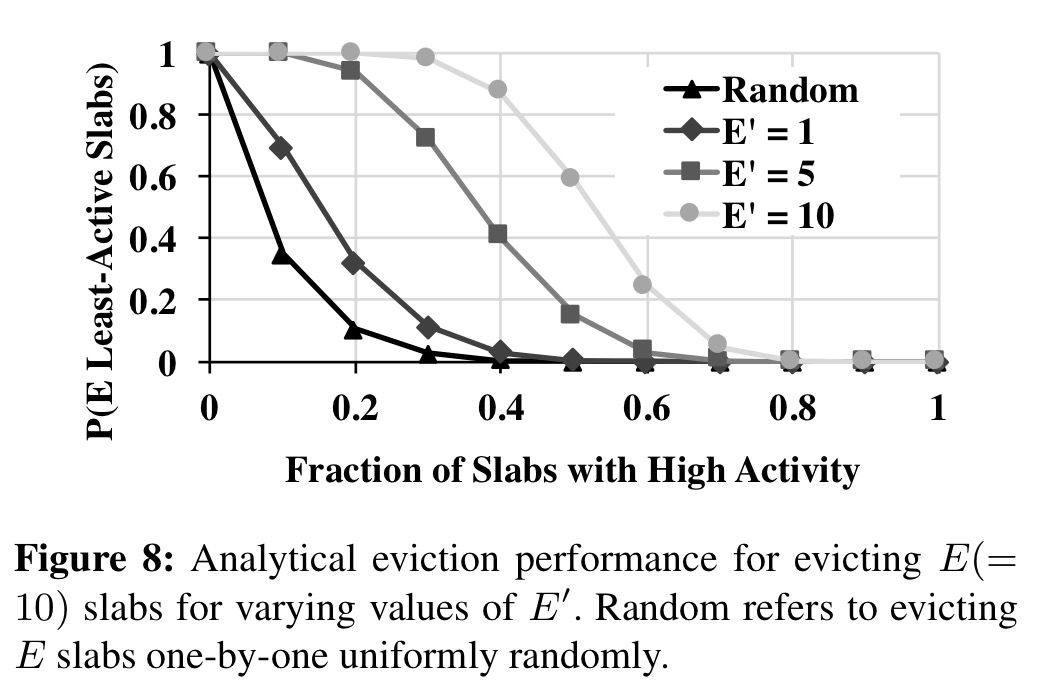
One (expensive) solution would be to contact each remote host with a slab mapped to the machine to find out how active they are (recall that remote slabs are accessed directly with no local involvement so the local daemon doesn’t know). Randomly picking slabs, especially in busy clusters, doesn’t work out too well either. Instead we use the power of [a few] choices once more:
- Given a desire to evict E slabs, select E + E’ candidates, where E’ ≤ E.
- Contact the machines hosting those slabs to find out how active they are
- Evict the E least active ones
Figure 8 [below] plots the effectiveness of batch eviction for different values of E’ for E = 10. Even for moderate cluster load, the probability of evicting lightly active slabs is significantly higher using batch eviction.

What if local machine updates remote slab activity metadata (say the same page io/s metric) during paging, so it can be used to rank slabs for eviction on remote locally?