Chronix: Long term storage and retrieval technology for anomaly detection in operational data Lautenschlager et al., FAST 2017
Chronix (http://www.chronix.io/ ) is a time-series database optimised to support anomaly detection. It supports a multi-dimensional generic time series data model and has built-in high level functions for time series operations. Chronix also a scheme called “Date-Delta-Compaction” (DDC) for timestamps as well as data compression.
On real-world operational data from industry and on queries that analyze these data, Chronix outperforms general-purpose time series databases by far. With a small memory footprint, it saves 20%-68% of the storage space, and it saves 80%-92% on data retrieval time and 73%-97% of the runtime of analyzing functions.
Time series requirements for anomaly detection
To support anomaly detection over time series, the authors cite three key requirements:
- a generic data model that allows exploratory analysis over all types of operational data
- built-in analysis functions
- time and space efficient lossless storage.
Chronix supports all three (surprise!), whereas other popular time series databases are lacking in one or more dimensions:
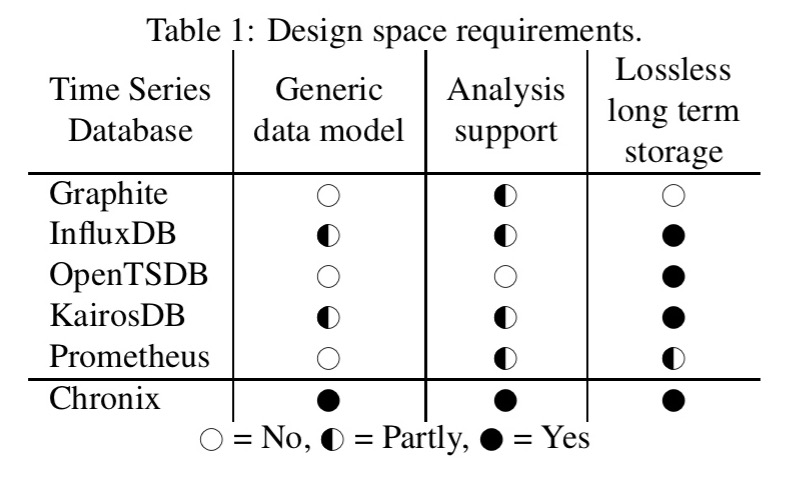
… while the traditional time series databases support explorative and correlating analyses on scalar values, they often fail to do so efficiently for generic time series data (e.g. logs, traces, etc.). InfluxDB also supports strings and booleans, KairosDB is extensible with custom types. Both lack operators and functions and hence only party fulfil the requirements.
In table 2 below you can see that in addition to basic query functions supported by many of the databases, Chronix also has built-in support for higher level functions such as SAX, Dynamic Time Warping, outlier detection and so on. Without built-in support, these functions have to be hand-built on top of the database in the other stores. This gives Chronix a significant speed advantage.

Data model
Chronix stores ordered chunks of time series data (timestamp and value pairs) of arbitrary type in blobs. Type information defines the available functions over the data. Each such blob is called a record and also has two timestamps for the start and end of the time range covered by the chunk, together with a set of user defined attributes (for example, for recording the origin of the data).

Chronix builds on top of Apache Solr , and queries are solr queries which may also reference Chronix functions.
Storage model
The storage model is described as “functionally-lossless.” By this the authors mean that anything useful for anomaly detection is preserved. A user can specify for example that logging statements from an application framework (vs from the application code itself) will never be of interest, in which case these are not kept. A second example of functional-lossless storage is the timestamp approximation through Date-Delta-Compaction that we’ll look at shortly.
The overall flow of Chronix’s pipeline has four main staging (plus a Chronix Ingester that performs input buffering):
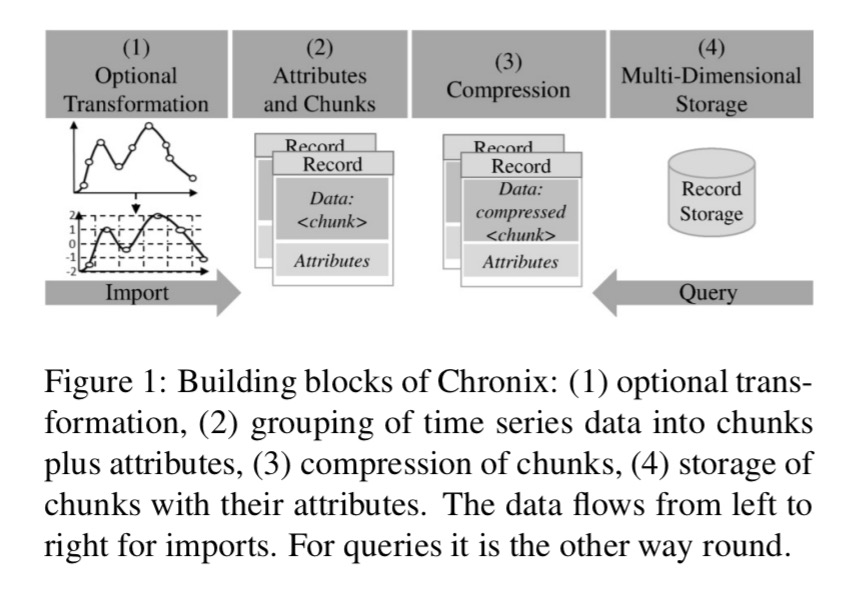
The Optional Transformation can enhance or extend what is actually stored in addition to the raw data, or instead of it. The goal of this optional phase is an optimized format that better supports use-case specific analyses. For example, it is often easer to identify patterns in time series when a symbolic representation is used to store the numerical values.
Compression is in three stages: first the time series values can be compressed as there are often only small changes between subsequent data points; secondly the timestamps themselves can be compressed, and then finally the resulting binary data fields can be run through a standard compression algorithm. The first two forms of compression seem to be a (simpler?) variation on the compression that we looked at for Facebook’s Gorilla (now available in open source as Beringei). See also the delta-delta coding used by BTrDB.
Chronix’ Date-Delta-Compaction (DDC) for timestamps exploits the fact that it its domain the exact timestamps do not matter than much, at least if the difference between the expected timestamp and the actual timestamp is not too large.
Chronix will drop timestamps if it can almost exactly reproduce them. A timestamp is considered reproduceable if the expected next timestamp and actual next timestamp differ by less than some configurable threshold. DDC also keeps track of the accumulated drift and stores a correcting delta if ever it gets too large.
Binary data fields are compressed using a configurable compression algorithm (because different algorithms work better with different data sets). The available choices are bzip2, gzip, LZ4, Snappy, and XZ. You can also plugin your own should you so wish.
Chronix is based on Apache Solr as both the document-oriented storage format of the underlying reverse-index Apache Lucene and the query opportunities match Chronix’ requirements. Furthermore Lucene applies a lossless compression (LZ4) to all stored fields in order to reduce the index size and Chronix inherits the scalability of Solr as it runs in a distributed mode called SolrCloud that implements load balancing, data distribution, fault tolerance, etc.
Configuration tuning (commissioning)
Deploying an instance of Chronix means choosing three key parameter values: the DDC threshold, the chunk size, and the compression algorithm. Chronix supports the administrator in finding suitable values for these parameters.
DDC threshold selection is based on a plot that compares inaccuracy rates against average deviations of timestamps for different threshold values. The inaccuracy rate is the percentage of inaccurately reconstructed timestamps, and the average deviation shows how far those inaccurate timestamps are from the actual values, on average.
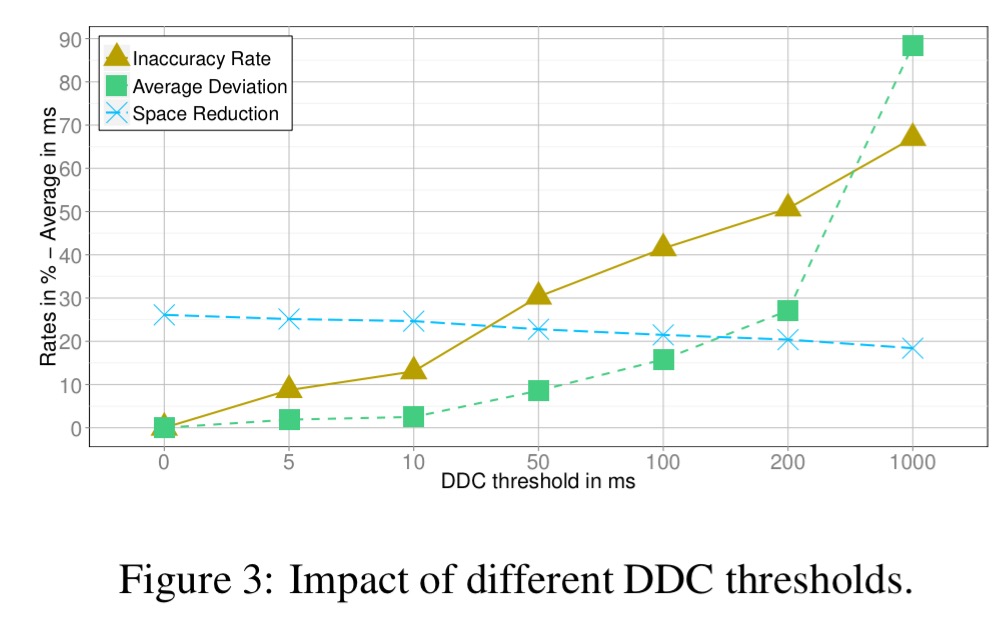
The default DDC threshold is set to 200ms by experimentation.
Chunk size and compression technique are selected in tandem. First a minimal chunk size is found by looking at the chunk size where compression rate saturates across a range of algorithms:
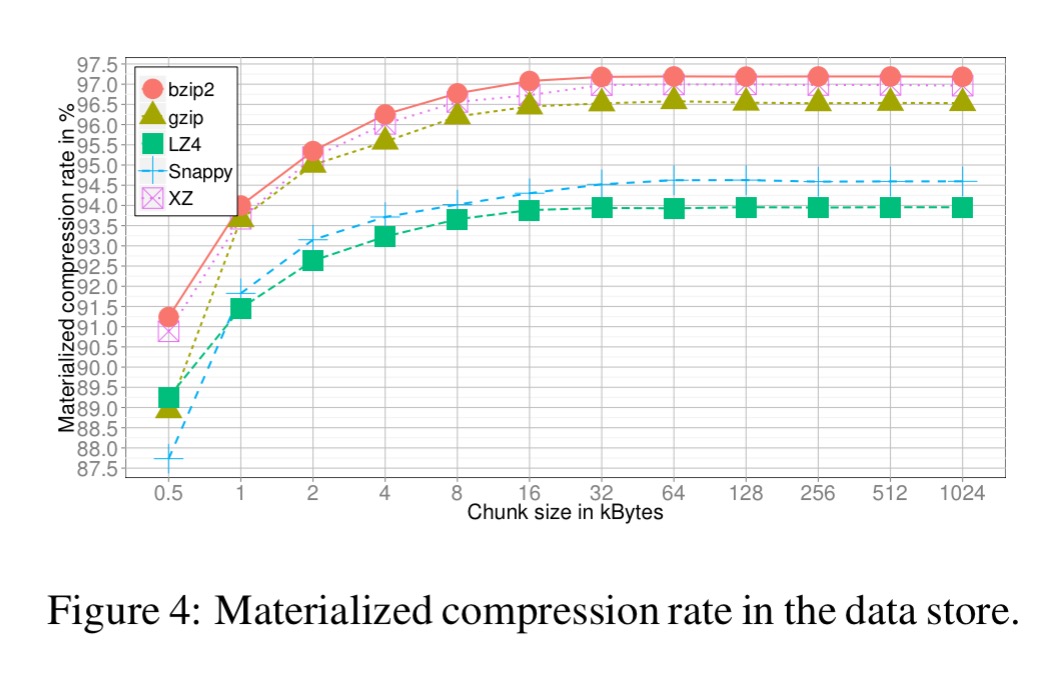
Then for a range of chunk size above the found minimum, tests are run to see how long it takes to find a record, ship it to the client, and reconstruct the raw data. Compression techniques with a slow average access to single records are dropped at this stage (e.g. XZ and bzip2 in the plot below):
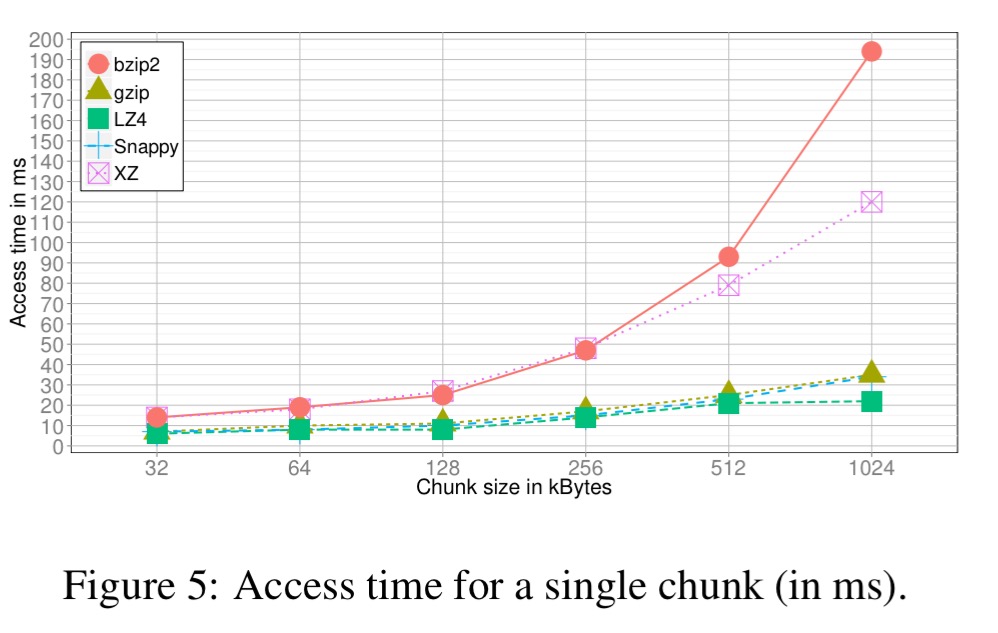
Finally the system considers all combinations of the remaining compression techniques and chunk sizes to select the best one.
Evaluation
The evaluation compares Chronix to InfluxDB, OpenTSDB, and KairosDB using 108 GB of operational data from two real-world applications. You can see that Chronix has a much smaller memory footprint, as well as significantly reduced storage requirements:

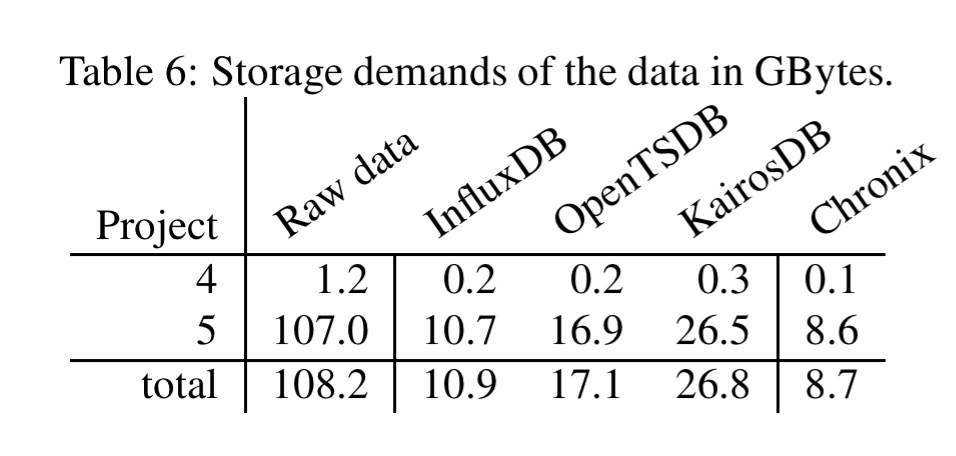
Chronix only needs 8.7GB to store the 108.2GB of raw time series data. Compared to the general purpose time series databases Chronix saves 20%-68% of the storage demand.
Table 8 below shows the benefits of Chronix’ built-in functions.
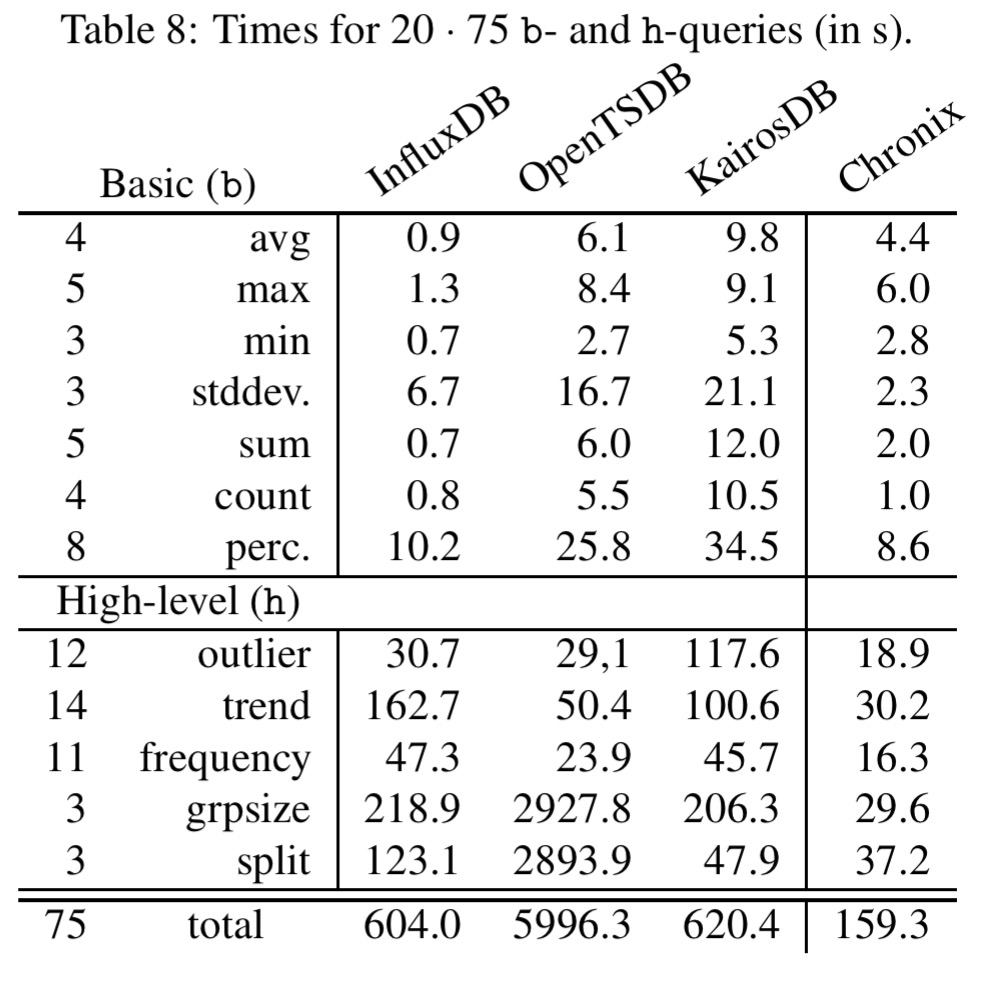

Why did you not compare against Graphite and Prometheus in the last two tables?
The authors exclude them because they don’t consider them suitable for long-term storage:
“As Table 1 shows, the traditional time series databases (except for Graphite due to its round-robin storage, see Section 6) can be used as long term storage for raw data. Their efficiency in terms of domain specific storage demands and query runtimes is insufficient as the evaluation in Section 5 will point out. Prometheus is designed as short-term storage with a default retention of two weeks. Furthermore it does not scale, there is no API for storing data, and it uses hashes for time series iden- tification (the resulting collisions may lead to a seldom loss of a time series value). It is therefore not included in the quantitative evaluation.”
Reminds me of TrailDB, but with a stronger story for querying data.