Enlightening the I/O Path: A holistic approach for application performance Kim et al., FAST ’17
Lots of applications contain a mix of foreground and background tasks. Since we’re at the file system level here, for application, think Redis, MongoDB, PostgreSQL and so on. Typically user requests are considered foreground tasks, and tasks such as housekeeping, checkpointing etc. are run as background tasks. This leads to a challenge of providing consistent low latency responses for user requests in the presence of mixed background workloads.
For example, background checkpointing in relational databases has been known to hinder delivering low and predictable transaction latency, but the database and operating system communities have no reasonable solution despite their collaborative efforts.
(As another example, consider what happens to your JVM when the garbage collector runs).
What about priorities you say? Yes, the solution does involve giving higher priority to critical I/O. What the authors show however is that priority information needs to flow through all layers of the storage stack (caching, file system, block, and device), and that priority inversions (where a high priority I/O ends up waiting on a low priority I/O) also need to be addressed. The request-centric I/O prioritization (RCP) scheme that they introduce does both.
This somewhat messy chart illustrates the point well. Here you’re looking at MongoDB running an update heavy YCSB workload. The grey line is the default Linux I/O scheduler (CFQ – Completely Fair Queuing), and the green line (CFQ-IDLE) is CFQ with low priority (idle-priority) assigned to the checkpoint task. SPLIT references variations of the Split-level scheduler (another cross-layer I/O scheduling framework we looked at previously, although it does not consider priority inversions). QASIO does consider priority inversions, but is more limited in scope. Compared to all the other approaches, the throughput with RCP (the black line) is much more consistent, avoiding the large peaks and troughs in the CFQ line for example.
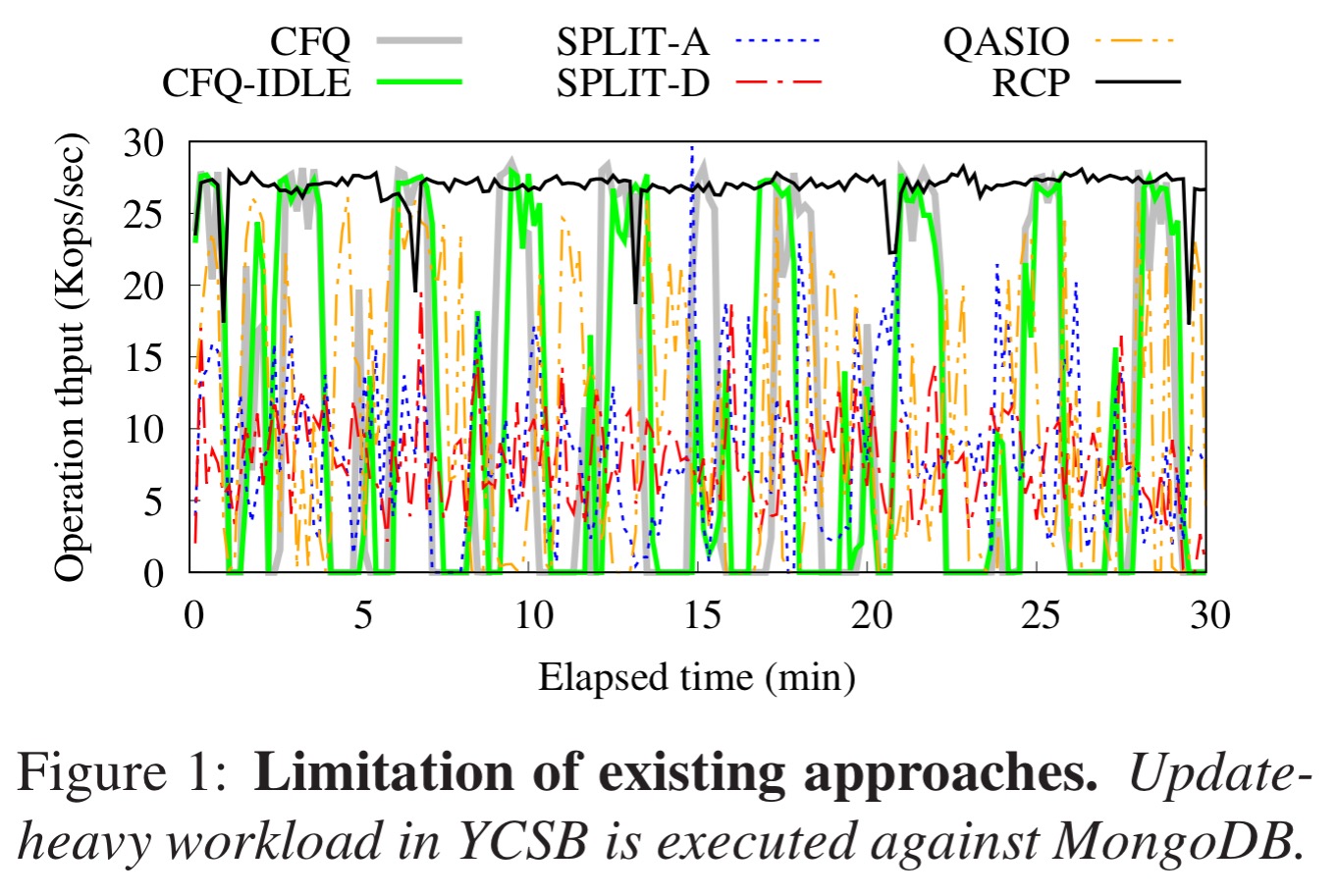
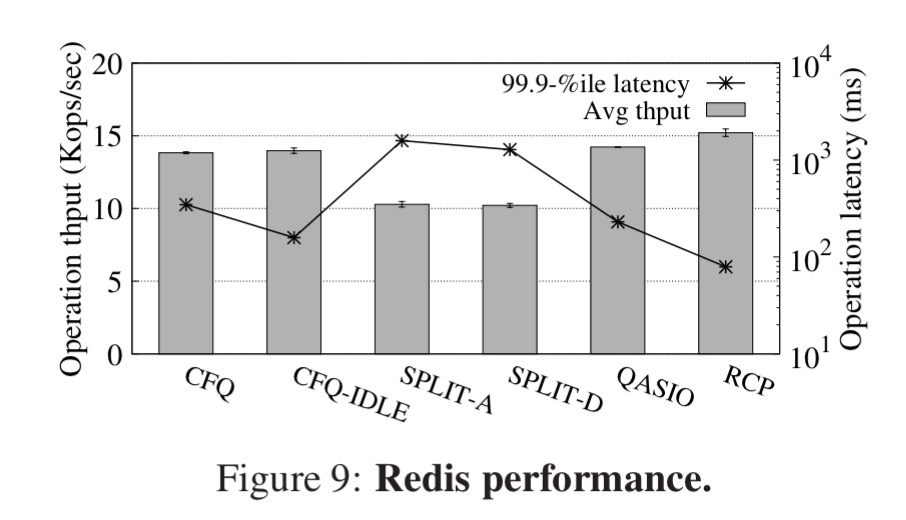
The 3,100 lines of code needed to implement RCP in Linux make a big difference: tested with PostgreSQL, MongoDB, and Redis, RCP delivered up to 53% higher request throughput and 42x better 99%-ile request latency compared to the default configuration in Linux.
Causes of inconsistent performance for requests
The layering in a typical modern storage stack is shown in the figure below (centre and left). Priority agnostic admission control in the caching and block layers can degrade application performance. In the file system layer fate sharing of buffered writes in a single global compound transaction can leave foreground tasks waiting on background task I/O. Shared block level queues in the block layer also mean that a burst of background I/Os can delay foreground I/O by filling the queue. There is further re-ordering at the device level due to the limited size of device internal queues and firmware reordering. What we really need instead is an end-to-end view of I/O priority that can be taken into account at each layer.
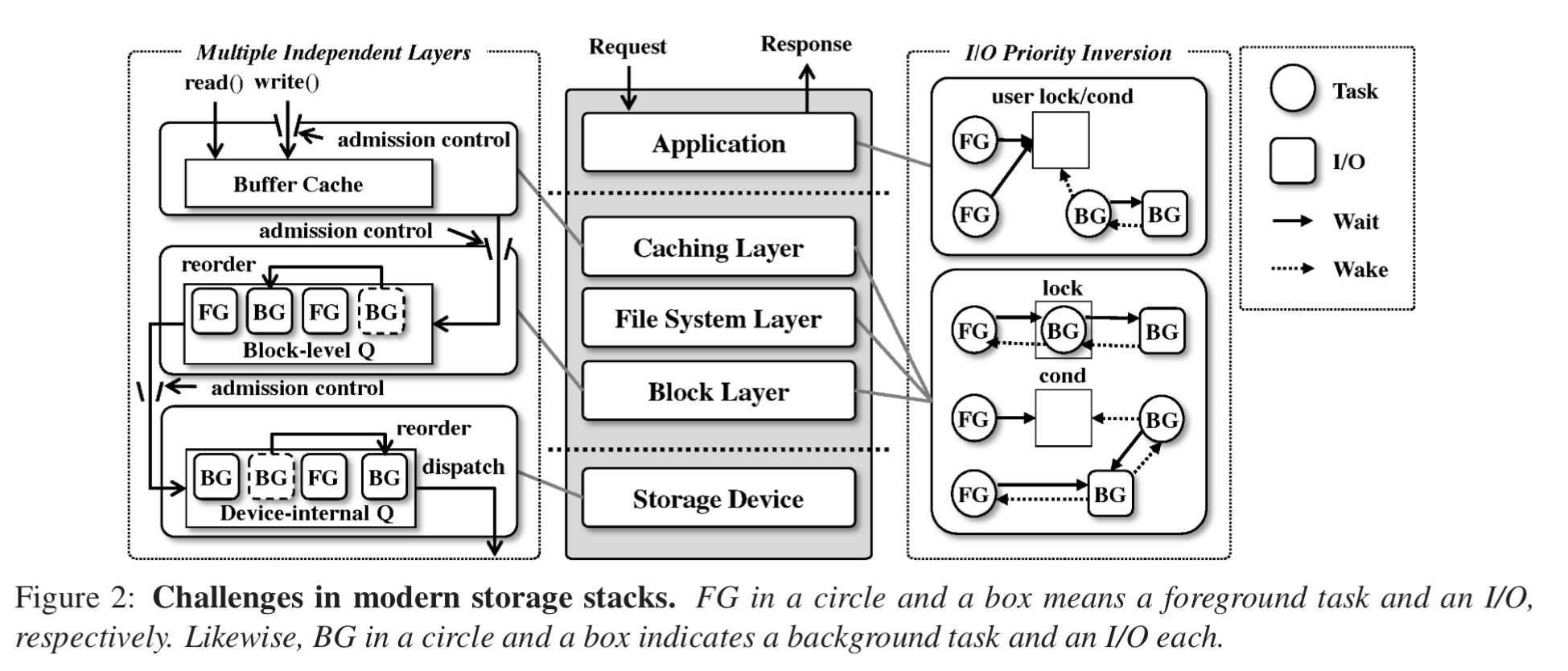
Priority inversions (right-hand side of the figure above) comes in two flavours: task dependencies and I/O dependencies. A task dependency arises when two tasks interact with each other via synchronisation primitives such as locks and condition variables.
The dependency caused by a lock complicates effective I/O prioritization because a background task can be blocked waiting for an I/O within a critical section that a foreground task needs to enter. For instance, a foreground task attempting to write a file can be blocked on an inode mutex if the mutex is already held by a background task concurrently writing to the different part of that file.
I/O dependencies occur when a task needs to wait for the completion of an existing I/O in order to ensure correctness and/or durability. For example, a foreground fsync call may be blocked waiting for completion of a write from a kernel thread cleaning buffer caches.
Once the task and the I/O induced priority inversions occur, the foreground task could wait for a long time because each layer in the I/O path can arbitrarily prolong the processing of low-priority background I/Os.
Dealing with I/O priority inversions is made more challenging for two key reasons: (i) dependency relationships may depend on runtime conditions, such that they can’t be statically determined, and (ii) dependency occurs in a transitive manner involving multiple concurrent tasks blocked at either synchronization primitives or I/O stages in multiple layers.
How enlightenment works
Whereas typical approaches to prioritisation tend to choose either an I/O centric approach, favouring synchronous I/O over asynchronous, or a task centric approach favouring foreground I/O over background I/O, RCP instead takes a request centric approach.
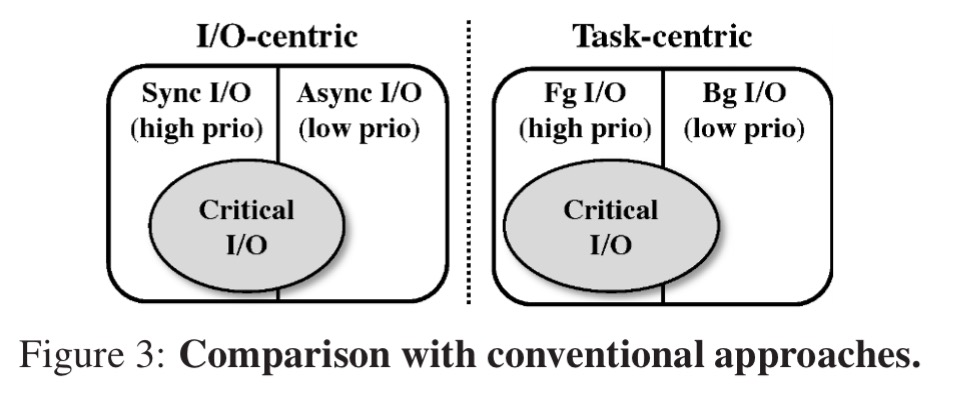
It’s closest in spirit to a task-centric approach, but also allows background tasks of lower priority to become high priority when priority inversions are detected.
RCP classifies I/Os as critical and non-critical, finding that these two priorities are sufficient to obtain good performance. A critical I/O is one that is in the critical path of request handling (i.e., it can directly affect the response time). The process begins by tracking the set of tasks involved in request handling, and the simple solution to this is minimal application instrumentation. It took 15, 14, and 2 lines of code to add the necessary tagging to PostgreSQL, MongoDB, and Redis, respectively.
With foreground tasks tagged at initiation, the next step is to handle priority I/O inversions caused by runtime dependencies.
Inspired by previous work on CPU scheduling, we resolve the lock-induced dependency by inheriting critical I/O priority in a background task when it blocks a foreground task until it leaves a critical section.
Tasks that signal condition variables are labelled as helper tasks. A helper task will inherit the priority of any critical task blocked to wait for the condition to become true. In the kernel this is viable because there are only a few condition variables and associated threads.
Unlike the condition variable-induced dependency in kernel-level, handling such dependency in user-level is difficult because it is hard to pinpoint helper tasks for condition variables. Modern applications extensively use user-level condition variables for various purposes. For instance, we found over a hundred of user-level condition variables in the source code of MongoDB. Therefore, properly identifying all helper tasks is not trivial even for an application developer.
The pragmatic solution is based on the assumption that if a task signals a condition once, it is likely to do so again in the future, and can therefore be tagged as a helper task.
Resolving dependencies to outstanding I/Os is achieved by tracking all non-critical I/Os in the block level queue. If a dependency occurs, it is bumped to critical.
With an understanding of critical and non-critical I/Os in place through a combination of initial tagging and priority inversion detection, the final piece of the puzzle is adapting each layer to make it understand and enforce the I/O criticality.
- In the caching layer, separate dirty ratios are applied to tasks issuing critical and non-critical writes (much lower for non-critical writes). This prevents background tasks from filling all the available space when a burst of background writes arrives.
- In the block layer, admission control is also modified to have separate slots for critical and non-critical I/Os. A similar priority-based I/O scheduler is also employed at this layer.
- In order to minimise interference at the device level, the number of non-critical I/Os dispatched to a storage device is conservatively limited.
See sections 4.3 and 4.4 in the paper for the full details.
Results
The scheme was implemented in 3100 lines of code and tested with PostgreSQL, MongoDB, and Redis.
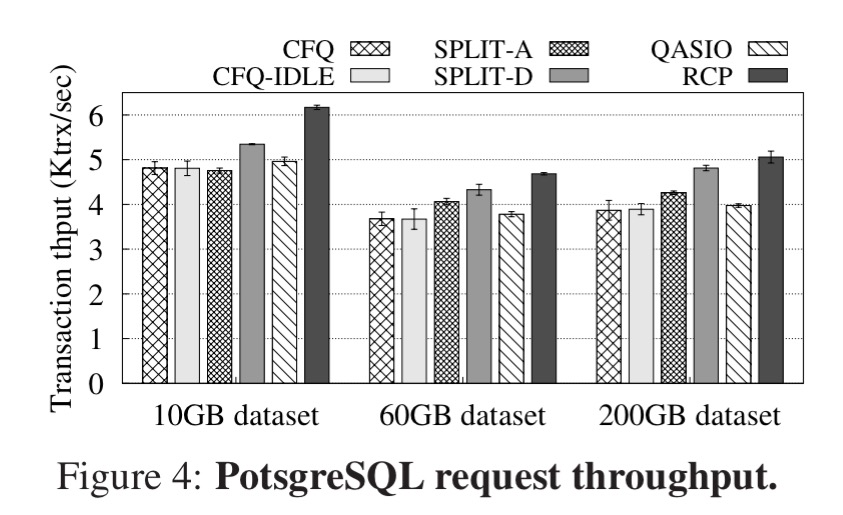
RCP improves throughput in all three systems. For example, with PostgreSQL RCP outperforms existing schemes by 15-37% (10GB dataset), 8-28% (60GB dataset), and 6-31% (200GB dataset).
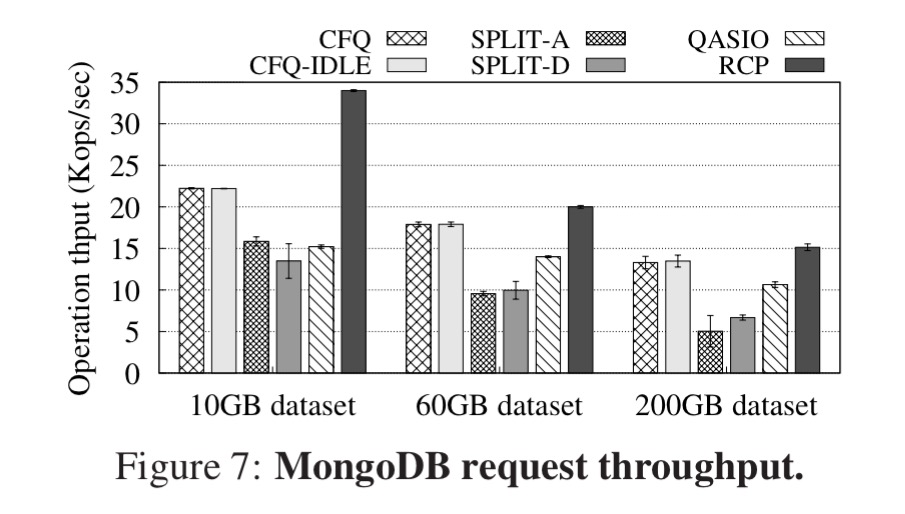
In order to show the effectiveness of RCP in terms of request latency, we ran a rate-controlled TPC-C workload (i.e., fixed number of transactions) with 100 scale factor. Figure 6 demonstrates a complementary cumulative distribution function (CCDF), and so the point (x,y) indicates that y is the fraction of requests that experience a latency of at least x ms. This form of representation helps visualizing latency tails, as y-axis labels correspond to the 0th, 90th, 99th (and so on) percentile latencies.
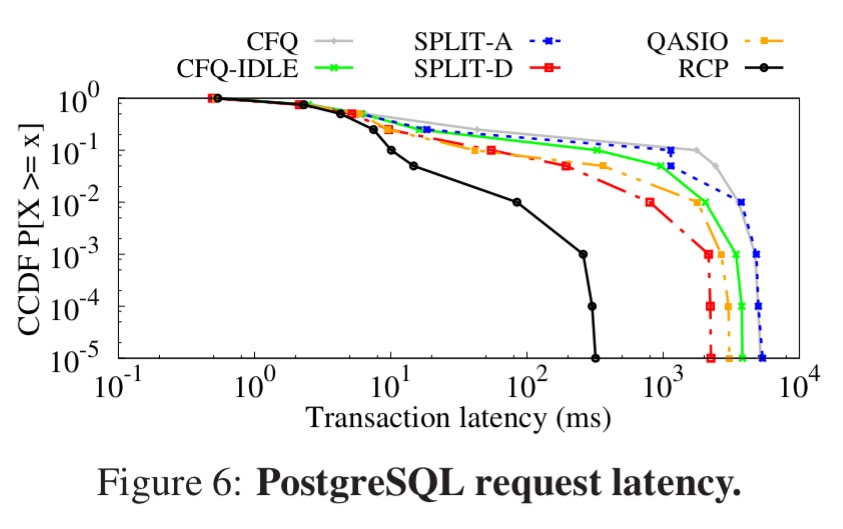
You can clearly see in the figure above that RCP does a much better job of curtailing tail latencies.
Here’s a similar chart for MongoDB using a YCSB workload:
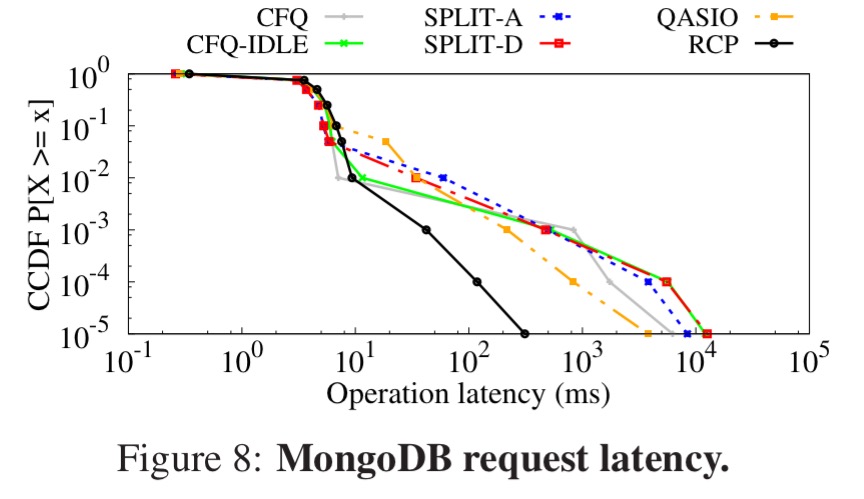
The authors also conduct an interesting experiment in which they selectively disable just one layer’s components in the scheme at a time, which fully supports the end-to-end argument by revealing that disabling the optimisation at any one layer degrades overall application throughput by 7-33% and 6-45% for PostgreSQL and MongoDB respectively.
The results all look great, but there’s just one snag:
Our prototype implementation involves modifications to all the layers and the synchronization methods in the I/O path, thereby hindering our scheme from wide adoption. The most promising direction to be practically viable is exploiting the Split framework. It provides a collection of handlers for an I/O scheduler to operate across all layers in the I/O path. We believe our scheme can be cleanly implemented based on the framework by controlling non-critical writes at the system-call level, before the caching and file system layer generates complex dependencies, and non-critical reads at the block-level.
We covered the Split framework on The Morning Paper at the tail end of 2015.

Hi, do you know if any of advancements outlined in the paper ended up in mainline Linux kernel?
Typo should be “if” in “assumption that is a task signals”. I can recommend the Grammarly plug-in for WordPress as a good typo spotter. Thanks for the great morning papers.
Fixed, thank you :).
This type of optimization could add a big boost to HPC tasks.
Hi, do you know if any of advancements outlined in the paper ended up in mainline Linux kernel? Thanks for the great morning papers.
I can recommend the Grammarly plug-in for WordPress as a good typo spotter. Typo should be “if” in “assumption that is a task signals”.
Typo should be “if” in “assumption that is a task signals”. Fixed, thank you :).
I can recommend the Grammarly plug-in for WordPress as a good typo spotter. Fixed, thank you :).
I can recommend the Grammarly plug-in for WordPress as a good typo spotter. Fixed, thank you :).
Fixed, thank you :). I can recommend the Grammarly plug-in for WordPress as a good typo spotter.
Typo should be “if” in “assumption that is a task signals”. This type of optimization could add a big boost to HPC tasks.