The SNOW theorem and latency-optimal read-only transactions Lu et al., OSDI 2016 Consider a read-only workload (as in 100%). You can make that really fast - never any need to coordinate, never any need to invalidate any cached values… Now consider a write-only workload - you can make that even faster, if no-one’s ever going … Continue reading The SNOW theorem and latency-optimal read-only transactions
Year: 2016
REX: A development platform and online learning approach for runtime emergent software systems
REX: A development platform and online learning approach for runtime emergent software systems Porter et al. OSDI 2016 If you can get beyond the (for my taste, ymmv) somewhat grand claims and odd turns of phrase (e.g., “how the software ‘feels’ at a given point in time” => metrics) then there’s something quite interesting at … Continue reading REX: A development platform and online learning approach for runtime emergent software systems
Slicer: Auto-sharding for datacenter applications
Slicer: Auto-sharding for datacenter applications Adya et al. (Google) OSDI 2016 Another piece of Google's back-end infrastructure is revealed in this paper, ready to spawn some new open source implementations of the same ideas no doubt. Slicer is a general purpose sharding service. I normally think of sharding as something that happens within a (typically … Continue reading Slicer: Auto-sharding for datacenter applications
Morpheus: Towards automated SLOs for enterprise clusters
Morpheus: Towards automated SLOs for enterprise clusters Jyothi et al. OSDI 2016 I'm really impressed with this paper - it covers all the bases from user studies to find out what's really important to end users, to data-driven engineering, a sprinkling of algorithms, a pragmatic implementation being made available in open source, and of course, … Continue reading Morpheus: Towards automated SLOs for enterprise clusters
Firmament: Fast, centralized cluster scheduling at scale
Firmament: Fast, centralized cluster scheduling at scale Gog et al. OSDI' 16 Updated link to point to official usenix hosted version As this paper demonstrates very well, cluster scheduling is a tricky thing to get right at scale. It sounds so simple on the surface: "here are some new jobs/tasks - where should I run … Continue reading Firmament: Fast, centralized cluster scheduling at scale
Early detection of configuration errors to reduce failure damage
Early detection of configuration errors to reduce failure damage Xu et al, OSDI '16 Here's one of those wonderful papers that you can read in the morning, and be taking advantage of the results the same afternoon! Remember the 'Simple testing can prevent most critical failures' paper from OSDI'14 that we looked at last month? … Continue reading Early detection of configuration errors to reduce failure damage
Kraken: Leveraging live traffic tests to identify and resolve resource utilization bottlenecks in large scale web services
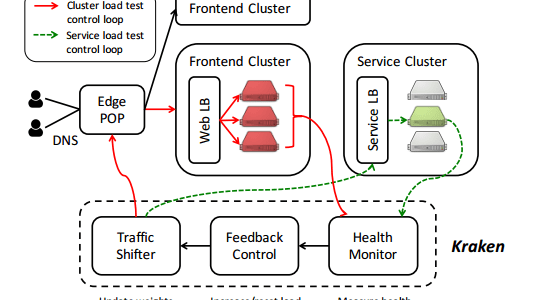
Kraken: Leveraging live traffic tests to identify and resolve resource utilization bottlenecks in large scale web services Veeraraghavan et al. (Facebook) OSDI 2016 How do you know how well your systems can perform under stress? How can you identify resource utilization bottlenecks? And how do you know your tests match the condititions experienced with live … Continue reading Kraken: Leveraging live traffic tests to identify and resolve resource utilization bottlenecks in large scale web services
Building machines that learn and think like people
Building machines that learn and think like people Lake et al., arXiv 2016 Pro-tip: if you're going to try and read and write up a paper every weekday, it's best not to pick papers that run to over 50 pages. When the paper is as interesting as "Building machines that learn and think like people" … Continue reading Building machines that learn and think like people
Smart Reply: Automated response suggestion for email
Smart Reply: Automated response suggestion for email Kannan, Kaufman, Karach, et al. KDD 2016 I’m sure you’ve come across (or at least heard of) Google Inbox’s smart reply feature for mobile email by now. It’s currently used for 10% of all mobile replies, which must equate to a very large number of messages per day. … Continue reading Smart Reply: Automated response suggestion for email
Playing FPS games with deep reinforcement learning
Playing FPS games with deep reinforcement learning Lample et al. arXiv preprint, 2016 When I wrote up ‘Asynchronous methods for deep learning’ last month, I made a throwaway remark that after Go the next challenge for deep learning systems would be to win an esports competition against the best human teams. Can you imagine the … Continue reading Playing FPS games with deep reinforcement learning
