TensorFlow: A system for large-scale machine learning Abadi et al. (Google Brain) OSDI 2016
This is my last paper review for 2016! The Morning Paper will be taking a two week break for the holidays, resuming again on the 2nd January. Sometime inbetween I’ll do a short retrospective on the year. It seems fitting to finish the year with a software system that was released as OSS just over a year ago and has since gathered a lot of mindshare and attention: Google’s TensorFlow.
A large number of groups at Google have deployed TensorFlow in production, and TensorFlow is helping our research colleagues to make new new advances in machine learning. Since we released TensorFlow as open-source software, more than 14,000 people have forked the source code repository, the binary distribution has been downloaded over one million times, and dozens of machine learning models that use TensorFlow have been published.
TensorFlow essentials
A tensor is simply a multi-dimensional array of primitive types. A machine learning system in TensorFlow is represented by a dataflow graph with operators and state at the nodes in the graph, and tensors flowing on the edges between them.
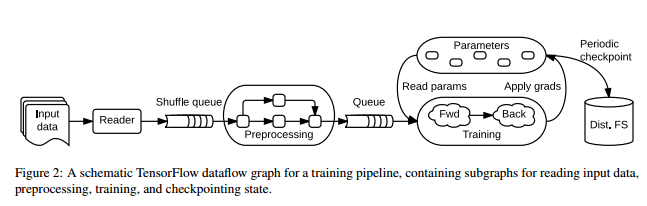
This explicit representation of the computation and the communication between stages makes it easy to partition computation across devices, and to execute independent computations in parallel.
At the system level, all tensors are treated as dense. If you want to model a sparse tensor therefore, you need to encode it somehow at the application level. One option is to encode the data into variable-length string elements in a dense tensor; another option is to use a tuple of dense tensors, the first carrying coordinates, and the second the (non-zero) values at those coordinates.
Operations take one or more tensors as input and produce one or more tensors as output. The attributes of an operation at compile-time determine both the expected types and the arity of inputs and outputs. Operations may contain mutable state that is read and/or written each time it executes. The special Variable operation simply owns a mutable buffer that may be used to store the shared parameters of a model as it is trained. In this way, parameters may be contained within the dataflow itself, rather than being ‘outside’ of the system in a parameter server.
A second type of stateful operator is a queue operator. Queues support more advanced forms of coordination.
The simplest queue is
FIFOQueue, which owns an internal queue of tensors, and allows concurrent access in first-in first-out order. Other types of queues dequeue tensors in random and priority orders, which ensure that input data are sampled appropriately.
Advanced machine learning algorithms may contain conditional and iterative control flow (e.g., RNNs). Given that expressing everything in the dataflow graph is a fundamental tenet of TensorFlow, this control flow also needs to be expressed in the graph. TensorFlow borrows Switch and Merge operations from traditional dynamic dataflow architectures to implement conditionals. Enter, Exit, and Next Iteration operators are used to support looping.
The execution of iterations can overlap, and TensorFlow can also partition conditional branches and loop bodies across multiple devices and processes. The partitioning step adds logic to coordinate the start and termination of each iteration on each device, and to decide the termination of the loop.
It’s the job of the TensorFlow runtime to place operations on devices within task processes. TensorFlow supports CPUs, GPUs, and Google’s own custom ASIC TPUs – Tensor Processing Units. TPUs give an order of magnitude improvement in performance-per-watt compared to the alternative state-of-the-art.
The placement algorithm computes a feasible set of devices for each operation, calculates the set of operations that must be colocated, and selects a satisfying device for each colocation group.
An operation may have multiple kernels registered for it, with specialized implementations for particular devices or data types.
When submitting a graph to the TensorFlow runtime, the user can specify zero or more edges to feed input tensors into the dataflow, and one or more edges to fetch output tensors from. The distributed master prunes the graph to support just what is needed for the given inputs and outputs, partitions it into subgraphs for each participating device, and caches them for reuse in subsequent steps.
Since the master sees the overall computation for a step, it applies standard optimizations such as common subexpression elimination and constant folding; pruning is a form of dead code elimination. It then coordinates execution of the optimized subgraphs across a set of tasks.
For transfers between task processes, TensorFlow can take advantage of multiple protocols including gRPC over TCP, and RDMA over converged Ethernet (RoCE).
TensorFlow differs from standard batch dataflow systems in that:
- the model supports multiple concurrent executions on overlapping subgraphs of the overall graph
- Individual vertices may have mutable state that can be shared between different executions of the graph
Naiad with its Differential dataflow support seems to come close to many of the general dataflow requirements of TensorFlow (without having the specialized operators etc. for ML).
Since Amazon have just blessed MXNet as their deep learning system of choice, it’s interesting to see what the TensorFlow authors have to say about it:
MXNet is perhaps the closest system in design to TensorFlow. It uses a dataflow graph to represent the computation at each worker, and uses a parameter server to scale training across multiple machines. The MXNet parameter server exports a key-value store interface that supports aggregating updates sent from multiple devices in each worker, and using an arbitrary user-provided function to combine incoming updates with the current value. The MXNet key-value store interface does not currently allow sparse gradient updates within a single value, which are crucial for the distributed training of large models, and adding this feature would require modifications to the core system.
History and design rationale
TensorFlow is a successor to a previous Google system called DistBelief which used a parameter server architecture. One of its key goals was to provide much more flexibility to users and hence support rapid experimentation with new algorithms etc..
Making everything part of a dataflow makes it easier for users to compose novel layers using just a high-level scripting interface. Having state in the dataflow graph enables experimentation with different update rules.
Having global information about the computation enables optimization of the execution phase – for example, TensorFlow achieves high GPU utilization by using the graph’s dependency structure to issue a sequence of kernels to the GPU without waiting for intermediate results.
Allowing operations to have multiple kernels enables exploitation of special-purpose accelerators when they are available. This enable a TensorFlow program, for example, to be deployed to a cluster of GPUs for training, a cluster of TPUs for serving, and a cellphone for mobile inference.
Where next?
TensorFlow is a work in progress. Its flexible dataflow representation enables power users to achieve excellent performance, but we have not yet determined default policies that work well for all users. Further research on automatic optimization should bridge this gap. On the system level, we are actively developing algorithms for automatic placement, kernel fusion, memory management, and scheduling.
Fault-tolerance today is supported by user-level checkpointing operations (Save and Restore). A typical configuration connects each Variable in a task to the same Save operation to maximize I/O bandwidth to a distributed file system.
While the current implementations of mutable state and fault tolerance suffice for applications with weak consistency requirements, we expect that some TensorFlow applications will require stronger consistency, and we are investigating how to build such policies at user-level.
TensorFlow was originally designed to support asynchronous training, but new research suggests in some configurations synchnronous training may be faster to get to a certain quality level than asynchronous training, thus the team have begun experimenting with synchronous methods.
Finally, some users have begun to chafe at the limitations of a static dataflow graph, especially for algorithms like deep reinforcement learning. Therefore, we face the intriguing problem of providing a system that transparently and efficiently uses distributed resources, even when the structure of the computation unfolds dynamically.

Reblogged this on HARSHAVARTHAN MARAN.