Arrakis: The Operating System is the Control Plane – Peter et al. OSDI 2014
ACM Queue just introduced their “Research for Practice” series with Peter Bailis. Each edition contains ‘expert curated guides to the best of CS research,’ and in the first instalment Simon Peter selects a set of papers on data-center operating system trends, while Justine Sherry gives her selection on network functions virtualization. A perfect set up for The Morning Paper, thank you! Let’s look at Simon Peter’s paper choices first, which he says:
…establish a new baseline for data-center OS design. Not the traditional Unix model where processes run on top of a shared kernel invoked via POSIX system calls, but protected software containers using scalable library invocations that map directly to hardware mechanisms allowing applications to break out of existing OS performance and protection limitations.
Simon’s four paper choices are Arrakis (today’s paper), ‘IX: a protected dataplane operating system for high throughput and low latency,’ ‘The Scalable Commutativity Rule‘ (previously covered on The Morning Paper), and ‘Shielding applications from an untrusted cloud with Haven.’
First up is Arrakis, which re-examines the role of the kernel in I/O (storage and network) and removes it from the data path for nearly all I/O operations whilst retaining traditional operating system protections. For a Redis workload this resulted in a 2-5x latency improvement and 9x throughput improvement. Recent hardware trends will only serve to magnify kernel overheads and make approaches such as Arrakis ever more attractive.
The combination of high speed Ethernet and low latency persistent memories is considerably raising the efficiency bar for I/O intensive software…these trends have led to a long line of research aimed at optimizing kernel code paths for various use cases. […] Much of this has been adopted in mainline commercial OSes, and yet it has been a losing battle: we show that the Linux network and file system stacks have latency and throughput many times works than that achieved by the raw hardware.
To make the point, the authors jump straight into a breakdown of networking overheads for a simple send/receive UDP echo server loop. They find that of the 3.36µs spent processing each packet in Linux, nearly 70% of the time is spent in the network stack. The sources of overhead are broken down into network stack costs (packet processing); scheduler overhead (process selection and context switching); kernel crossing from kernel to user space and back; and copying of packet data between kernel and user space buffers.
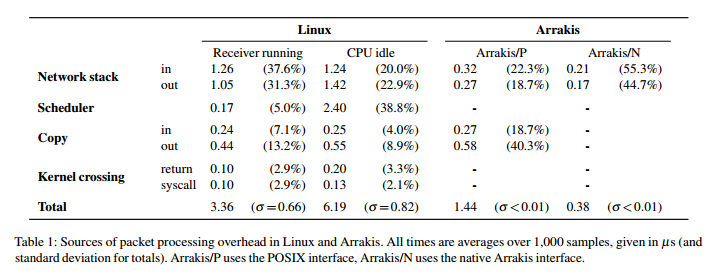
On the right-hand side of the above table, we get a sneak peek at the overhead reduction possible with Arrakis. Arrakis/P is Arrakis with a POSIX interface, and Arrakis/N shows the additional performance that can be obtained by switching to a more efficient non-POSIX interface. Arrakis achieves these results by taking advantage of hardware support to remove kernel mediation from the data plane. This results in simplified packet processing, the elimination of scheduling and kernel crossing overheads entirely (since packets are delivered direct to user space), and with Arrakis/N, the elimination of buffer copy overheads as well.
Similar CPU overheads exist in the storage stack and stem from data copying between user and kernel space, parameter and access control, allocation, virtualization, snapshot maintenance and metadata updates.
While historically these CPU overheads have been insignificant compared to disk access time, recent hardware trends have drastically reduced common-case write storage latency by introducing flash-backed DRAM onto the device. In these systems, OS storage stack overhead becomes a major factor. We measured average write latency to our RAID cache to be 25 µs. PCIe-attached flash storage adapters, like Fusion-IO’s ioDrive2, report hardware access latencies as low as 15 µs. In comparison, OS storage stack overheads are high, adding between 40% and 200% for the extended file systems, depending on journal use, and up to 5× for btrfs.
An analysis of Redis (using AOF) showed that 76% of the average read latency is due to socket operations, and 90% of the write latency. Arrakis reduces read latency by 68% and write latency by 82%.
How Arrakis works
So how does Arrakis actually work? A traditional Linux networking architecture looks like this:
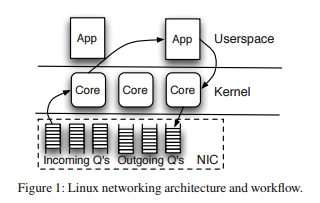
whereas Arrakis is organised like this:

Arrakis takes advantage of virtualization hardware advances to revive a 20-year old idea. Single-Root I/O Virtualization (SR-IOV) supports high-speed I/O for multiple virtual machines sharing a single physical machine, and an SR-IOV capable I/O adapter appears on the PCIe interconnect as a single device which can in turn dynamically create additional virtual devices (PCI calls these ‘functions’). These virtual devices can be directly mapped into different virtual machines and protected via IOMMU – for example Intel’s VT-d.
In Arrakis, we use SR-IOV, the IOMMU, and supporting adapters to provide direct application-level access to I/O devices. This is a modern implementation of an idea which was implemented twenty years ago with U-Net, but generalized to flash storage and Ethernet network adapters. To make user-level I/O stacks tractable, we need a hardware-independent device model and API that captures the important features of SR-IOV adapters;a hardware-specific device driver matches our API to the specifics of the particular device.
(The authors discount RDMA by the way, since in a general networking setting clients and servers are not mutually trusted and therefore the hardware would need to keep a separate region of memory for each active connection).
The Arrakis control plane manages virtual device instances, and kernel involvement is minimized for data plane operations. Applications perform I/O via a user-level I/O stack library.
The user naming and protection model is unchanged. A global naming system is provided by the control plane. This is especially important for sharing stored data. Applications implement their own storage, while the control plane manages naming and coarse-grain allocation, by associating each application with the directories and files it manages. Other applications can still read those files by indirecting through the kernel, which hands the directory or read request to the appropriate application.
Arrakis introduces a hardware-independent layer for virtualized I/O which captures the functionality needed to implement in hardware the data plane operations of a traditional kernel. As of 2014, this was somewhat in advance of what was readily available in hardware: “our model resembles what is already provided by some I/O adapters; we hope it will provide guidance as to what is needed to support secure user-level networking and storage.”
In particular, we assume our network devices provide support for virtualization by presenting themselves as multiple virtual network interface cards (VNICs) and that they can also multiplex/demultiplex packets based on complex filter expressions, directly to queues that can be managed entirely in user space without the need for kernel intervention. Similarly, each storage controller exposes multiple virtual storage interface controllers (VSICs) in our model. Each VSIC provides independent storage command queues (e.g., of SCSI or ATA format) that are multiplexed by the hardware.
To validate the approach on the storage side, given the limited support available from storage devices, the authors developed prototype VSIC support by dedicating a processor core to emulate the support expected from hardware. There are many more details of the hardware model and control and data plane interfaces in the paper which I won’t repeat here, so if you have interest please check out the original paper. One detail which caught my eye is that the authors also developed a library of persistent data structures, called Caladan, to take advantage of low-latency storage devices:
Persistent data structures can be more efficient than a simple read/write interface provided by file systems. Their drawback is a lack of backwards-compatibility to the POSIX API. Our design goals for persistent data structures are that (1) operations are immediately persistent, (2) the structure is robust versus crash failures, and (3) operations have minimal latency. We have designed persistent log and queue data structures according to these goals and modified a number of applications to use them…
How well does it work?
Peter et al. evaluated Arrakis using a read-heavy memached workload, a write-heavy Redis workload, a web server farm workload with an HTTP load balancer, and an IP-layer ‘middlebox’ in the same configuration.
For memcached, Arrakis/P achieves 1.7x the throughput of Linux on one core, and attains near line-rate at 4 cores. Linux throughput plateaus at 2 cores. Arrakis/N gains an additional 10% throughput. It required 74 lines of code to be changed in memcached to port from POSIX to Arrakis/N.
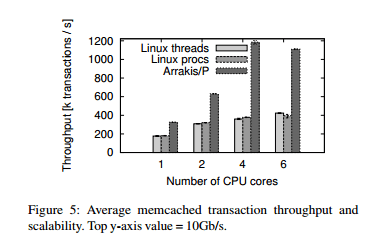
Much of the performance improvement is attributed to the avoidance of cache misses and socket lock contention:
In Arrakis, the application is in control of the whole packet processing flow: assignment of packets to packet queues, packet queues to cores, and finally the scheduling of its own threads on these cores. The network stack thus does not need to acquire any locks, and packet data is always available in the right processor cache.
The Arrakis version of Redis was ported to use Caladan (109 lines of changed code). Write latency improved by 63%, and write throughput by 9x. In a simulation of storage hardware with 15 µs latency write throughput improved by another 1.6x.
Both network and disk virtualization is needed for good Redis performance. We tested this by porting Caladan to run on Linux, with the unmodified Linux network stack. This improved write throughput by only 5× compared to Linux, compared to 9× on Arrakis. Together, the combination of data-plane network and storage stacks can yield large benefits in latency and throughput for both read and write-heavy workloads.
For the HTTP load balancing use case Arrakis achieves approximately a 2x speedup on a single core, and similar scalability to the haproxy baseline.
… connection oriented workloads require a higher number of system calls for setup (accept and setsockopt) and teardown (close). In Arrakis, we can use filters, which require only one control plane interaction to specify which clients and servers may communicate with the load balancer service. Further socket operations are reduced to function calls in the library OS, with lower overhead.
The benefits for the IP-layer middlebox are more pronounced since it does less application-level work meaning that the OS-level network packet processing has a larger impact on overall performance. Arrakis shows a 2.6x performance improvement over Linux.

Is this paper any good? This is not my area, but I have read about remote direct memory access, infiniBand and iWARP, so I know that bypassing the cpu is nothing new. Doesn’t Plan 9 allow users direct access to I/O via its “everything is a file” philosophy?
What am I missing? Where is the great idea or the clueless nonsense?
Why doesn’t Adrian give any commentary? Perhaps this blog is really his paper summarization bot project. That would explain the consistent postings, the cut and paste from the papers, the lack of insightful commentary.
Yes, my money is on this blog being bot summarization project.
I think this article is don’t have a sense an vision of particular work of OS. I embarrassed and feel anger about this.
https://myessaygeek