IX: A Protected Dataplane Operating System for High Throughput and Low Latency Belay et al. OSDI 2014
This is the second of Simon Peter’s recommended papers in the ‘Data Center OS Design’ Research for Practice guide. Like Arrakis, IX splits the operating system into a control plane and data plane for networking. To quote Simon Peter:
The papers differ in how network I/O policy is enforced. Arrakis reaches for utmost performance by relying on hardware to enforce per-application maximum I/O rates and allowed communication peers. IX trades performance for software control over network I/O, thus allowing the precise enforcement of the I/O behavior of a particular network protocol, such as TCP congestion control.
Belay et al. describe four challenges facing large-scale data center applications:
- Microsecond tail latency, required to enable rich interactions between large numbers of services without impacting the user experience. When user requests can involve hundreds of servers, the impact of The Tail at Scale mean that each service node should ideally provide tight bounds on the 99% percentile latency.
- High packet rates sustainable under large numbers of concurrent connections and high connection churn.
- Isolation between applications when multiple services share servers.
- Resource efficiency
This should be possible to address with the wealth of hardware resources in modern servers…
Unfortunately, commodity operating systems have been designed under very different hardware assumptions. Kernel schedulers, networking APIs, and network stacks have been designed under the assumptions of multiple applications sharing a single processing core and packet inter-arrival times being many times higher than the latency of interrupts and system calls. As a result, such operating systems trade off both latency and throughput in favor or fine-grain resource scheduling.
The overheads associated with this limit throughput, furthermore requests between service tiers of datacenter apps often consist of small packet sizes meaning that common NIC hardware optimizations have a marginal impact. IX draws inspiration from middleboxes (firewalls, load-balancers, and software routers for example) that also need microsecond latency and high packet rates, and extends their approach to support untrusted general purpose applications.
There are four principles that underpin the design of IX:
- Separation and protection of control plane and data plane
- Run to completion with adaptive batching
- Native zero-copy API with explicit control flow
- Flow consistent, synchronization free processing
Control Plane and Data Plane
The control plane is responsible for resource configuration, provisioning, scheduling, and monitoring. The data plane runs the networking stack and application logic. A data plane is allocated a dedicated core, large memory pages, and dedicated NIC queues. Each IX dataplane supports a single multithreaded application, operating as a single address-space OS.
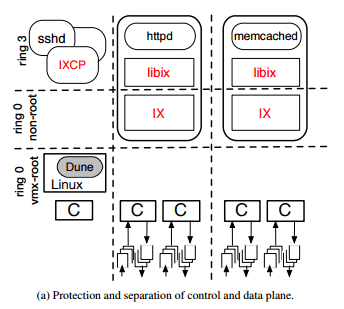
We use modern virtualization hardware to provide three-way isolation between the control plane, the dataplane, and untrusted user code.
Within the dataplane there are elastic threads which initiate and consume network I/O, and background threads to perform application-specific tasks. Elastic threads must not block, and have exclusive use of a core or hardware thread. Multiple background threads may share an allocated hardware thread. The implementation is based on Dune and requires the VT-x virtualization features of Intel x86-64 systems. “However, it could be ported to any architecture with virtualization support.”
Run to completion and adaptive batching
IX dataplanes run to completation all stages needed to receive and transmit a packet, interleaving protocol processing (kernel mode) and application logic (user mode) at well-defined transition points.
This avoids any need for intermediate buffering. Batching is applied at every stage of the network stack, including system calls and queues. This leaps out at me as something traditionally at odds with low latency. However, there are mechanisms in place to combat this: batching is adaptive and only ever occurs in the presence of congestion, and upper bounds are set on the number of batched packets.
Using batching only on congestion allows us to minimize the impact on latency, while bounding the batch size prevents the live set from exceeding cache capacities and avoids transmit queue starvation.
At higher loads with their test workload, setting the batch size to 16 as opposed to 1 improved throughput by 29%.
Zero-copy API
IX eschews the POSIX API in favour of true zero-copy operations in both directions.
The dataplane and application cooperatively manage the message buffer pool. Incoming packets are mapped read-only into the application, which may hold onto message buffers and return them to the dataplane at a later point. The application sends to the dataplane scatter/gather lists of memory locations for transmission but, since contents are not copied, the application must keep the content immutable until the peer acknowledges reception.
The dataplane enforces flow control correctness, the application controls transmit buffering.
Synchronization free processing
We use multi-queue NICs with receive-side scaling (RSS [43]) to provide flow-consistent hashing of incoming traffic to distinct hardware queues. Each hardware thread (hyperthread) serves a single receive and transmit queue per NIC, eliminating the need for synchronization and coherence traffic between cores in the networking stack.
It is the job ofthe control plane to map RSS flow groups to queues to balance traffic.
Elastic threads in the dataplane also operate in a synchronization and coherence free manner in the common case. System call implementations are designed to be commutative following the Scalable Commutativity Law. Each elastic thread manages its own dedicated resources, and the use of flow-consistent hashing at the NICs ensures that each thread operations on a disjoint subset of TCP flows.
Evaluation
The authors evaluate IX against a baseline Linux kernel and against mTCP. IX achieves higher ‘goodput’ than both of these in the NetPIPE ping-pong benchmark with a 10GbE network setup, which is an indication of its lower latency.

In a throughput and scalability test, IX needed only 3 cores to saturate a 10GbE link, whereas mTCP required all 8 cores. IX achieved 1.9x the throughput of mTCP, and 8.8x that of Linux. IX achieved line rate and was limited only by the 10GbE bandwidth. When testing ability to handle a large number of concurrent connections, IX performed 10x better than Linux at its peak.
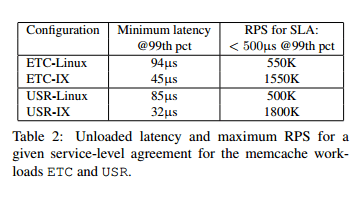
Finally the team test two memcached workloads and report averaged and 99th percentile latency at different throughputs. The Linux baseline setup was carefully tuned so that 99th percentile latency did not exceed 200-500µs following established practices. The ETC workload represents the highest capacity deployment in Facebook, and the USR workload is the deployment with the most GET requests (99%).
Table 2 shows the results for a 99%-ile SLA of under 500μs:

Couple of typos:
job ofthe control
500µs
There seems to be a lot of mechanism and complexity required here to achieve fairly mediocre results. From the paper “The unloaded uni-directional latency for two IX servers
is 5.7µs”. Compare this to a state-of-the-art linux kernel by-pass solution (e.g. [1]) which is around 0.7us for raw frames, and 0.9us for TCP. In the TCP case, the full sockets API is supported. I would say this invalidates much of work around the zero-copy API.
Further, the claim that “IX needed only 3 cores to saturate a 10GbE link” seems a little strange to me. Existing techniques such as [2] and [3] require less than 1 core to saturate a 10G link.
So, what is the real contribution here?
[1] http://exablaze.com/exanic-x10
[2] https://www.cl.cam.ac.uk/research/security/ctsrd/pdfs/201408-sigcomm2014-specialization.pdf
[3] https://www.usenix.org/system/files/conference/atc12/atc12-final186.pdf
I like the concept of having less OS overhead in apps; however, the figures quoted in the article are very strange indeed. I agree with Matt’s comments; I ran a proof of concept for Broadcom a few years back, and even on a now **ancient** Westmere Super Micro Twin server I was able to saturate 10Gbit with a fraction of a core, and that was on a NIC with no kernel bypass using the normal kernel stack; here are the details:
SUT:
Super Micro Twin
(SUT1) – 1 x5680 @ 3.333 GHz – 6 cores – hyper threading on
(SUT2) – 1 x5680 @ 3.333 GHz – 6 cores – hyper threading on
Operating System:
Linux Gentoo 2.6.38-r6
firmware: bnx2x/bnx2x-e1-6.2.5.0.fw
version: 1.62.00-6
No switch; direct connection between the NICs:
BNX2X (10Gbit)
Throughput test harness:
iperf version 2.0.5 (08 Jul 2010) single threaded
SUT 1 – iperf sender (single-threaded, pinned to core 1)
SUT 2 – iperf receiver (single-threaded, pinned to core 1)
CPU util measured with mpstat -P 1,2,3 1 (running on a separate CPUset)
BNX2 sender – (avg, stdev, min, max cpu%) – 21.21, 2.76, 13.86, 28.71
BNX2 receiver – (avg, stdev, min, max cpu%) – 31.31, 6.38, 17.82, 45.54
I went back to double check I hadn’t misquoted the numbers, but this is not the case! Per Matt’s comment, I’ve seen zero copy crop up across a number of different papers, always seeming to make some meaningful improvement. Is there something in the particular benchmark being run (NetPipe) that might help explain the discrepancy? (It looks fairly straightforward to me tbh).
IMHO, this is a case of “common sense” being applied rather measurement guided analysis being used to quantify the potential benefit. Modern machines are extremely good at copying, and, there are even cases where copying can improve performance over non-copying (see [2] above). There is no doubt some benefit to be had by doing a zero copy API, but that benefit is lost in IX because of the heavy weight mechanics used. Furthermore, the paper promises to use these machines to achieve some kind of security/policy enforcement gain, but none to demonstrated or evaluated (unlike Arakis from yesterday).
My default assumption in cases like this is that I’m missing something…. here we have a paper that has been through PC review at a top-tier conference, then further been selected as an exemplary paper in the ACM Queue Research for Practice piece (by Simon Peter, the author of the Arrakis paper). Sadly, I’m not smart enough or experienced enough in this particular area to be able to pinpoint what it might be!
Ah, good point; I think NetPipe itself may be the explanation; they simply ping-pong messages between the sender and receiver, so you have to wait until the receiver gets the whole data before getting the results back, whereas the iperf flags I used on my old tests were for uni-directional flows. So, depending on what the bandwidth delay product (BDP) for the link between the two computers was, the ping pong messages from a single thread would have been insufficient to fill the whole bandwidth. I’m guessing that’s why they may have needed so many threads (and cores) to reach 10Gbit. In contrast, the uni-directional tests will be able to fill the whole bandwidth much more efficiently.
Quote from the paper
It seems to be an attempt to find both single-block latency and overall throughput at a given block size (recognizing that they’re not simply inversely related, due to parallelism at various levels).