Staring into the abyss: An evaluation of concurrency control with one thousand cores – Yu et al. 2014
A look at the 7 major concurrency control algorithms for OLTP DBMSs , and how well they perform when scaled to large numbers (1024) of cores. Each algorithm is optimised for the best in-memory performance possible, but not a single one of them is able to defeat the predictions of the Universal Scalability Law at this scale, with performance starting to degrade after a peak as more cores are added . The work was conducted at MIT CSAIL under the supervision of recent Turing award-winner Michael Stonebraker.
Before we dive into the results, let’s conduct a thought experiment to see what we might expect to find. In the spirit of Pat Helland’s Life Beyond Distributed Transactions, consider what happens as the number of cores multiplies – in the extreme towards an infinite number of cores. Now consider a pathological workload in which all transactions want to read and update the same row. Clearly this will become a bottleneck resource, and the overhead of reaching agreement over access to it will drive performance down aggressively. In fact, as we tend towards an infinite number of cores, we should expect the same behaviour for any resource the cores are asked to share, be that an internal DBMS resource, or user data. Since this pathological case can bring anything that depends on a shared resource to its knees, perhaps we should consider the opposite extreme: what if the cores shared nothing? We can achieve that if we partition the data and all the DBMS resources used for coordination so that each core is responsible for its own partition. Unfortunately now we can construct a new pathological case in which every transaction wants to touch data in multiple partitions – requiring much higher overhead coordination as we see in distributed systems – and also the perhaps more common case of a ‘hot’ partition in which all transactions pile up on the same single core. Thus there is no solution that scales well for all workloads, and we’re once again looking for the best tradeoff given the characteristics of the workload in question (fortunately, we understand the typical nature of many OLTP workloads quite well). Likewise, if coordination can ever be required, then there is no solution that continues to scale as the number of cores tends towards infinity. The question is simply, “for the typical workloads we’re likely to encounter, how far out can we push the limit of scalability?”
As Moore’s law continues, the number of cores on a single chip is expected to keep growing exponentially. Soon we will have hundreds or perhaps a thousand cores on a single chip. The scalability of single-node, shared-memory DBMSs is even more important in the many-core era. But if the current DBMS technology does not adapt to this reality, all this computational power will be wasted on bottlenecks, and the extra cores will be rendered useless.
Under investigation in this paper are OLTP workloads, with classic ACID properties. These have some well-understood characteristics:
The transactions in modern OLTP workloads have three salient characteristics: (1) they are short-lived (i.e., no user stalls), (2) they touch a small subset of data using index look-ups (i.e., no full table scans or large joins), and (3) they are repetitive (i.e., executing the same queries with different inputs).
There are a variety of different schemes used for concurrency control. Yu et al. implemented seven of them giving good representative coverage of the spectrum. As a bonus therefore, we also get a nice succinct overview of the major concurrency algorithms in this paper. These divide into two main families: those based on two-phase locking, and those based on timestamp ordering.
Concurrency algorithms – a family tree
Under two-phase locking schemes transactions first go through a growing phase where they acquire locks, and then a shrinking phase during which locks are released.
If a transaction is unable to acquire a lock for an element, then it is forced to wait until the lock becomes available. If this waiting is uncontrolled (i.e., indefinite), then the DBMS can incur deadlocks. Thus, a major difference among the different variants of 2PL is in how they handle deadlocks and the actions that they take when a deadlock is detected.
- In 2PL with deadlock detection, the system waits for deadlocks to form, discovers this fact, and then chooses a tx to abort to break the deadlock.
- In the 2PL no-wait variant, the system immediately aborts a lock-requesting transaction if the system suspects that a deadlock might occur
- In the 2PL wait-die variant, older transactions are allowed to wait on locks held by younger transactions, but younger transactions requesting locks held by older transactions are treated as in the no-wait case. This method of course relies on timestamp ordering across transactions.
The second major branch of the tree does not use two-phase locking, and instead rely on timestamp ordering;
Timestamp ordering (T/O) concurrency control schemes generate a serialization order of transactions a priori and then the DBMS enforces this order. A transaction is assigned a unique, monotonically increasing timestamp before it is executed; this timestamp is used by the DBMS to process conflicting operations in the proper order (e.g., read and write operations on the same element, or two separate write operations on the same element) .
The following variants of timestamp ordering are considered:
- A basic timestamp scheme, that rejects transactions which would violate timestamp order
- Multi-version concurrency control, in which writes create new versions of tuples in the database
- Optimistic concurrency control, in which write sets are kept in a tx-private workspace and checked for overlap when the transaction attempts to commit.
- Timestamp ordering with partition-level locking (H-STORE scheme):
The database is divided into disjoint subsets of memory called partitions. Each partition is protected by a lock and is assigned a single-threaded execution engine that has exclusive access to that partition. Each transaction must acquire the locks for all of the partitions that it needs to access before it is allowed to start running. This requires the DBMS to know what partitions each individual transaction will access before it begins.
Each of these seven variants was implemented to the best of the author’s abilities in the most scalable way possible:
One of the main challenges of this study was designing a DBMS and concurrency control schemes that are as scalable as possible. When deploying a DBMS on 1000 cores, many secondary aspects of the implementation become a hindrance to performance. We did our best to optimize each algorithm, removing all possible scalability bottlenecks while preserving their essential functionality. Most of this work was to eliminate shared data structures and devise distributed versions of the classical algorithms.
Tests are conducted using the Graphite CPU simulator for large scale multi-core systems. The test workloads are drawn from the Yahoo! Cloud Serving Benchmark and the TPC-C benchmark.
Early limits on scalability
mallocshowed itself early as a bottleneck, and had to be replaced with a custom memory allocation scheme whereby each thread is assigned its own memory pool.- Centralized lock tables had to be replaced with per-tuple metadata, with each transaction only latching the tuples it needs
- Deadlock detection becomes a bottleneck in 2PL because it relies on a shared mutex. Likewise timestamp allocation becomes a bottleneck in timestamp ordering.
- Under high write contention, lock thrashing in 2PL prevents scaling beyond 16 cores! You can selectively abort transactions in a system that is suffering performance degradation beyond this peak to try and keep the system operating at its peak throughput.
- Using an atomic addition operation to advance a global timestamp for timestamp ordering variants does not scale well at all. You can partially mitigate this by batching timestamp allocations, but these have adverse effects under contention, and to truly scale with the number of cores requires hardware support from either clock-based allocation, or a built-in hardware counter.
The hardware counter gives the best theoretical performance, and the existence of such a counter was assumed for the evaluation, despite the fact that no current hardware supports this (thus we really are looking at best case numbers…).
… the third approach is to use an efficient, built-in hardware counter. The counter is physically located at the center of the CPU such that the average distance to each cores is minimized. No existing CPU currently supports this. Thus, we implemented a counter in Graphite where a timestamp request is sent through the on-chip network to increment it atomically in a single cycle.
Evaluation results with 1024 cores
For a read-only workload, the 2PL schemes perform and scale much better than the timestamp-ordering based schemes. But even the best 2PL schemes are only spending ~30% of their cycles doing useful work – the rest are expended on coordination overheads of various kinds. For a write-intensive workload, the 2PL no-wait and wait-die variants give the highest throughput and best scalability.
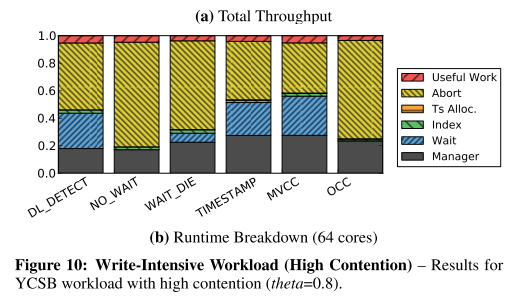
With a high-contention workload, none of the schemes is able to scale beyond about 64 cores, and even at this level the percentage of useful work being done is tiny (see below).
The performance of the H-STORE partitioning scheme depends greatly on how many transactions need to access only a single partition. With all transactions accessing only a single partition, H-STORE scales the best of all up to 800 cores. But when transactions access four or more partitions, it does not scale at all.
H-STORE does best on the mixed TPC-C workload, but not scheme is able to scale this workload to 1024 cores.
The prime bottleneck for each scheme that limits scalability is identified as follows:
- 2PL with deadlock detection scales under low contention but suffers from lock thrashing
- 2PL with no-wait is highly scalable, but suffers from very high abort rates (so doesn’t make useful progress)
- 2PL with wait-die suffers from lock thrashing and and timestamp bottlenecks
- Basic timestamp ordering – high overheads from data copying, suffers from timestamp bottlenecks
- MVCC – performs well with a read-intensive workload, but suffers from timestamp bottlenecks
- OCC has high overhead for data copying, high abort costs, and suffers from timestamp bottlenecks
- H-STORE is the best algorithm for partitioned workloads. Suffers with multi-partition transactions and timestamp bottlenecks.
So where does this leave us?
The partitioned approach makes intuitive sense, if only we could lesson the impact of multi-partition transactions. This is exactly what the work of Bailis et al. promises us: Scalable Atomic Visibility with RAMP Transactions (where the MP in RAMP stands for Multi-Partition). Bailis et al. showed linear scaling to 100 servers (they studied a distributed setting) even under workloads with high contention. How would RAMP fair with 1024 servers??
Yu et al. put forward an argument for considering scaling-up over scaling out (of course commodity hardware may one day come with 1024 cores… ):
Distributed DBMSs are touted for being able to scale beyond what a single-node DBMS can support. This is especially true when the number of CPU cores and the amount of memory available on a node is small. But moving to a multi-node architecture introduces a new performance bottleneck: distributed transactions. Since these transactions access data that may not be on the same node, the DBMS must use an atomic commit protocol, such as two-phase commit. The coordination overhead of such protocols inhibits the scalability of distributed DBMSs because the communication between nodes over the network is slow. In contrast, communication between threads in a shared-memory environment is much faster. This means that a single many-core node with a large amount of DRAM might outperform a distributed DBMS for all but the largest OLTP applications.
But inevitably for the largest use cases we’ll always want to scale-out even our scaled-up servers:
It may be that for multi-node DBMSs two levels of abstraction are required: a shared-nothing implementation between nodes and a multi-threaded shared-memory DBMS within a single chip. This hierarchy is common in high-performance computing applications. More work is therefore needed to study the viability and challenges of such hierarchical concurrency control in an OLTP DBMS.

One thought on “Staring into the abyss: An evaluation of concurrency control with one thousand cores”
Comments are closed.