Scaling Concurrent Log-Structured Data Stores – Golan-Gueta et al. 2015
Key-value stores based on log-structured merge trees are everywhere. The original design was intended to mitigate slow disk I/O. Once this is achieved, as we scale to more and more cores the authors find that in-memory contention now becomes the bottleneck (see yesterday’s piece on the Universal Scalability Law). By replacing the in-memory component of the LSM-tree with a concurrent hash map data structure it is possible to get much better scalability.
Disk access is a principal bottleneck in storage systems, and remains a bottleneck even with today’s SSDs. Since reads are often effectively masked by caching, significant emphasis is placed on improving write throughput and latency. It is therefore not surprising that log-structured merge solutions, which batch writes in memory and merge them with on-disk storage in the background, have become the de facto choice for today’s leading key-value stores…
(Side note: – will storage access still be the principal bottleneck when we have NVMM?)
Google’s LevelDB is the state-of-the-art implementation of a single machine LSM that serves as the backbone in many of such key-value stores. It applies coarse-grained synchronization that forces all puts to be executed sequentially, and a single threaded merge process. These two design choices significantly reduce the system throughput in multicore environment. This effect is mitigated by HyperLevelDB, the data storage engine that powers HyperDex. It improves on LevelDB in two key ways: (1) by using fine-grained locking to increase concurrency, and (2) by using a different merging strategy… Facebook’s key-value store RocksDB also builds on LevelDB.
Links: LevelDB, HyperLevelDB, HyperDex, RocksDB.
One way of dealing with the challenge of multiple cores is to further partition the data and run multiple Log Structured Merge Data Stores (LSM-DS) on the same machine. A fine-grained partitioning mechanism is recommended by Dean et al. in The Tail at Scale. Golan-Gueta et al. put forward two counter-arguments to this approach: (a) consistent snapshot scans do not span multiple partitions, instead requiring transactions across shards, and (b) you need a system-level mechanism for managing partitions, which can itself become a bottleneck.
The following chart shows the performance of the authors’ concurrent-LSM (cLSM) implementation with one large partition, vs LevelDB and HyperLevelDB handling the same amount of overall data but divided into four partitions. cLSM achieves much better throughput as the number of concurrent threads increases, but…
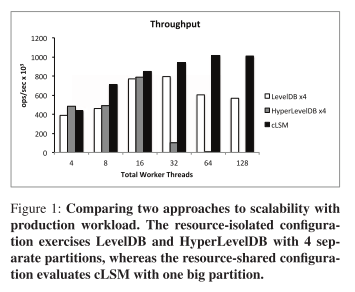
A first glance at the RHS of the chart makes cLSM look impressive. Note a couple of things though: the performance at 16 threads is quite close for all systems (oh, and the hardware used for the test can support 16 hardware threads ;) ); and above 16 threads although cLSM performs much better than the others, its absolute gains in throughput are relatively modest. You can also just start to see a nice curve as predicted but the USL in the cLSM throughput numbers.
More convincing is the data from the evaluation of workloads logged in production by a key-value store supporting ‘some of the major personalized content and advertising systems on the web.’ See figure 10 from the paper, reproduced below:
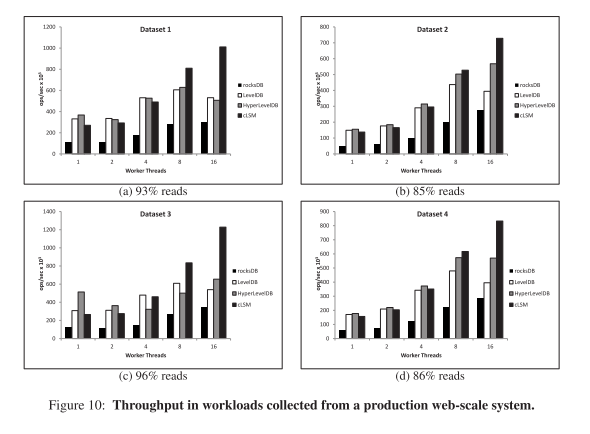
cLSM also manages to maintain lower latency numbers than the competition as throughput scales.
How is it done? First off, the in-memory component of the LSM tree is replaced by a ‘thread-safe map data structure.’
We assume a thread-safe map data structure for the in- memory component, i.e., its operations can be executed by multiple threads concurrently. Numerous data structure implementations, provide this functionality in a non-blocking and atomic manner.
This is then integrated into the normal LSM merge operation. Snapshot scans are implemented on top of the in-memory map on the assumption that the map provides iterators with weak consistency (if an element is included in the map for the duration of the scan, it will be included in the scan results).
Finally, an atomic read-modify-write operation is introduced:
We now introduce a general read-modify-write operation, RMW(k,f), which atomically applies an arbitrary function f to the current value v associated with key k and stores f(v) in its place. Such operations are useful for many applications, ranging from simple vector clock update and validation to implementing full-scale transactions.
The implementation assumes a linked-list or derivative implementation type for the map structure. On this basis it uses optimistic concurrency control, and the contents of the prev and succ nodes in the chain to detect conflicts.
At its heart though, the improvement seems to boil down to the simple idea of ‘why don’t we use an existing efficient in-memory structure for the in-memory part of the LSM-tree’. That seems so simple and obvious (the benefit of hindsight perhaps?) that I’m left with the nagging feeling maybe I’m missing something here…?

One thought on “Scaling Concurrent Log-Structured Data Stores”
Comments are closed.