How to Quantify Scalability: The Universal Scalability Law (USL) – Gunther
Update: corrected sign in USL equation – many thanks to Rob Fielding for pointing out the error.
TL;DR: The Universal Scalability Law, Little’s Law, and Kingman’s Formula can tell you a lot about the behaviour of your systems, and also your organisation. From these I derive four lessons for leaders of fast-growing organisations:
- It’s really important you learn to delegate effectively and to choose carefully the things that you do get involved in.
- As the organisation grows, strive to keep the number of stakeholders that need to be involved in any decision down to a minimum
- You need to keep a strict handle on how many things you’re involved in concurrently; your natural human instinct to be helpful to everyone who asks you to do something for them, or to contribute to their project, actually isn’t helpful at all. (Nor is your desire to control / influence everything if you’re wired that way).
- Working at or close to 100% utilization will slow to a crawl everything that depends on you.
Today’s post is a little different. I was thinking about the advice I should give to the CTO of a fast-growing company struggling to maintain velocity amongst all the competing demands on his time. And it occurred to me that the Universal Scalability Law has a lot to say about this situation. So today’s ‘paper’ choice is actually a reference to Neil Gunther’s website (link above) in which he gives a quick overview of the USL.
This model has widespread applicability, including: load-testing tools like LoadRunner and JMeter; modeling disk arrays, SANs, and multicore processors; modelling certain types of network I/O; accounting for effects such as memory thrashing and cache-miss latencies. That’s why it’s called universal…
It’s even more universal than I realised, as it turns out it also provides a pretty good guide to scaling organisations (at least I think so, you can be your own judge by the end of this piece!). I shall therefore give a somewhat unusual introduction to the USL, couched in terms of ‘advice to leaders of fast-growing organisations.’ You can of course apply the USL to a wide variety of technical scenarios too. We’ll also take a look at Little’s Law and Kingman’s Formula too before we’re done.
The regular format paper reviews will resume tomorrow, fear not!
Applying the USL to scaling an organisation
As a leader of a fast-growing company, in a fast-growing sector, you probably care about how much work your company can get done in a given unit of time (aka throughput), and also how long any one piece of work takes to get through the system (aka latency, or lead time). With high throughput and low latency you’ll be getting a lot done, and be moving fast; able to respond rapidly to new information.
Let’s look at throughput first and see how it is affected as your organisation grows. As you’re adding people, in the ideal case your organisational capacity to do work increases linearly with the number of people. If C(N) represents your capacity (maximum throughput) with N people, then in the ideal case:
C(N) = N / 1
(of course the 1 in the denominator is redundant here, but we’ll get to that later…)

Linear scalability – credit: Neil Gunther / Performance Dynamics
(Actually, there’s an interesting phenomenon called super-linearity, which does even better than linear as you grow – see this recent CACM piece for details – but we’ll ignore that for the case of organisations).
A much more common experience is that as organisations grow, they slow. The USL can help us to understand why this is – and it’s all to do with contention and coherence. Let’s look at contention first, since this is probably the first thing you’ll encounter as you grow. Contention measures the effect of waiting or queueing for shared resources. The USL models this with a parameter α which varies between 0 and 1. Here’s our refined equation including contention effects:
C(N) = N / ( 1 + α(N-1) )
Let’s get a quick intuition for what α is doing here. When α is 0 we’re back at the linear scalability situation. When α is 1 we end up with C(N) = 1 ; in other words the bottleneck totally blocks any improvement in throughput as you add more resource (people). α acts as a ceiling on the improvement you can see, and your capacity improvement curve flattens out as you reach this ceiling.

Diminishing returns from contention – credit: Neil Gunther / Performance Dynamics
As a leader, you may enjoy the feeling of being the alpha-male or female in the organisation. And it turns out you really are the alpha (if you’re not careful). Not alpha as in ‘top dog’ (or cat, if you prefer), but alpha as in the alpha coefficient of the USL. Alpha is modelling what happens when you don’t delegate decisions and tasks effectively. The more operational decisions you need to be involved in, and the deeper you get involved, the more tasks you handle yourself, the higher your α coefficient and the more you limit the overall scalability of your organisation. So the first lesson is that it’s really important you learn to delegate effectively and to choose carefully the things that you do get involved in.
When you don’t delegate enough, you get diminishing returns as the organisation grows. Look at the green and red triangles in the graph above. Both represent adding the same number of people (distance along the x-axis), but early on we get a much bigger capacity increase (distance along the y-axis) for those additional staff than we do as we approach the alpha ceiling.
We’ll look at task selection and how much to delegate in a little more detail shortly, but first let’s take a quick look at the second factor that prevents your organisation from scaling linearly as it grows: coherence. Coherence measures the cost of getting agreement on what the right thing to do is. In the USL, it’s measured by a β coefficient which varies between 0 and 1.
C(N) = N / ( 1 + α(N-1) + β.N(N-1) )
This is the complete USL equation. The coherence factor in the USL is quadratic in N since it involves in the worst case getting pair-wise agreement between every two parties. With a small number of stakeholders involved in each decision the coherence overhead is small, but as N grows larger (in our organisational analogy, as the number of stakeholders involved in each decision grows larger), the cost of incoherence in your organisation (the price of getting to coherence) can dominate. This can even result in negative returns as you add more people, see the following figure from Gunther’s site:

Negative returns from incoherency – credit: Neil Gunther / Performance Dynamics
This result certainly seems to match our intuitions about how larger organisations behave. As they get bigger, there are more and more people around the table, and decision making grinds to a halt. At the first level of growth you may have multiple individual stakeholders, at the next level each of those stakeholders may in fact be representing a department, and it’s also necessary to reach agreement (coherence) within the department as well before a view can be shared at the top level.
Therefore we have the second key lesson: as the organisation grows, strive to keep the number of stakeholders that need to be involved in any decision down to a minimum. Since the coherence factor is quadratic in N and the contention factor is linear, as your organisation gets larger and larger the coherence factor becomes the most important. You need to consciously design your organisational structure in order to minimize coherence overhead, and also work on cultural expectations. I always fall back to software engineering principles – particularly those around modularity – when it comes to thinking about organisation structure. You want strong cohesion within a group, and weak coupling between groups, you want to keep a handle on fan-out etc.. Regarding cultural expectations, you certainly don’t want to create a secretive culture – it’s fine to have good information flow about decisions – but you do want to limit the number of people actively involved in making the decision.
Keeping things flowing: lessons from Little and Kingman…
We’ve seen the factors impacting how much work your organisation can produce (throughput), now let’s look at how quickly you can get work through the system (how responsive your organisation can be).
From understanding the USL, you’ll obviously want to reduce your α bottleneck factor so you’re not holding up the organisation. The natural thing to do is to work as hard as you can, at your maximum capacity, in order to avoid holding up other parts of the organisation that depend on you. This is certainly the behaviour I observe in most leaders, and it’s a trap I’ve certainly fallen into at times over the years. Unfortunately this natural instinct is wrong!
To understand why, and to give some insight into what you should be doing instead, we need to turn to Little’s Law and Kingman’s Formula. Little’s Law gives us a straightforward relationship between how many things you’re juggling at any one point in time (work in progess) and how long it takes any one item to get done (from when in first appears on your queue, to when you’re finished with it).
work_in_progress = throughput * average_wait_time
Since your personal throughput (or capacity) is fixed (there are only so many hours in a day) the only thing you really have any control of here is the amount of work_in_progress. Little’s Law tells us the relationship between how much you take on, and how long everyone that depends on your input, decisions, or approval has to wait:
average_wait_time = work_in_progress / throughput
I expect you’re going to tell me that you don’t have much control over the amount of work in progress either since you’re constantly inundated with requests… I’m getting to that, so for now let’s just imagine that you can control it, ok?
Let’s look at a simplified example. Suppose you had the luxury of focusing exclusively on one project at a time (WIP=1), and if you could do that, you could complete each project within 2.5 days on average. Your capacity is therefore 2 projects/week (I’m giving you weekends off, recharging and thinking away from the office environment is important). The average wait time in this scenario from accepting a piece of work to completing it is 1/2 week. But of course you’re much more likely to be involved in 10 or 20 things at once, such are the demands on a leader in a fast-growing organisation. If you accept those 20 projects, and you’re still working just as hard (completing the same amount of work every week), the average wait time each project is blocked on you goes way up to 20/2 = 10 weeks! Ouch! Now you’ve slowed down all 20 of those projects dramatically and your organizational velocity is tanking. As a leader, you have a big magnifying effect when you become a bottleneck.
So the third key lesson is that you need to keep a strict handle on how many things you’re involved in concurrently; your natural human instinct to be helpful to everyone who asks you to do something for them, or to contribute to their project, actually isn’t helpful at all. (Nor is your desire to control / influence everything if you’re wired that way). You need to limit your work in progress, and this means being ruthless about how many things you get involved in at any one point in time. Again, this points to effective delegation.
In actual fact, the situation is worse than a straight reading of Little’s Law suggests. Consider a hypothetical 40-hour work week, and nice uniform tasks that only take 1 hour to complete (a standard length meeting for example, if your working day is driven by your calendar). You decide that you don’t want any part of the organisation to be blocked waiting on you for more than one week (40 hours).
40 hours wait time = WIP / 1 task-per-hour
With these very small tasks, Little’s Law says you can have 40 of them on the go at any one point in time and still meet your target. This would see you operating at 100% utilization. Now, before you go beating yourself up that you don’t seem to be able to achieve anywhere near this, you’re right – you can’t!
The problem is variability – requests for your time don’t arrive at a uniform rate, and projects don’t take a uniform time to complete. For example, from responding to a single email to working on a multi-week strategic project. This variability, which is inherent in the nature of business, causes a surprising amount of chaos. Kingman’s formula builds on Little’s Law and tells us exactly how much chaos:

Credit – wikimedia.
Here ρ is your utilization (1 = 100% utilized), ca and cs are coefficients of variation for arrival times and service times (i.e. they tell you how much variation you have in those things), and τ is the mean service time (project completion time).
If you explore Kingman’s Formula in a spreadsheet, you’ll find it creates curves such as this:
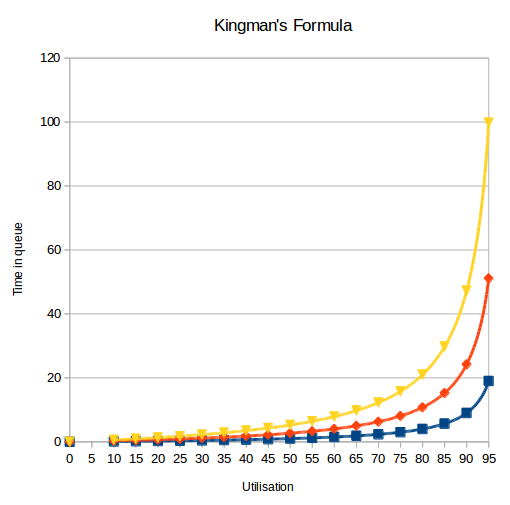
Firstly observe that as you approach 100% utilization, the wait times go up dramatically. Secondly, the three curves I have plotted show the effect of different levels of variability – the yellow curve having the most variability.
In my experience there is very high variability in the things you get asked to do / choose to do as part of the senior leadership team of an organisation. So the ‘Kingman effect’ is closer to the yellow curve than the blue one. The fourth key lesson is that working at or close to 100% utilization will slow to a crawl everything that depends on you.
What am I suggesting you do then? You need to climb back down the utilization curve, to the point where the delays you’re introducing into the organisation are acceptable. I would recommend setting a WIP limit that gives you a utilization somewhere in the 60-80% range. Since this is incredibly hard to do, shoot more for the 60% end of the range and then when you miss by a bit, it won’t be so damaging to the organisation.
So far everything we’ve looked at is governed nicely by mathematical equations. To help you get back down towards that 60% utilization number and unblock your organisation I’m going to turn to a more subjective model, the Eisenhower Decision Matrix as popularized by Stephen Covey. In this model, tasks (projects) are categorized in two dimensions: importance, and urgency (the recommendations within the boxes are mine – see below).
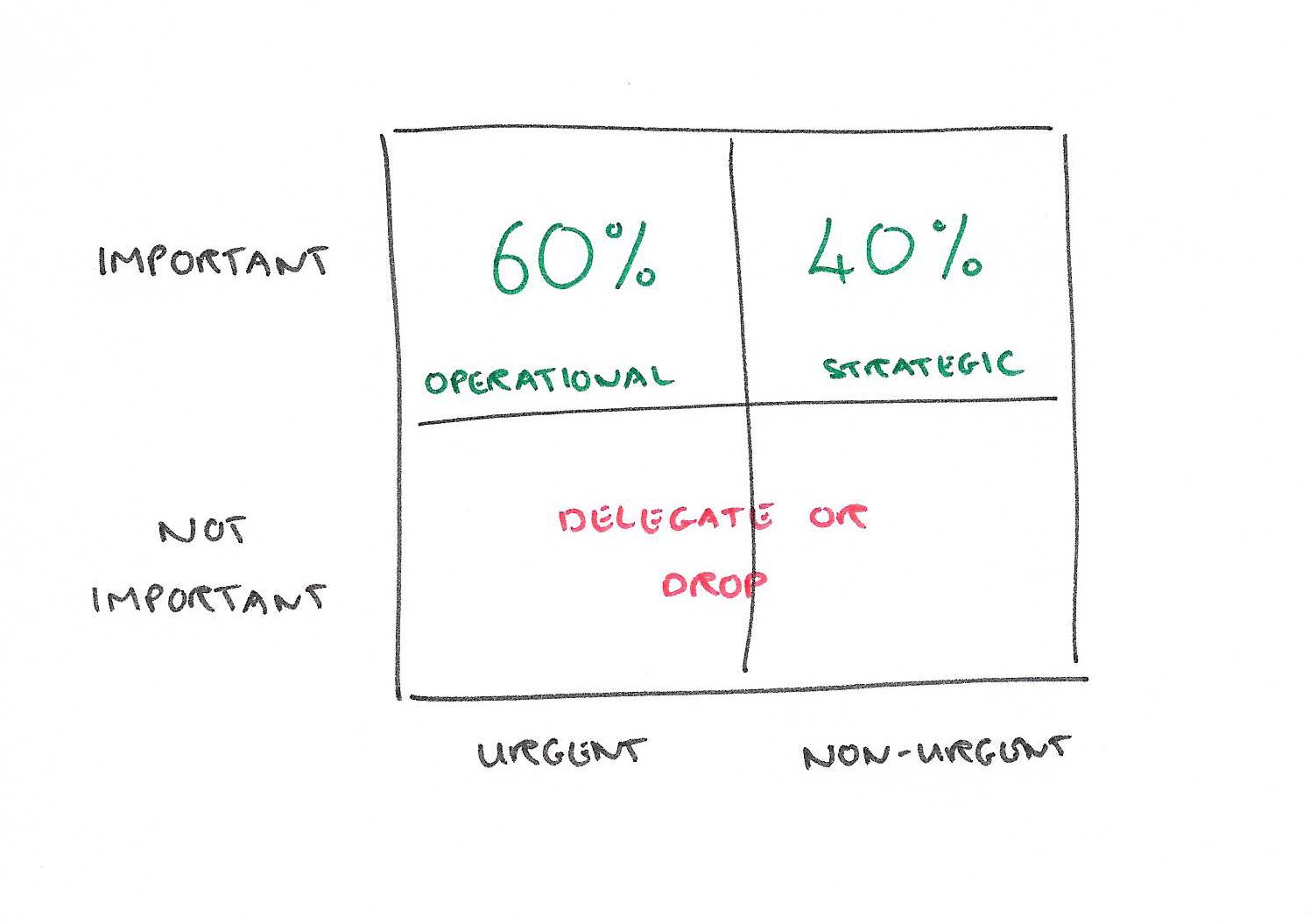
Things that aren’t important (the bottom half of the matrix) can either be dropped or delegated. Things that are important and urgent you can fill up to 60% of your available time with. Take the very most important 60%, and delegate the rest. For ‘urgent’ here, I’m thinking about operational items that will hold up the rest of the organisation if you don’t process them promptly. The other 40% of your time you can spend on important and non-urgent tasks and projects. Because they are non-urgent, they can be temporarily displaced under short-term periods of high-load, providing a buffer to smooth out variability. (But note the short-term element here, if it starts becoming the norm and your utilization rate on urgent tasks is climbing you need to prune it back again). What is it that’s important and non-urgent? Strategic thinking, planning for the future, reflecting on organisational effectiveness, and so on. Here’s the double benefit: it’s so easy for these things to get crowded out and neglected, but by optimising your effectiveness on the urgent stuff you also make time to focus on these questions that are vital to the long-term success of the organisation. And if you’re not focusing on these questions, who is?
So much for the theory. To quote Yogi Berra, “In theory there’s no difference between theory and practice, in practice there is.” I never put all the underpinning theory together in quite the way I’ve described above during my years in CTO and senior leadership positions, but I certainly recognise the effects the theory describes.

Are you familiar with The Principles of Product Development Flow by Don Reinertsen?
I haven’t read that particular book (looks v. interesting from the blurb – thanks for the pointer), but I have read several of the lean/kanban related works…
The equations are quoted wrong, no? C[n] = n / (1 + a*(n-1) + b*n*(n-1)). I got confused when I started plugging your equations into wolfram an python notebooks, and noticed that the original source uses what I figured it must be.
You are quite right, thanks for pointing out! I’ve corrected the post.