I almost missed the milestone, and then I realised that today was the 100th paper in the #themorningpaper series!
I’m sure most readers of my blog posts have figured out the formula by now: I review one CS paper every weekday morning and post the write-up on this blog. Each morning paper is announced via my twitter account @adriancolyer using the hashtag #themorningpaper. So one way of seeing all of the papers in the series so far is via this twitter search. The first 40 or so papers were only reviewed on twitter, after which Guillaume LaForge was instrumental in persauding me to start an accompanying blog format – for which I’m very grateful. The blog makes a much more permanent record. You can see the by-month table of contents for all of the daily paper write-ups since October 8th 2014 for October 2014, November 2014, December 2014, and January 2015. (Or simply usethe archive drop-down in the RH margin of this blog).
If you’re still in the market for New Years Resolutions, I can highly recommend reading more papers and the exposure to new ideas that brings (see the end of this post for a few reflections on my personal journey so far). Or, as a short cut, I’d love to have you along for the ride with #themorningpaper. There are a few simple ways you can do that at the moment:
- You can follow me on twitter and get the daily paper selection and link to the accompanying blog post in your twitter feed
- If you use a twitter dashboard, you can set up a search column for the #themorningpaper tag on my account (as per the link in the second paragraph of this post)
- If you still use an RSS reader, you can consume the blog that way
- You can use an RSS->email gateway to have the daily paper sent to your inbox.
Twitter has been working fairly well so far. But it’s easy to miss a post that way if we’re in different time zones and the day’s tweet gets pushed too far down your twitter timeline by the time you come to check. So a few people have asked, and I’ve been considering, creating a simple mailing list you can optionally subscribe to. Your morning paper sent directly to your inbox without the hassle of setting up an intermediate RSS gateway! If that’s something you think you’d be interested in let me know – if there’s enough interest I’ll look into setting something up.
A good way to figure out whether or not the kinds of papers I cover might be of interest to you is to look through the archives. The common theme is that I find them interesting! My interests are pretty wide ranging though, and I’ve got plenty of material from distributed systems, databases, networking, OSs, programming languages, algorithms, and more planned in the pipeline. The basis of my approach is to focus on ‘foundations & frontiers’. Foundations because with the deluge of information that surrounds us all the time, foundations provide the context to evaluate new ideas; and frontiers because that’s where the action is ! So I draw papers from ‘most influential papers lists’ , from the recommended reading lists of University courses in areas that interest me, from the work of research groups that I’m following, from posts published on Hacker News that catch my eye, from the Proceedings of Conferences and Workshops (new papers from the 2015 editions as the year goes on, as well as ‘best papers’ from previous years), and many other places. I save such lists whenever I find them and then work the papers that interest me into the #themorningpaper schedule. In the world of R&D, my favourite place to be is in the ampersand as ideas and technology transfer between the R and the D!
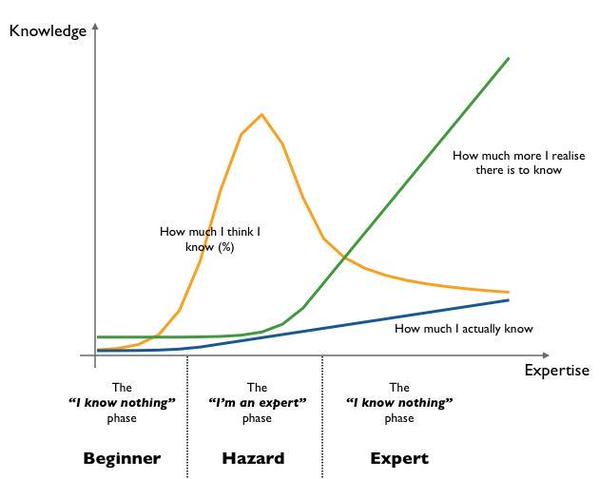
The 100 paper milestone also seems a good moment to reflect on what I personally have got out of the habit. Firstly, it’s been a tremendously enjoyable experience (otherwise I wouldn’t still be doing it by now!). A research paper represents months or more of hard work by one or a team of people, that have taken the time to write up their results and findings, go through a peer review and publication filtering process, and share this with you in a short and concise format. So it’s high quality reading material as a return on my investment. I’ve always worked best by having broad exposure to a lot of ideas and making connections between them, and keeping a steady high-quality diet of good information flowing through my mind has proved very stimulating in that regard. I certainly feel a lot more ignorant than I used to though! A better understanding of the big picture(s) certainly does start to form and deepen in your mind over time, but this is dwarfed by the increasing realisation of just how much there is out there that you still don’t know. With thanks to Simon Wardley, the following graph captures the phenomenon very nicely (only I certainly don’t feel like an expert!). My ‘known unknowns’ have increased significantly, and I have perhaps made a small dent in my ‘unknown unknowns’ ;).
As another wonderful side benefit, I’ve hugely enjoyed the interactions over twitter that have resulted from posting these write-ups. Thank you all!
When I’m not reading research papers, I work with Accel Partners in London on the look-out for exciting new companies and advising those we invest in. After spending years in CTO-type roles at SpringSource, VMware, and Pivotal, I’m slightly more technical than the average VC though ;). If you’re doing something interesting with technology in Europe, I’d love to hear from you!

Thank you Adrian for this series. I must say I enjoyed most of papers you chose. Can you tell me how do you find them? And where do you get them from? Some services with papers are charging pretty big amount of money for them. Often I read papers on nutrition and medicine too and they can cost up to 30$ each.
Hi Mateusz, I’m glad you’ve been enjoying the series. I try to choose only papers that are freely available online. Google Scholar has been a good resource for finding papers, and I’ve had great success with searching for ‘[paper title] pdf’ to find copies that researchers post on their own accounts etc. I do have an ACM DL subscription, but so far I have avoided covering a paper that’s only behind a paywall. In terms of figuring out what papers to read, the paragraph two above Simon Wardley’s chart contains a section starting with ‘I draw papers from…’ that explains some of the sources I use. Essentially, I’m constantly on the look out for papers or lists of papers that may be interesting, and I save them away whenever I find them, for later use.
I love this blog ! How long does it take you to read+write each day ?
Thank you! It takes somewhere between 2-3 hours per post I estimate, normally split across a morning initial reading of the paper, and an evening session writing up what I learned…