Online, Asynchronous Schema Change in F1 Rae et al. 2013
Continuous deployment and evolution of running services with zero downtime is the holy grail. With stateless services this is comparatively easy to achieve. But once we have stateless services, and especially large volumes of data in a store, things get more difficult. We would ideally like to be as agile with our database as we are with our codebase. Yes there are migrations, as popularized by Rails and supporting tools such as LiquiBase, Flyway, and the Large Hadron Migrator, or you could go schemaless (e.g. MongoDB). But for a large scale distributed SQL database this is still a challenge. Which is why the online, asynchronous schema change mechanism built into Google’s F1 datastore is worth a deeper look.
Schema evolution — the ability to change a database’s definition without the loss of data — has been studied in the database research community for more than two decades. In this paper, we describe techniques used by Google’s F1 database management system to support schema evolution in a new setting.
That new setting is a massively distributed relational store with shared data storage and no global membership protocol (so no reliable means of determining currently running F1 servers, and no possibility of explicit global synchronization). Since the AdWords systems powered by F1 is critical to Google’s business, and any downtime has immediate revenue implications, the schema change process for F1 needs to insure:
- Full data availability at all times: “any downtime of the AdWords F1 instance can be measured with a direct impact on Google’s revenue, and modifications to the schema cannot take the system offline.”
- Minimal friction in the development and release process:
TheAdWords F1 instance is shared among many different teams and projects within Google that need to access AdWords data. As a result, the F1 schema changes rapidly to support new features and business needs created by these teams.
- Minimal performance impact: “typically multiple schema changes are applied every week, and because schema changes are frequent they must have minimal impact on the response time of user operations”
- Asynchronous change support: global synchronization in F1 is not possible.
These criteria influenced the schame change process as follows:
First, since all data must be as available as possible, we do not restrict access to data undergoing reorganization. Second, because the schema change must have minimal impact on user transactions, we allow transactions to span an arbitrary number of schema changes, although we do not automatically rewrite queries to con-form to the schema in use. Finally, applying schema changes asynchronously on individual F1 servers means that multiple versions of the schema may be in use simultaneously.
(in practice, ‘multiple versions’ became ‘2’ as this greatly simplified the reasoning and implementation).
And here we find another use of formal reasoning to help ensure desired distributed system properties (see also the use of formal methods at Amazon):
Soon after we implemented the schema change process in F1, we realized the need for a formal model to validate its correctness, since improperly executed schema changes could result in catastrophic data loss. While we developed our formal model, we found two subtle bugs in our production system, and we also found that some of the schema changes that we had not yet implemented could be supported safely. Finally, by allowing us to reason about our schema change protocol, having a formal model increased our confidence in the F1 schema change process.
The secret to F1’s schema changes is the introduction of two new internal intermediate states for schema elements: delete-only, and write-only. A delete-only table, column or index cannot have its key value-pairs read by user transactions. Tables can only be modified by delete operations, and indices by delete and update operations. A write-only column or index can have its key-value pairs modified by insert, delete, and update operations, but none of its pairs can be read by user transactions.
The paper proceeds by defining what it means for a database to be consistent with respect to some schema S, and describing the two ways this consistency can be violated. In simple terms these are (a) the inclusion of an element that shouldn’t be there – an orphan data anomaly, and (b) a missing element that should be there – an integrity anomaly.
A consistency preserving change from one schema to another is one in which all operations that preserve consistency under the old schema also preserve it under the new schema, and all operations that preserve consistency under the new schema also preserve it under the old one. (Directly) Adding or removing a public structural schema element is not consistency preserving, but it can be if the change goes through the appropriate intermediate steps:
However, it is possible to prevent these anomalies by judicious use of the intermediate states. These intermediate states, when applied in the proper order, can ensure that no orphan data or integrity anomalies ever occur in the database representation, allowing us to execute consistency-preserving schema changes.
Each type of change is analysed in turn, and it is shown that by including the appropriate intermediate steps, it can become consistency preserving. The migration strategy is summarized in the following figure (click for larger view):
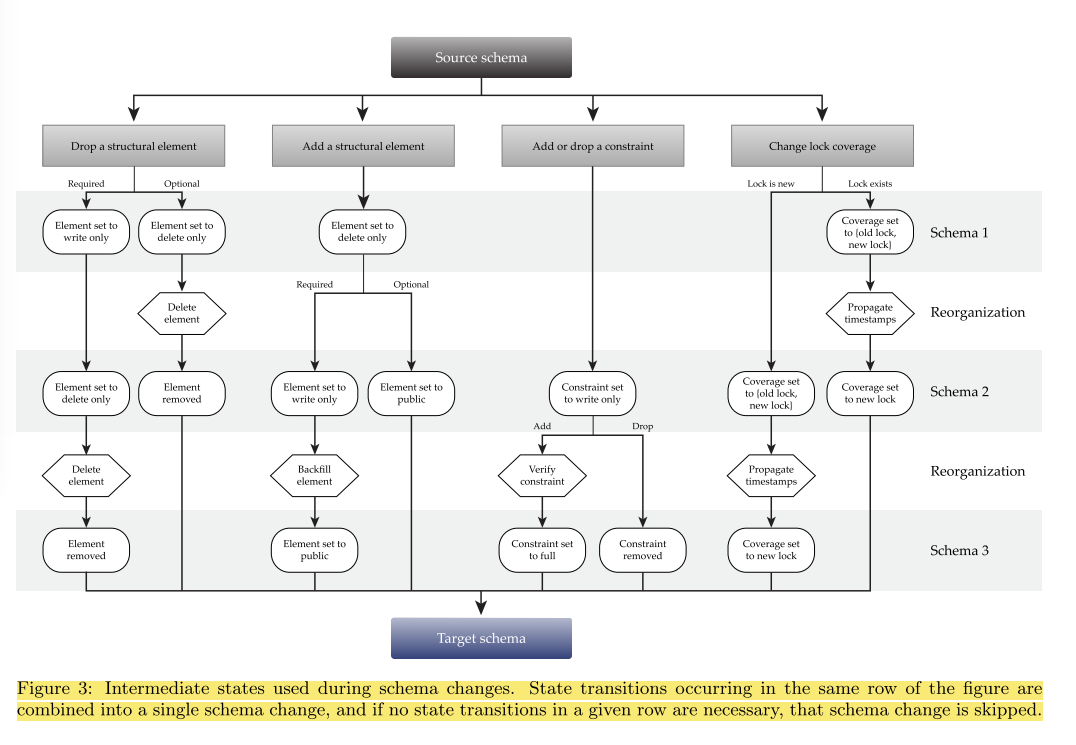
In the F1 implementation, schemas are version-controlled, and developers update sources in the VCS system to include their desired changes. In this manner, several schema updates can be batched into one set of schema change operations.
Before the new schema can be applied, an analysis process determines which intermediate states and reorgani-zations are required in order to safely perform the schema change. Once the intermediate schemas and reorganizations are determined, an execution process applies them in order while ensuring that no more than two schema versions can be in use at any time.
A lease mechanism is used to ensure that at any moment F1 servers use at most two schemas.
The schema change execution process must wait at least one schema lease period before applying a new intermediate schema. Therefore, a typical schema change involving no reorganization takes 10 to 20 minutes.
Some schema changes also require database reorganization (for example, the addition of an index). A background reorganizer built with the MapReduce framework handles theses tasks.
There are many more details in the paper itself, so as always I encourage you to go and read the full version (link at the top of the post) if this has piqued your interest.

4 thoughts on “Online, Aysnchronous Schema Change in F1”
Comments are closed.