STELLA: report from the SNAFU-catchers workshop on coping with complexity, Woods 2017, Coping with Complexity workshop
“Coping with complexity” is about as good a three-word summary of the systems and software challenges facing us over the next decade as I can imagine. Today’s choice is a report from a 2017 workshop convened with that title, and recommended to me by John Allspaw – thank you John!
Workshop context
The workshop brought together about 20 experts from a variety of different companies to share and analyse the details of operational incidents (and their postmortems) that had taken place at their respective organisations. Six themes emerged from those discussions that sit at the intersection of resilience engineering and IT. These are all very much concerned with the interactions between humans and complex software systems, along the lines we examined in Ironies of Automation and Ten challenges for making automation a ‘team player’ in joint human-agent activity.
There’s a great quote on the very front page of the report that is worth the price of admission on its own:
Woods’ Theorem: As the complexity of a system increases, the accuracy of any single agent’s own model of that system decreases rapidly.
Remember that ‘agent’ here could be a human – trying to form a sufficient mental model to triage an incident for example – or a software agent.
A digression on complexity budgets
Especially when we have humans in-the-loop (and one of lessons from ‘Ironies of Automation’ is that we always have humans in-the-loop), then a notion I’ve been playing with in my mind is that of a ‘complexity budget’. Every time you introduce complexity to a system, you spend a bit of that budget. Go overdrawn (i.e., introduce a requirement for one human to need to understand more complexity than is reasonable) and you’re no longer in control of your systems. Humans can of course work in teams, with a structure resembling that of the system itself, so I’m not saying everything must fit in a single mind, but each of the pieces that need to be understood as a whole do need to.
It’s an interesting idea to play around with, but the problem is that it’s hard to make actionable. Yes we have a whole armoury of systems and software techniques to try and cope with complexity, but it’s a tough monster to tame and behaves in counter-intuitive ways. We’re all familiar with the concepts of essential complexity and accidental complexity, but it’s the emergent complexity as a system grows that bothers me the most. We do linear work, adding components to a system over time, but that results in a super-linear growth in complexity.
Consider just the interactions between those components, for 

If we think about partial failures etc. though, then with 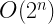
Anyway, I’ve digressed for far too long. The takeaway point here is perhaps that even though the component being worked on is in itself no more complex than any of the existing ones in the system, and takes no more effort to develop and to understand in isolation than any of the existing components, its cost in terms of your overall complexity budget is higher than all those that preceded it. This is what we find counter-intuitive in my experience.
Three anomalies
The report describes the details of three anomalies (SNAFUs). You’ll find the details in section 3, and I’m not going to repeat them here as we have a lot of ground (44 pages) to cover. In each case though, there was one particular feature of the SNAFU that caught my eye.
- In the first SNAFU, Chef was pushing out a faulty version of a critical piece of software across all servers. The system stayed viable during the incident only because the automated updating mechanism was broken on a few of those servers. “The irony that the system was able to ‘limp along’ on a handful of servers that continued to run because they were not ‘properly’ configured was not lost on the operators.” My margin note here reads “diversity aids resilience” (an interesting alternative interpretation of DRY!).
- In the second SNAFU the thing that stood out to me was that both the system dashboard and the third-party SaaS vendor insisted everything was fine with a key as-a-Service component, when in fact it wasn’t. I.e., there’s a false representation that had to be identified and overcome.
- In the third SNAFU a key feature was that the place where symptoms were first manifest was remote from the actual underlying cause.
Section 3.4.1 in the paper lists some interesting features that all the anomalies had in common, including:
- Arising from unanticipated interactions between system components
- Having no single ‘root cause’ (during my holiday reading I discovered by accident that Tolstoy has a lot to say on this topic in ‘War and Peace’ – try reading the first couple of pages from Vol III, Part I, Chapter I for example!).
- Having been lurking in the system as ‘accidents waiting to happen’ for some time
- Being triggered by only slight differences from normal operating conditions
- Intially being buffered by system mechanisms designed to cope with partial failures etc., but eventually exhausting those mechanisms
What happens during an incident
Even more interesting than the actual anomalies themselves is what was going on in the respective organisations as they tried to grapple with the unfolding drama.
Developing means to establish how people understood what was happening, how they explored the possible sources, how they weighed alternative corrective actions and made sacrifice decisions, how they deployed resources, managed side effects, compensated for deteriorating conditions, revised their problem understandings, and coordinated with others is paramount if we are to enhance the resilience of these important systems.
The first observation is that “the system” encompasses everything that contributes to the operation state. That’s not just the running components you immediately think of, but also the tool chains, deployment processes, monitoring tools, and everything else wrapped around them. The people interacting with the system need to maintain sufficient mental models of how this all works to be able to perform their tasks.
In a fast changing world, the effort needed to keep up to date can be daunting.
How do participants do that? The software and hardware actually embodying the system can’t actually be seen or controlled directly (the argument is a bit like the philosophical one that we can’t directly experience an object except through our senses), instead we experience it through the various interfaces those parts expose to us. Collectively that set of interfaces is called “the line of representation.” So what is below the line is inferred by the mental models formed in the viewers, through their observations of those representations.
An important consequence of this is that people interacting with the system are critically dependent on their mental models of that system – models that are sure to be incomplete, buggy, and quickly become stale. When a technical system surprises us, it is most often because our mental models of that system are flawed.
There are regular (situational) surprises, and then their are fundamental suprises. Situational surprise is compatible with previous beliefs about the system, but fundamental surprises refute one or more of those beliefs. Therefore, while it is possible to anticipate situational surprise, you can’t anticipate fundamental surprise (because by definition you have no model capable of inferring such an outcome).
Information technology anomalies are frequently fundamental suprises… Learning from fundamental surprises requires model revision and changes that reverberate.
Following a surprise, participants start out in state of uncertainty – what’s really going on? Is an intervention actually required? If so, what should it be? Information gathering through various search mechanisms is key to beginning to form a (partial) mental model of the situation. This search activity was “effortful and iterative.” The ability to successfully manage an anomaly heavily depends on the available system representations and how they can be used to build models and form hypotheses.
… experts demonstrated their ability to use their incomplete, fragmented models of the system as starting points for exploration and to quickly revise and expand their models during the anomaly response in order to understand the anomaly and develop and assess possible solutions.
The same process is going on as we saw last time out in ‘Synthesizing data structure transformations‘ : hypothesis generation, deduction to refute some thesis and generate sub-problems for others, and enumerative search to test possibilities for what is left!
Teams tended to self-organise with little explicit structure.
One final thing I wanted to highlight from this section of the report is a phenomenon I’m sure many of you will feel a lot of empathy for:
Generally, the longer the disruption lasts, the more damage is done. Disturbances propagate and cascade; consequences grow… Uncertainty and escalating consequence combine to turn the operational setting into a pressure cooker and workshop participants agreed that such situations are stressful in ways that can promote significant risk taking.
Six themes
The report concludes with six interlocking themes that emerged from the discussions.
1. The value of postmortems
Postmortems are valuable for pointing out misunderstandings about the way the system works, as well as insights into the brittleness of technical and organisational processes. “They can also lead to deeper insights into the technical, organizational, economic, and even political factors that promote those conditions.”
But postmortems can be hard to do well, and although technically focused on the surface, they are at their core complex social events. We often don’t give them the time and space they need.
Investing in adaptive capacity is hard to do and even harder to sustain. It is clear that organizations under pressure find it hard to devote the resources needed to do frequent, thoughtful postmortems
2. Blame vs sanction
We hold up ‘blameless’ postmortems as an ideal. But that word is often misinterpreted. Blame is the attribution of an undesired outcome to a specific source. A sanction is a penalty levied on a specific individual.
Organizations often assert that their reviews are ‘blameless’ although in many instance they are, in fact, sanctionless. As a practical matter, it is difficult to forego sanctions entirely. Accountability is often nice-speak for blaming and sanctioning.
3. Controlling the costs of coordination
As an investigation progresses, it’s likely that more people get drawn into it. There’s a tradeoff between what they can contribute to solving the puzzle, and the costs involved in bringing them up to speed. One way of mitigating coordination costs is to prepare plans up front. Unfortunately our plans don’t often fare so well when they meet with reality:
Many aids are developed based on assumptions about how anomalies present themselves and about what will be useful that later turn out to be incorrect. Checklists and decision trees that seem crisp and clear in the office may be unhelpful or even misleading during real events.
Another problem that we saw last week is that even when you do call in the expert they face the highly challenging situation of coming up to speed on what is happening and has been done so far in managing the incident, and they need to have had regular contact with the system to have sufficient skills and context.
Easy problems are quickly solved without expert help… Experts are usually called upon when the initial responses fail and so experts typically confront difficult problems. Anomalies that persist despite the initial response are qualitatively different – steps have been taken, lines of inquiry pursued, diagnostics and workarounds attempted. Coupled to an anomaly that is itself cascading, the activities of initial responders create a new situation that has its own history.
4. Improving visualisations
In many incidents we find ourselves in the complex or chaotic Cynefin domains. Here the appropriate modes are, respectively, to probe, sense, and respond or to act, sense and respond
Much of the anomaly response revolves around sensemaking, that is, examining and contrasting the many pieces of data to extract meaningful patterns… Representations that support the cognitive task in anomaly response are likely to be quite different from those now used in ‘monitoring’. Current automation and monitoring tools are usually configured to gather and represent data about anticipated problem areas. It is unanticipated problems that tend to be the most vexing and difficult to manage.
5. Strange loops
A strange loop occurs when some part of the system that provides a function also ends up depending on the function it provides. Under normal operation this can be ok… until the day that it isn’t! “Strange loop phenomena are common in modern computing with its elaborate tool chains and complex dependencies.”
What is clear is (a) the complexity of business-critical software means strange loops are present; and (b) strange loop dependencies make anomalies difficult to solve. What is not clear is how to manage the risks imposed by strange loop dependencies in business-critical software.
6. Dark debt
If technical debt is something that we know about in our systems, and plan one day to hopefully address, dark debt is its more sinister cousin – lurking in our systems but we aren’t necessarily aware of it. Dark debt is not recognisable at the time of creation, and generates complex system failures. It’s impact is not to slow development, but to generate anomalies. “There is not specific countermeasure that can be used against dark debt because it is invisible until an anomaly reveals its presence.”
If you only take away one thing…
Resilience in business-critical software is derived from the capabilities of the workers and from the deliberate configuration of the platforms, the workspace, and the organization so that those people can do this work. It is adaptability that allows successful responses to anomalies and successful grasping of new opportunities… In a complex uncertain world where no individual can have an accurate model of the system, it is adaptive capacity that distinguishes the successful.
Further reading
The report is littered with great references to follow-up on if the subject matter interests you (we’ll be looking at one of them next time out), so it makes a great jumping off point if you want to dig deeper.

Wow! Great stuff. Made me realize: Diversity Aids Resilience Extensively = DARE as a counterpoint to DRY. Also: dark debt is emergent technical debt. We don’t know what we don’t know about complex system interactions, which are themselves sometimes emergent, even when fairly simple components are combined. Kind of like iterated function systems, where complex behavior emerges from seemingly simple formulae.