Trade-offs under pressure: heuristics and observations of teams resolving internet service outages, Allspaw, Masters thesis, Lund University, 2015
Following on from the STELLA report, today we’re going back to the first major work to study the human and organisational side of incident management in business-critical Internet services: John Allspaw’s 2015 Masters thesis. The document runs to 87 pages, so I’m going to cover the material across two posts. Today we’ll be looking at the background and literature review sections, which place the activity in a rich context and provide many jumping off points for going deeper in areas of interest to you. In the next post we’ll look at the detailed analysis of how a team at Etsy handled a particular incident on December 4th 2014, to see what we can learn from it.
Why is this even a thing?
Perhaps it seems obvious that incident management is hard. But it’s worth recaping some of the reasons why this is the case, and what makes it an area worthy of study.
The operating environment of Internet services contains many of the ingredients necessary for ambiguity and high consequences for mistakes in the diagnosis and response of an adverse unexpected event.
Allspaw highlights four key challenges:
- The systems are uniquely opaque, with multiple layers of abstraction hiding underlying complexity, performance variability under normal conditions, and an increasing interdependence between services, including across organisational boundaries.
- The Internet itself, over which these systems operate, is a dynamically distributed network spanning national borders and policies with no central coordinating agent. Routing, for example, is non-deterministic. Business-critital Internet systems inherit all of the challenges of distributed systems.
- The organisations that build and operate these systems are themselves often geographically distributed and communicating virtually.
- The environment is open, with continuous interactions with content and information consumers and producers.
All the criteria are present for such systems to be classified as complex adaptive systems: connectedness, diversity, adaptation, and interdependence. Moreover:
- Causality is complex and networked
- The number of plausible options is vast
- System behaviour may be coherent to a degree (recurring patterns and trends), but the system is not fixed so these patterns and trends vary over time.
- Predictability is reduced: we can’t always predict all the consequences of an action, and for a given desired outcome we can’t always determine what actions will produce it.
- When things fail, it is hard to tell what it is exactly that is failing (or sometimes even if there is a failure at all).
In summary, software engineers find themselves in a very unenviable position when attempting to resolve an outage with their service.
Building blocks and prior research that can help us think about incident management
From a safety science perspective, there is a dearth of research in the current literature that attempts to investigate the issue of team-based anomaly response in the domain of web and Internet engineering. However, there is not a lack of human factors and systems safety research on the topics of teams engaging in understanding and resolving anomalies under high-tempo and high-consequence conditions.
Klein shows us that teams have some advantages over individuals:
- a wider range of attention
- a broader range of expertise
- built-in variability
- a greater capability for reorganising their activities
- and the ability to work in parallel
Patterson et al. provide insights on the patterns that occur in teams engaged in cooperative cognition:
- breakdowns in coordination are signaled by surprise
- activities escalate following an unexpected event in a monitored process
- investment in shared understandings to facilitate effective communication
- local actors adapting plans from remote supervisors in order to cope with unexpected events
- calling in additional personnel when unexpected situations arise
- function distributions of cognitive processes during anomaly response
The study of distributed cognition adds all of the machine components into the mix ("treating certain arrangements of people and artifacts as cognitive systems"). The joint activity undertaken in such settings has a number of properties:
- cognition is distributed across multiple natural and artificial cognitive systems
- cognition is part of a stream of activity, not something that happens in a short moment before responding to an event
- it is embedded in a social environment and context that constrains activities and provides resources
- the level of activity fluctuates
- almost all activity is aided by something or someone beyond the unit of the individual cognitive agent, i.e., by an artefact.
In the context of IT systems, the [Journal of Computer-Mediated Communication][JCMC] has published a long stream of research on communication that takes place using computer-based tools (e.g. chat).
Woods 1995 gives us collective patterns of reasoning that emerge during the joint activity:
- during diagnosis people act on their best explanations of what is happening in order to plan their response
- response planning includes taking corrective action(s) which are then monitored for success
- if anomalies are recognised during the course of monitoring, those observation are fed back into response planning
- safing actions may be taken to contain or limit the anomalous behaviour, and these may also generate more information to use in response planning
- any unexpected behaviour is further used to inform the diagnosis
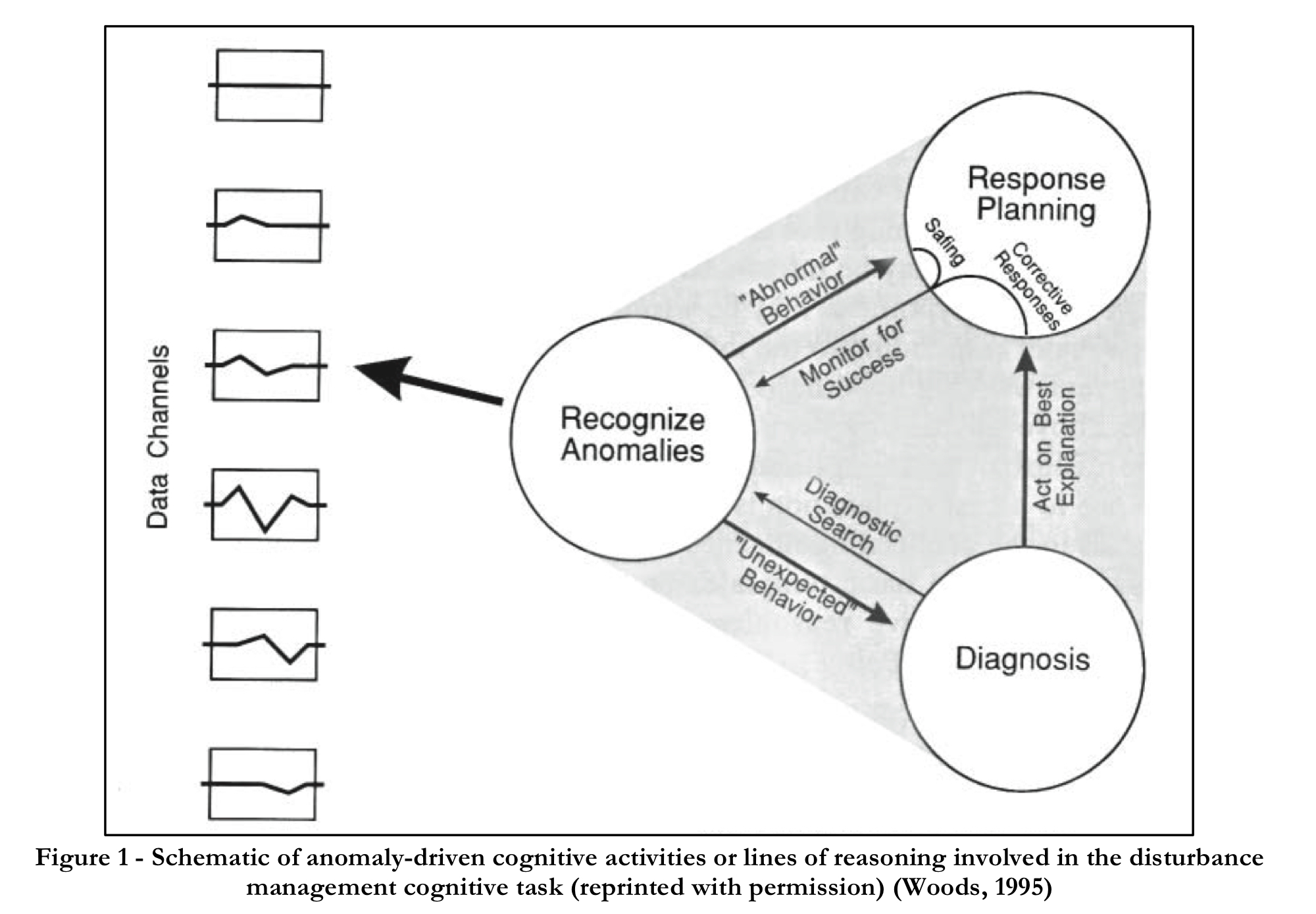
While the activity unfolds, participants are constantly forming hypotheses and making decisions.
In an environment where the amount of information available to explore (and rate at which it can be generated) greatly outpaces a team’s ability to hold its collective attentional control, a number of coping strategies come into view. One of these strategies is to use heuristics.
Hollnagel enumerates a set of judgement heuristics often used in scenarios involving uncertainty and multiple conflicting goals:
- Similarity matching – judging the similarity between triggering conditions and stored attributes of appropriate action
- Frequency gambling – choosing among partially matched options based on the frequency of their occurence
- Representativeness – if it looks like X, it probably is X
- Availability – choosing by how easily the option comes to mind
- Focus gambling – opportunistically changing from one hypothesis to another
- Conservative gambling – moving slowly and incrementally to build up a hypothesis
- Simultaneous scanning – trying out several hypotheses at the same time
Because these heuristics are shortcuts, they are a manifestation of the ETTO (efficiency-thoroughness trade-off) principle: they trade-off thoroughness with efficiency which can sometimes produce both upsides and downsides.
Too much jumping between options leads to thematic vagabonding – never getting deep enough in any one area. Its twin danger is cognitive fixation – where people can become fixated on a specific idea or solution even to the exclusion of incoming signals that indicate otherwise.
Standing alongside heuristics is the notion of expert intuition, which is studied in the naturalistic decision making (NDM) community. Intuition comes through pattern recognition of cues found in a given situation. Making decisions off the back of intuition has been termed recognition-primed decision-making (RPD).
The key for this thesis is to recognize that both perspectives suggest that cognitive strategies used in situations that contain uncertainty (such as Internet service outages) are far from comprehensive, and will contain mental shortcuts. Whether these shortcuts are called "heuristics" or "skilled intuition" matters litle; the goal is to identify them used in the wild.
Preventative design is not enough
I’m going to close this post with one final thought. As a community, we’ve spent a lot of our collective energy addressing the question: "what is needed for the design of systems that prevents or limits catastrophic failure?" This is all well and good, but realise it is not the same as the question:
When our preventative designs fail us, what are ways that teams of operators successfully resolve those catastrophes?

4 thoughts on “Trade-offs under pressure: heuristics and observations of teams resolving internet service outages (Part 1)”
Comments are closed.