Synthesizing data structure transformations from input-output examples, Feser et al., PLDI’15
The Programmatically Interpretable Reinforcement Learning paper that we looked at last time out contained this passing comment coupled with a link to today’s paper choice:
It is known from prior work that such [functional] languages offer natural advantages in program synthesis.
That certainly caught my interest. The context for the quote is synthesis of programs by machines, but when I’m programming, I’m also engaged in the activity of program synthesis! So a work that shows functional languages have an advantage for programmatic synthesis might also contain the basis for an argument for natural advantages to the functional style of programming. I didn’t find that here. We can however say that this paper shows “functional languages are well suited to program synthesis.”
Never mind, because the ideas in the paper are still very connected to a question I’m fascinated by at the moment: “how will we be developing software systems over this coming decade?”. There are some major themes to be grappled with: system complexity, the consequences of increasing automation and societal integration, privacy, ethics, security, trust (especially in supply chains), interpretability vs black box models, and Grady Booch’s challenge to us to raise the level of abstraction (i.e., productivity, and also expanding the set of problems we can solve at a given skill level).
Program synthesis from examples falls into that latter camp, and the use case addressed here is a perfect fit for it: transforming data structures. I.e., side-effect free programs that are completely specified by a pure function from input to output. For problems like this, synthesis seems to be the ultimate ‘no-code’ solution.
[Automated program synthesis] aims to radically simplify programming by allowing users to express their intent as nondeterministic, possibly-incomplete specifications. An algorithmic program synthesizer is then used to discover executable implementations of these specifications. Inductive synthesis from examples is a particularly important form of program synthesis…
An example
One motivating example from the paper is a high-school teacher wanting to modify a collection of student scores to drop the lowest test score for each student. So for example given the input [[1,3,5],[5,3,2]] the output should be [[3,5],[5,3]]. Given the following examples:
Then the system can synthesize the following program:
dropmins x = map f x
where f y = filter g y
where g z = foldl h False y
where h t w = t || (w < z)
The paper focuses on generating transformations for such recursive data structures (trees, lists).
High-level approach
Transformations of recursive data structures are naturally expressed as functional programs. Therefore, our synthesis algorithm targets a functional programming language that permits higher-order functions, combinators like
map,foldandfilter, pattern-matching, recursion, and a flexible set of primitive operators and constants.
We don’t want just any old program that passes all the tests though (if you think of each input-output example as a test case), we want the simplest (least cost) program that fits the examples.
One definition of simple, but not a terribly useful one, would be a program that simply memorised input-output examples. That’s probably not what the end-user had in mind (though if the set of given examples was exhaustive it would be ok). We want the generated program to be able to generalise to new examples. Nothing in the authors approach actually tests for this, but the program cost metric used to evaluate generated programs encourages it: a program has lower cost for example, if it is free of conditional branches.
The end-to-end system is based on a combination of inductive generalisation, deduction, and best-first enumerative search.
The inductive generalisation step takes the input-output examples and uses them to form a set of hypotheses about the shape of the program that might be able to recreate them. What’s called a hypothesis in this paper is the same thing as the sketch that we saw last time out in PIRL. To give a quick flavour, suppose all of the output examples have the same top level structure as their corresponding inputs; that’s a clue that map might be appropriate. Whereas if, say, an output list is shorter than an input list, then we can reject the ‘top-level map’ hypothesis.
A hypothesis contains one or more holes (slots) that need to be filled in. Finding the appropriate functions for those holes means solving a sub-instance of the overall problem, and is done using automated deduction. This further exploits structure in the given examples. In the teacher example above suppose we have a top-level map hypothesis, and now we’re looking for the function we’re going to use to map over the list. By deducing input-output examples for that sub-function, we can turn this into just another recursive instantiation of the program synthesis routine. It would go a bit like this:
- Given the initial input-output example
[[1,3,5],[5,3,2]]maps to[[3,5],[5,3]]we infer an initial hypothesis that a program structureis a good candidate and now we need to find the function
.
- We can deduce examples
[1,3,5]maps to[3,5]and[5,3,2]maps to[5,3]for this new function - Those examples become the input to a new sub-instance of the program synthesis routine
Deduction can also be used to refute candidate hypotheses for the missing functions. As we know, a
filterlooks like a good candidate for the teacher example as presented. But suppose we instead wanted the sums of the student scores, in that case we could see from the shape of the data that we could never achieve the output with just a filter.
Once the algorithm has made as much progress as possible with generalisation and deduction, a best-first enumerative search is used to explore the space of possible solutions.
Using the principle of Occam’s razor, our search algorithm prioritizes simpler expressions and hypotheses. Specifically, the algorithm maintains a “frontier” of candidate expressions and hypothesis that need to be explored next and, at each point in the search, picks the least-cost item from this frontier.
The synthesis algorithm
Here’s the full synthesis algorithm, where 
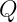
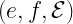
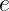
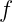
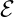
The hypothesis generation routine (InductiveGen) is type-aware, and can generate both ‘open’ (includes further holes for higher-order functions) and ‘closed’ hypotheses. The supported open hypotheses are shown in the table below:
The deduction engine is powered by a set of inference roles, a selection of which are show below. If a judgement produces 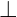
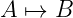
The deduction process is sound but it is not guaranteed to be complete.
Evaluation
The synthesis algorithm is implemented in a tool called 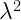
We have used
The program is required to produce the Cartesian product of a set of lists. For example, the input [[1,2,3], [4], [5,6]] maps to the output [[1,4,5],[1,4,6],[2,4,5],[2,4,6],[3,4,5],[3,4,6]].
Barron and Strachey’s pearl to implement this transformation looks like this:
cprod xss = foldr f [[]] xss
where f xs yss = foldr g [] xs
where g x zss = foldr h zss yss
where h ys qss = cons(cons(x, ys), qss)
Give the examples below,
[] -> [[]] [[]] -> [] [[], []] -> [] [[1,2,3], [5,6]] -> [[1,5],[1,6],[2,5],[2,6],[3,5],[3,6]]
Discussion
As an end-user, if I supply a set of input-output examples and get back a program that satisfies them, one of the things I’m definitely going to be left wondering about is how well the program will do on new examples it has never seen before (generalisation). I could inspect the code of course, but for a certain class of target user that’s not a satisfactory solution. One way to assess generalisation would be to test the program on a hold-out set of validation examples. And a way to encourage generalisation might be to have a test set of example different to the synthesis examples, with performance on these test examples feeding back into the ‘cost’ equation. In other words, I’m just blatantly borrowing ideas from the data science / machine learning community here of course.
An alternative that might work for some users and use cases is to deploy the generated function, and a mechanism for the user to notify the system when it has produced the wrong output on a given input. The system can then take this failed input-output pair as a new example and re-run synthesis inline to produce a new program.
Another tactic I could see here that would help with generalisation is to explicitly allow the user to use quantification in input-output examples. That’s a slippery slope towards asking users to write specs though, and maybe that’s too much for the target use cases…

These is a vague family resemblance to this beautiful paper about Erlang:
Lindahl, Sagonas: “Practical Type Inference Based on Success Typings”
Click to access succ_types.pdf
Seems like the sort of problem Genetic Programming could be usefully applied to.