Programmatically interpretable reinforcement learning, Verma et al., ICML 2018
Being able to trust (interpret, verify) a controller learned through reinforcement learning (RL) is one of the key challenges for real-world deployments of RL that we looked at earlier this week. It’s also an essential requirement for agents in human-machine collaborations (i.e, all deployments at some level) as we saw last week. Since reading some of Cynthia Rudin’s work last year I’ve been fascinated with the notion of interpretable models. I believe there are a large set of use cases where an interpretable model should be the default choice. There are so many deployment benefits, even putting aside any ethical or safety concerns.
So how do you make an interpretable model? Today’s paper choice is the third paper we’ve looked at along these lines (following CORELS and RiskSlim), enough for a recognisable pattern to start to emerge. The first step is to define a language — grammar and associated semantics — in which the ultimate model to be deployed will be expressed. For CORRELS this consists of simple rule based expressions, and for RiskSlim it is scoring sheets. For Programmatically Interpretable Reinforcement Learning (PIRL) as we shall soon see, it’s a minimal functional language and an accompanying program sketch. The key thing is that by the definition of the language and the rules for valid expressions within it, any model expressed in that language will be interpretable. Given the model expression language (a DSL), we can now use all of the machine learning techniques at our disposal (including black box methods) to learn an expression in that language. Ultimately it’s that learned and interpretable (by humans as well as machines) expression that we deploy in our systems. Hence black-box and other models become not the ultimate output of our learning process, but an intermediate step along the way.
In PIRL, Verma et al. embody this pattern in the following way:
- There’s a tiny functional language based on a small number of side-effect free combinators
- For a given task, a program template (which the authors call a sketch), further constrains the set of programs that can be learned for the problem in hand. This also very handily constrains the search space of course, helping to make learning a suitable policy program tractable.
- To help guide the search within the set of programs conforming to the sketch, a standard reinforcement learning algorithm is used to learn a (black box) policy.
- The black box policy is used as an oracle (the Neural Policy Oracle), and a neurally directed program search (NDPS) tries to find the sketch-conforming program that behaves as closely to the oracle as possible.
There’s a subtle point here that it may not be possible to exactly mirror the behaviour of the Oracle in a sketch-conforming program. For one thing, that program is likely to have a much smaller state space than the Oracle. There’s a nice thing that happens in the evaluation section, where the authors compare the performance of a learned program (interpretable model) against the best black box model (the Oracle). While the interpretable model may not get to quite the same level of performance as the Oracle on the exact task used for training, it turns out that the process of generating the interpretable model results in something which generalises much better to new situations. The authors present this without commentary. My hypothesis is that it’s the result of the smoothing effect of dimensionality reduction, reducing overfitting.
We demonstrate that NDPS is able to discover human-readable policies that pass some significant performance bars. We also show that PIRL policies can have smoother trajectories, and can be more easily transferred to environments not encountered during training, than corresponding policies discovered by DRL.
A DSL for policies
In PIRL, policies are expressed using a high-level DSL.
…to facilitate search through the space of programs expressible in the language, it is desirable for the language to express computations as compactly and canonically as possible. Because of this, we propose to express parameterized policies using a functional language based on a small number of side-effect free combinators. It is known from prior work that such languages offer natural advantages in program synthesis.
The language supports:
- Numerical constants
- A set of basic operators (+, -, *, /, …)
- Variables
- A
peek(x, i)operation that gives the observed value of a variablex,itimesteps ago in a history. - A
foldoperator that operates over histories
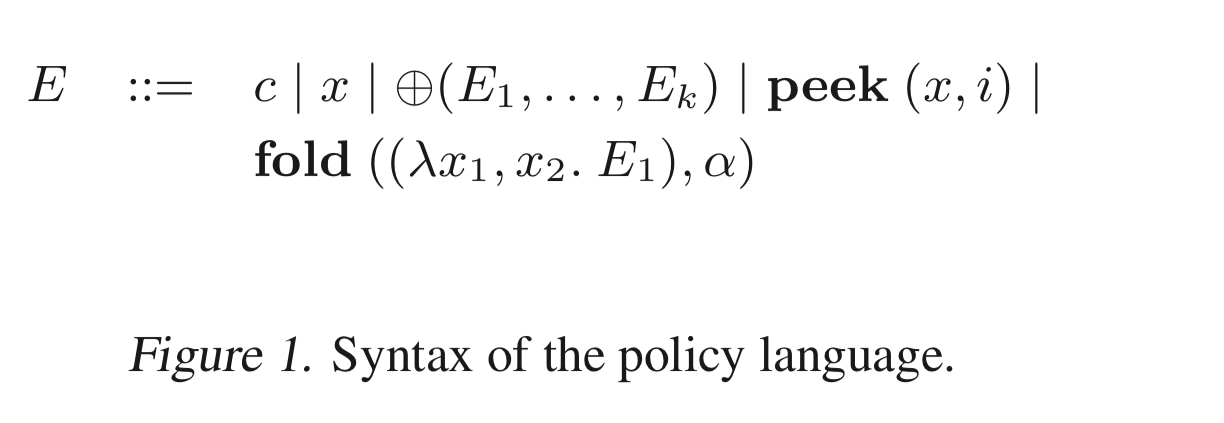
Sketches
Given the vast number of possible programs that can be generated using the DSL, for a given problem, the user provides a grammar of allowable expressions. The running example in the paper is learning a policy to drive a race car around circuits in TORCS (The Open Racing Car Simulator). The policy has to control steering, acceleration, and so on. We could use our domain specific knowledge to figure out that a good ‘shape’ (or sketch) of a likely solution is to use a number of PID controllers. But how they should be parameterised, and how we should coordinate amongst them is unknown. The following sketch grammar shows how we could then constrain the policy program search space:
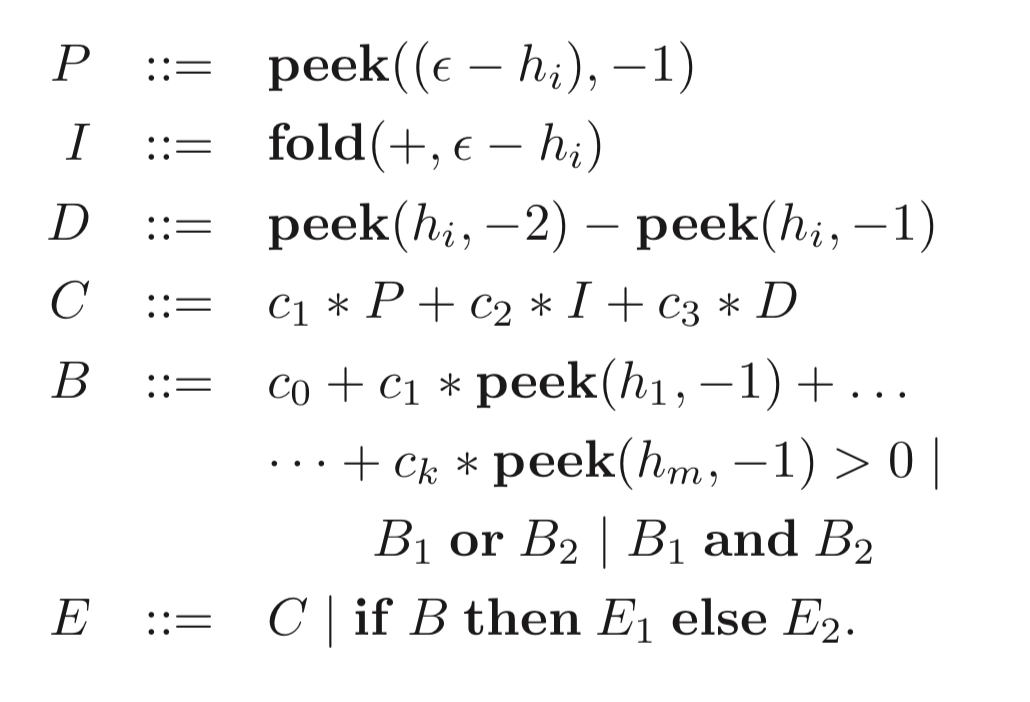
By acting over a fixed-size window of history, the fold (I) can be used as a discrete approximation of the integral term in a PID controller.
Here’s an example program conforming to this grammar that PIRL learns for TORCS:

(Enlarge)
Neurally directed program search
The non-smoothness of the space of programmatic policies conforming to a sketch means that standard search approaches can’t be used. So instead PIRL uses standard deep reinforcement learning to learn a policy oracle for the given environment. The Neurally Directed Program Search algorithm (see below) then seeks to find a program that closely mimics the behaviour of the oracle. This is a form of imitation learning.

There’s a tricky bit here whereby programs encountered during the search may generate histories that are impossible under the oracle (and so we can’t ask the oracle for advice on what to do). For example, the oracle may never drive the race car into a wall, but if we generate a program that does do this, we very much want advice!
Our solution to this problem is input augmentation, or periodic updates to set
(the history). More precisely, after a certain number of search steps for a fixed set
Learning to drive a car
The authors use NDPS to train a policy for the practice mode of TORCS – input is available from 29 sensors, and the agent must learn to control acceleration and steering. The sketch used in the experiment was the one we looked at above, and fold calculations were restricted to the five most recent history observations. Each distinct race track is viewed as distinct POMDP (partially observable Markov Decision Process). In addition to TORCS, NDPS is used on three simpler control games as well: Acrobot, CartPole, and MountainCar.
For two racetracks, here’s how NDPS performed when compared to the following approaches:
- DRL – an agent using deep reinforcing learning directly
- Naive – a program synthesised without access to a policy oracle
- NoAug – a program synthesised without input augmentation
- NoSketch – a program synthesised without sketch guidance
- NoIF – a program synthesised with a restricted sketch that does not permit conditional branching.
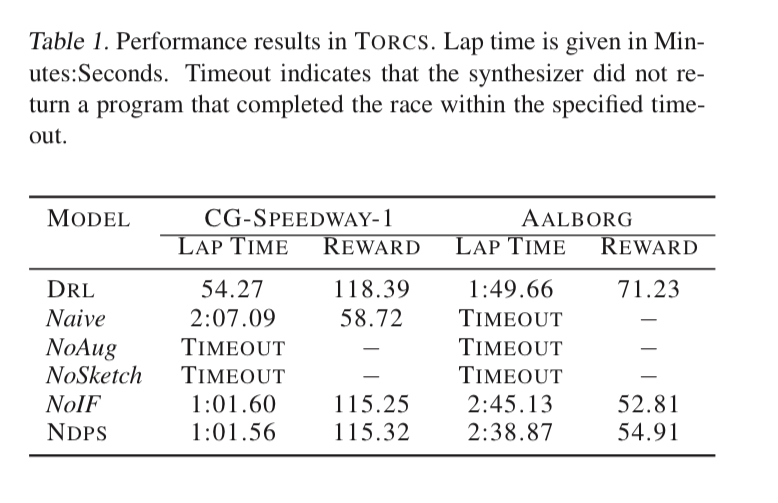
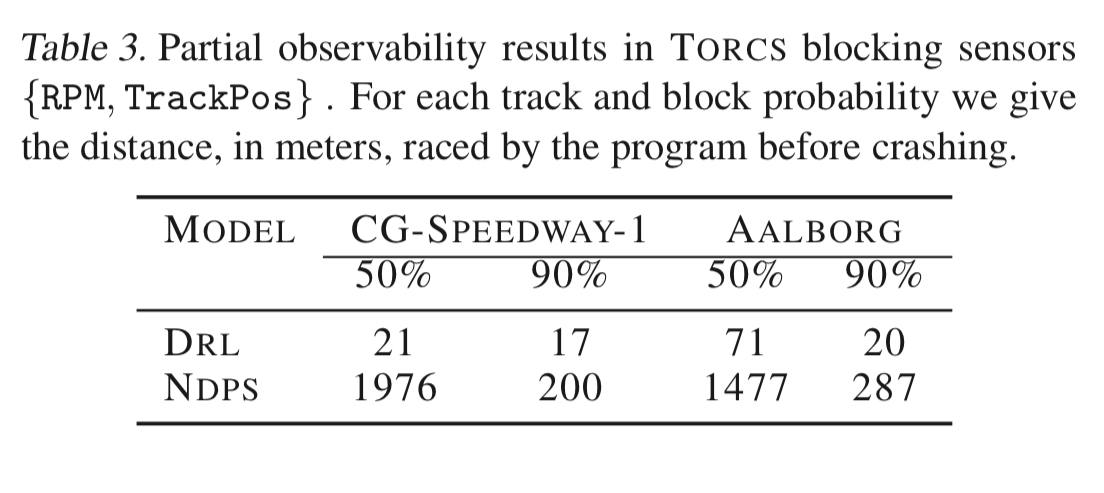
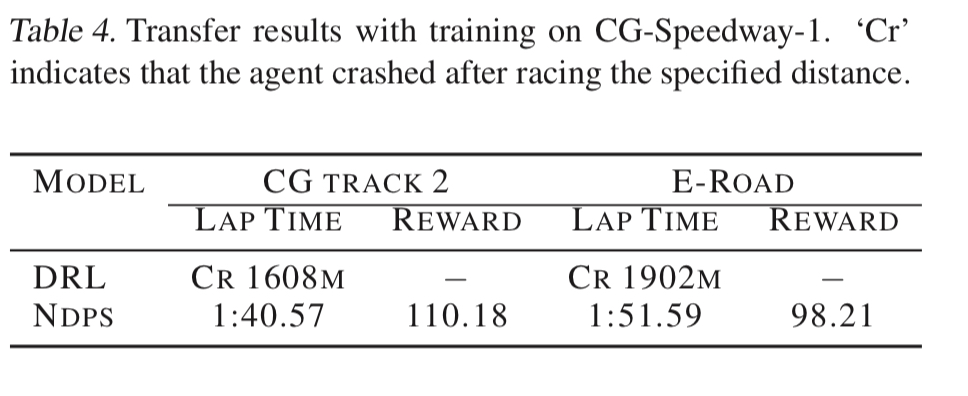
The DRL policy performs better, but the NDPS policy is pretty good, and it is interpretable by construction. The NDPS policy is also less aggressive with its control inputs, resulting in smoother steering actions. When noise is added (by simulating defective sensors with dropouts) then the NDPS policy does noticeably better than the DRL one:
It also does better on race tracks the agent hasn’t seen before:
Verifying policy properties
So far as we know, the current state of the art neural network verifiers cannot verify the DRL network we are using in a reasonable amount of time, due to the size and complexity of the network…
On the other hand, the simple program produced by NDPS can easily be verified. The authors show one simple proof that the generated program guarantees smooth steering behaviour, and another proof of global bounds on action properties.
One nice thing it occurs to me you could do here, is design the sketch in such a way that the programs conforming to it can easily have an accompanying TLA+ (or similar) model. Then you can use the proof system to reason about the generated programs. It might even be possible to have some kind of reward feedback loop whereby generated programs that don’t satisfy certain desired properties are pruned.

{kind=link}
How do you feel about grammar induction? It seems like this might eliminate some issues with interpretability