A persistent problem: managing pointers in NVM Bittman et al., PLOS’19
At the start of November I was privileged to attend HPTS (the High Performance Transaction Systems) conference in Asilomar. If you ever get the chance to go, I highly recommend it. It’s a comparatively small gathering with a great mix of people, and fabulous discussions. A big thank you to everyone that I met there for making me feel so welcome.
On the last morning of the conference Daniel Bittman presented some of the work being done in the context of the Twizzler OS project to explore new programming models for NVM. It’s a really bold project (‘let’s rethink the OS from the ground up’) and generated a lot of lively discussion.
(Byte-addressable non-volatile memory,) NVM will fundamentally change the way hardware interacts, the way operating systems are designed, and the way applications operate on data.
The starting point is a set of three asumptions for an NVM-based programming model:
- Compared to traditional persistent media, NVM is fast. This means that the overheads of system calls become much more noticeable. Therefore any programming abstraction must be low latency and the kernel needs to be kept off the path of persistent data access as much as possible.
- The beauty of persistent memory is that we can use memory layouts for persistent data (with some considerations for volatile caches etc. in front of that memory, as we saw last week). Traditionally one of the major costs when moving data in and out of memory (be it to persistent media or over the network) is serialisation. With NVM we have both an opportunity to avoid serialisation overheads, and also an obligation since these overheads would be intolerable compared to the performance of NVM.
- This is a really interesting one… the nature of pointers themselves has to change. At least, the nature of pointers that we want to make persistent. Traditional pointers address a memory location (often virtual of course). But the assertion here is that:
Persistent pointers, which implement references via identity and not ephemeral location, are vital for software to construct data structures in a world of persistent memory… Virtual addresses are insufficient as they are ephemeral and cannot encode identity-based data references for objects in a distributed, global address space without dramaticaly increasing pointer size or incurring coordination costs.
The eagle-eyed reader will have noticed another feature of this work in that quotation: the aim is to create a global address space that spans nodes and processes. When I think about NVM my mind always flips between two modes of thinking: think of NVM as a kind of memory, and while you can make a global address space out of it, you wouldn’t necessarily leap to that as fundamental requirement; but think of NVM as a kind of storage, and then it’s immediately much more natural that of course you’d want to be able to access a global storage layer.
Crash-consistency by the way is treated as an orthogonal concern and not discussed in this paper. I both buy the argument that there are many works looking at crash consistency mechanisms for NVM, and also have some reservations about "bolting crash consistency onto our design later".
Given the three assumption above, the conclusion the authors reach is that we can’t get to a satisfactory place with an incremental or layered approach over the storage abstractions we have today. In particular, it’s goodbye to the POSIX interface.
In for a penny, in for a pound…
A clean-slate approach not only reduces the complexity of the system by dropping the need to support outdated interfaces, but it also enables redesigning interfaces and the OS for direct access to byte-addressable memory instead of spending effort extending APIs indefinitely. Removing unnecessary layers of software and designing with an eye towards the future has the potential to enable vast improvements in programmability, data sharing, and security – but this will only be possible if our design decisions permeate all levels of the software stack.
The analogy that came to my mind while I was listening to Bittman’s talk is the introduction of electric cars: a complete under-the-hood rethink with far fewer moving components than ICEs, and some pretty interesting advantages as a result.
The Twizzler programming model
Twizzler chooses objects as the basic unit of abstraction and persistence (which puts me in mind of ‘Compress objects, not cache lines‘ that we looked at in a previous edition of The Morning Paper). Objects have globally unique 128-bit identifiers (generated by any suitable scheme). 128 bits gives room for plenty of objects in the address space, but it makes for big pointers (to state the very obvious, twice the size of 64-bit pointers!).
On the assumption that if you refer to something once, you’re likely to refer to it many times, Twizzler saves space by introducing a layer of indirection. Persistent data is addressed by an (object_id, offset) pair. (I.e., it’s possible to reach directly into data within an object). Since object ids are large though, instead of keeping the full object id in every pointer, an object maintains an internal Foreign Object Table (FOT) – an array of object ids. A persistent pointer then becomes a combination of an index into the FOT, and an offset in the target object. A picture shows this better than my clumsy description:
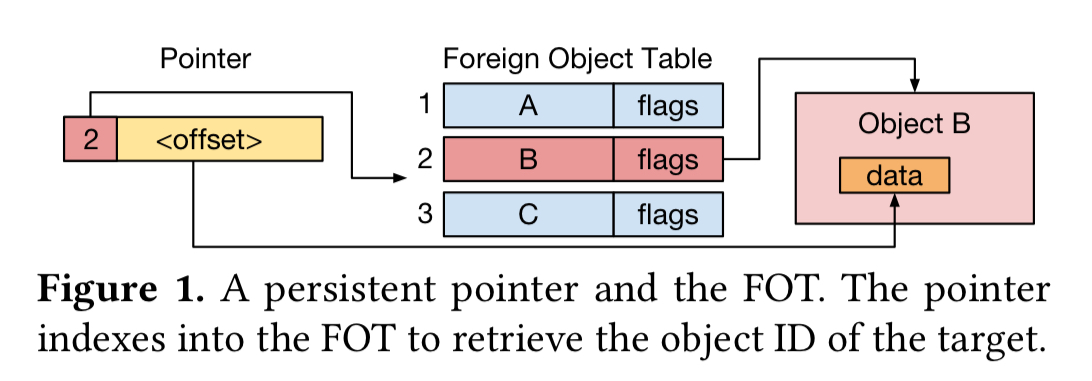
Objects can be coarser-grained than you might immediately associate the word object with when thinking about in-memory objects. For example, a whole B-tree might be a single persistent object. Think of such an object more like a replacement for a traditional file and it all starts to make sense again. Thinking of it this way also makes me a bit more comfortable with the thought of pointers reaching directly into offsets in someone else’s objects, though I have to say that still troubles me a bit!
Twizzler’s cross-object pointers enable the programmer to explicitly encode data relationships, allowing the programmer to express their application as operating on data structures with each per-object FOT providing sufficient context for the system to follow references.
The Twizzler KVS (key-value store) is just 250 lines of C code, and uses one persistent object for the index structure, and a second one for the data. Cross-object pointers make this easy and natural.
The FOT structure has some pros and cons. On the plus side, it reduces the memory overheads of global pointers, and means that we can very quickly change all references to one object A to another object B just by changing the corresponding entry within the FOT. (A and B are presumably different instances of the same object type, because they have to have the same internal data layout). This feels like it’s going to be very good for a bunch of atomic update operations. On the minus side, storing those offsets means that the internal data layout of an object becomes public information that you can’t change.
…generic system software cannot be written if offsets need to change as they are based on semantic information that generic system sofware may not have access to… However, applications can anticipate changing object formats…
In other words, a bit like versioning your API, you’re going to have to think about versioning your object layout, and some kind of in-object indirection mechanism that can support multiple versions and migrations. This is left as an exercise for the application developer at present.
What about security?
If the kernel isn’t involved in the persistent data access path, then we need a hardware solution to enforce access control. With no explicit open operations either, checking access writes needs to be done on every access (cf. e.g., checking file access permissions for writing on an fopen). FOT table entries are marked as either read or read-write, but with checking occuring on actual access a program that marks a pointer as read-write but that doesn’t have write access will not fail unless it actually tries to write.
The kernel is involved in checking access control policy only on first access (handling a page fault), setting up the MMU to enforce policy. If the access policy is changed (e.g. rights are revoked) the kernel is once again involved to invalidate existing MMU access controls. The combination of checking rights on every access and invalidating them immediately on modification helps to eliminate time-of-check-to-time-of-use errors (TOCTTOU).
Early performance results
The goals of the Twizzler research project at the moment are to improve programmability and security, any performance improvement is just a pleasant side-effect. It’s important though that Twizzler not introduce too large a performance overhead.
The paper concludes with a quick comparison of a KVS written using a modified FreeBSD kernel in the Twizzler-proposed model, and a traditional Unix implementation using files. The performance is on a par, "showing that the Twizzler approach improves programmability and security without a significant performance cost."


Note that Professor Peter Alvaro is listed among the authors on the Twizzler paper, the very same that gave us Chaos Engineering in the form of Lineage Driven Fault Injection https://blog.acolyer.org/2015/03/26/lineage-driven-fault-injection/.
On basically the same topic as the Twizzler paper, with a slightly different and very clever approach, I’d recommend looking into Dr Irene Zhang and the Demikernel https://irenezhang.net/papers/demikernel-hotos19.pdf. It was recently open sourced and can be found on Github here https://github.com/demikernel/demikernel
This scheme is reminiscent of the IBM AS/400 (aka “System i”, “i Series”, etc) and its Single Level Store, which puts all storage – volatile and persistent – in a single flat address space. In user-mode code, AS/400 pointers are 128 bits (which often meant some interesting changes when porting C programs; there’s no integer type large enough to hold a pointer value, for example). Those 16 bytes include a space identifier, pointer type, and other attributes, and an offset into the space. Under the covers, memory pointers are mapped to the MMU’s 64-bit virtual address space. As with capability architectures, attempting to redefine a pointer to refer to some other kind of object, or to modify its contents directly, results in a runtime exception.