Compress objects, not cache lines: an object-based compressed memory hierarchy Tsai & Sanchez, ASPLOS’19
Last time out we saw how Google have been able to save millions of dollars though memory compression enabled via zswap. One of the important attributes of their design was easy and rapid deployment across an existing fleet. Today’s paper introduces Zippads, which compared to a state of the art compressed memory hierarchy is able to achieve a 1.63x higher compression ratio and improve performance by 17%. The big idea behind zippads is simple and elegant, but the ramifications go deep: all the way down to a modified instruction set (ISA)! So while you probably won’t be using Zippads in practice anytime soon, it’s a wonderful example of what’s possible when you’re prepared to take a fresh look at “the way we’ve always done things.”
The big idea
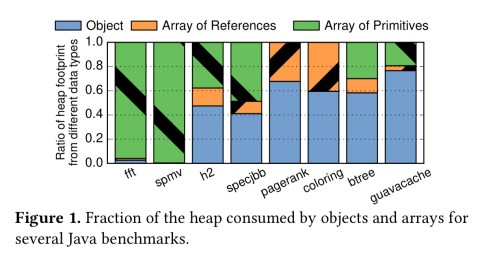
Existing cache and main memory compression techniques compress data in small fixed-size blocks, typically cache lines. Moreover, they use simple compression algorithms that focus on exploiting redundancy within a block. These techniques work well for scientific programs that are dominated by arrays. However, they are ineffective on object-based programs because objects do not fall neatly into fixed-size blocks and have a more irregular layout.
Scientific computing and machine learning applications may be heavily array dominated, but many applications are dominated by objects, which have a much more irregular layout and very different access patterns. Looking across a set of eight Java benchmarks, we find that only two of them are array dominated, the rest having between 40% to 75% of the heap footprint allocated to objects, the vast majority of which are small. Existing compression algorithms that rely on similarities between nearby words won’t work as well on these applications.
There are two big “Aha!” moments that underpin this work. The first one is that object-based applications perform memory accesses within objects and follow pointers to other objects:
Therefore objects, not cache lines, are the right compression unit.
The second insight is that although nearby words may not look similar, different instances of the same object type do.
Consider a B-Tree node from the B-tree Java benchmark:
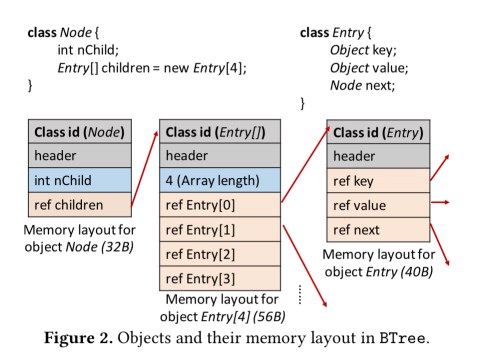
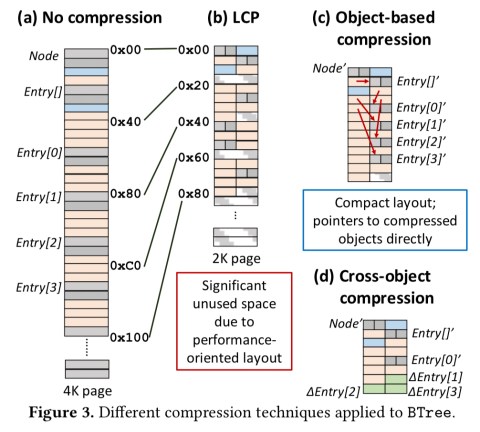
Uncompressed, it’s memory layout looks like (a) below. Compressed using LCP (a hybrid BDI + FPC compression technique) we can achieve a 10% compression ratio as shown in (b). If we compress objects instead of cache lines though, we can get to a 56% compression ratio (c). Finally, if we also use cross-object compression in which a base object is stored for each object type, and only the delta from the base object is stored for every instance, then we can get the compression ratio up as high as 95% (d)!
Implications
… to realize these insights, hardware needs to access data at object granularity and must have control over pointers between objects.
This is where Hotpads comes in. Hotpads is a hardware-managed hierarchy of scratchpad-like memories called pads. Pads are designed to store variable sized objects efficiently, and a key feature is that they transfer objects across pad levels implicitly (just like cache levels) based on memory accesses.
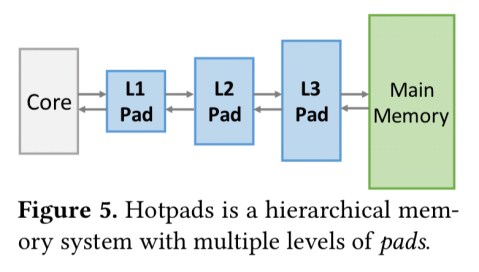
Objects are first allocated in the L1 pad and move up the hierarchy as they are evicted. Short-lived objects may be garbage collected before they ever reach main memory. The highest hierarchy level an object has reached is called its canonical level, and this level acts as the object’s backing store.
Hotpad modifies the ISA to make all this work (see Table 2 below). The ISA changes are transparent to application programmers, but require runtime and compiler modifications.

Collection evictions that move objects up the hierarchy occur entirely in hardware and are much faster than software GT because pads are small. Eviction cost is proportional to pad size, due to the constraint that objects may only point to objects at the same or higher canonical level. Thus we know when evicting an object from a smaller pad that no object at a larger pad can be holding a reference to it.
Zippads
Zippads extends Hotpads with compression. It can work with conventional compression algorithms such as BDI and FPC, but it works best with the COCO cross-object compression scheme.
New objects start their lifetime uncompressed, and if and when they make to to the last-level pad they are compressed there.
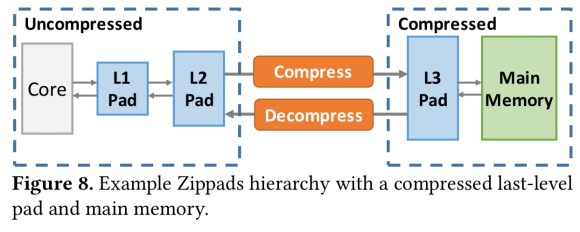
This is a key difference from conventional hierarchies, where objects are mapped to a main memory address to begin with, forcing the problem of translating from uncompressed to compressed addresses.
Compression information is encoded directly into pointers:

On dirty writebacks we have to consider the scenario whereby the new size of the compressed object no longer fits in its location. In this case Zippads allocates a new location and leaves behind a forwarding thunk in the old location. Overflows are rare in practice.
Zippads also enhances Hotpad’s periodic garbage collection to work on compressed objects.
COCO
COCO compresses an object by storing only the bytes that differ from a given base object. The compressed object format has three elements:
- A base object id
- A diff bitmap with one bit per byte of the object. Bit i is set if the ith byte differs from the base object.
- A string of byte diffs containing the bytes that are different from the base object.

All of this happens in hardware:
COCO compression/decompression circuits are simple to implement and only require narrow comparators and multiplexors. Our implementations compress/decompress one word (8 bytes) per cycle… We have written the RTL for these circuits and synthesized them at 45nm using yosys and the FreePDK45 standard cell library.
The process for selecting the base object for each type is simple: COCO simply uses the first object of each type that it sees. Base objects themselves are kept in a small and fast base object cache so that COCO has easy and fast access to them.
What about arrays?
We said at the start of all this that objects and arrays work best with different kinds of compression. We want Zippads to compress both well. Zippads addresses this by using different compression algorithms: COCO for objects and a conventional BDI+FPC algorithm for arrays. Metadata encoding the compression algorithm used is encoded in the pointers.
Evaluation
Zippads and COCO are evaluated on a mix of array-based and object-based workloads, including eight Java and two C/C++ benchmarks.
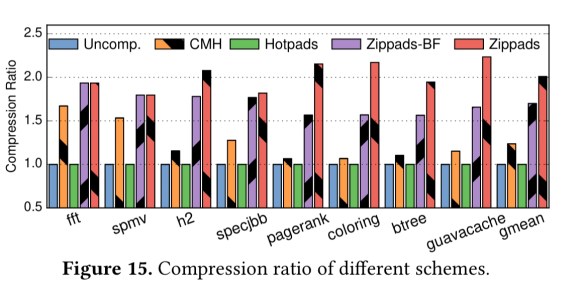
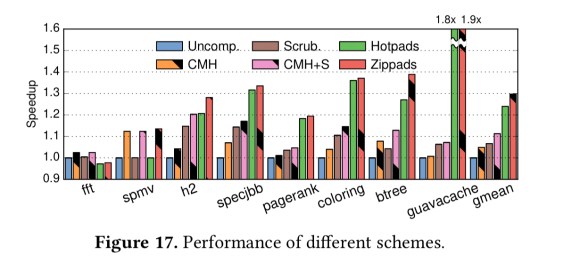
Zippads achieves the best compression ratios across all of the Java benchmarks. In the figure below, CMH is a state-of-art compressed memory hierarchy, hotpads is plain hotpads (no compression) and a three-level cache hierarchy, Zippads-BF is Zippads without COCO, and Zippads is the full Zippads with dynamic selection of compression algorithm including COCO.
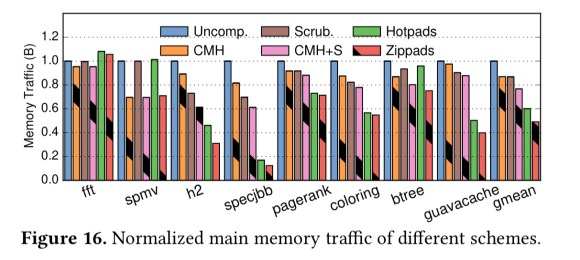
Zippads also has the best reduction in main memory traffic : halving the amount of traffic compared to the baseline.
Not only that, but Zippads improves performance over the baseline by 30% as well (and by 17% when compared against CMH).
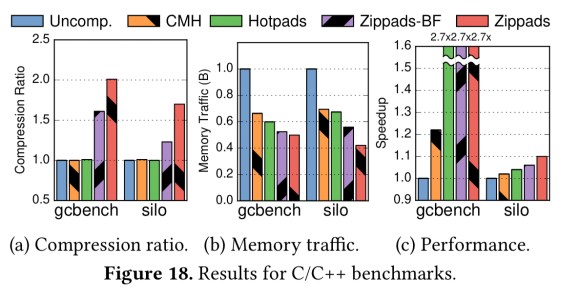
As the following plots show, it’s also highly effective on C/C++ benchmarks.
The bottom line:
Zippads + COCO improves compression ratio over a combination of state-of-the-are techniques by up to 2x and by 1.63x on average. It also reduces memory traffic by 56% and improves performance by 17%.

14 thoughts on “Compress objects, not cache lines: an object-based compressed memory hierarchy”
Comments are closed.