Learning certifiably optimal rule lists for categorical data Angelino et al., JMLR 2018
Today we’re taking a closer look at CORELS, the Certifiably Optimal RulE ListS algorithm that we encountered in Rudin’s arguments for interpretable models earlier this week. We’ve been able to create rule lists (decision trees) for a long time, e.g. using CART, C4.5, or ID3 so why do we need CORELS?
…despite the apparent accuracy of the rule lists generated by these algorithms, there is no way to determine either if the generated rule list is optimal or how close it is to optimal, where optimality is defined with respect to minimization of a regularized loss function. Optimality is important, because there are societal implications for lack of optimality.
Rudin proposed a public policy that for high-stakes decisions no black-box model should be deployed when there exists a competitive interpretable model. For the class of logic problems addressable by CORELS, CORELS’ guarantees provide a technical foundation for such a policy:
…we would like to find both a transparent model that is optimal within a particular pre-determined class of models and produce a certificate of its optimality, with respect to the regularized empirical risk. This would enable one to say, for this problem and model class, with certainty and before resorting to black box methods, whether there exists a transparent model. (Emphasis mine)
As a reminder, the outputs of CORELS are rule lists that look like this:

The models that CORELS creates are predictive, but they are not causal models and so they cannot be used for policy-making. Nor do they include the costs of true and false positives, or the cost of gathering the information required to feed the predictions. CORELS could be adapted to handle these kinds of problems in the future.
Jumping ahead to p39 in the paper, here’s an example that really brought home both these points and the power of interpretable models to me. It’s a model learned from New York City stop-and-frisk data to predict whether or not a weapon will be found on a stopped individual who is frisked and searched.

Does this mean we should institute a policy of stopping and frisking everyone who passes through a transit authority? Most of us would agree this is going too far, and it’s clearly not causal: passing through a transit authority does not cause you to carry a weapon! It also illustrates nicely the value of a simple interpretable model. I can look at these rules, understand the behaviour, and ask the question. Imagine an opaque black box implementing a similar decision process, it would be much harder to uncover what’s going on and have a conversation about whether or not that’s what we want!
Finding optimal rule lists
There’s a lot hiding behind that word “optimal.” Instead of finding a good-enough rule list, we have to find the best rule list (for some definition of best, which we’ll get to in a moment). That implies some kind of exhaustive search, in a very large search space! The key is figuring out when and where it’s safe to prune that search space, to make the problem tractable again.
The objective function (definition of ‘best’) for a rule list 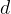
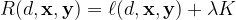
Setting 
Our objective has structure amenable to global optimization via a branch-and-bound framework. In particular, we make a series of important observations, each of which translates into a useful bound, and that together interact to eliminate large parts of the search space.
You can find a summary of these rules in section 3.3 on page 8, and the full explanation on pages 9-26. I’m going to stick with the summary!
- Lower bounds on any prefix of rules also hold for any extension of that prefix
- If a rule list is not accurate enough with respect to its length, all extensions of it can be pruned
- It is possible to calculate a priori an upper bound on the maximum length of an optimal rule list (and hence prune anything above this)
- Each rule in a rule list must have sufficiently large support. “This allows us to construct rule lists from frequent itemsets, while preserving the guarantee that we can find a globally optimal rule list from pre-mined rules.“
- Each rule in an optimal rule list must predict accurately. The number of observations predicted correctly by each rule in an optimal list must be above a threshold.
- It is only necessary to consider the optimal permutation of antecedents in a prefix, all other permutations can be pruned.
- If multiple observations have identical features and opposite labels, we know that any model will make mistakes. In particular, the number of mistakes on these observations will be at least the number of observations with the minority label.
The dominant calculations in the computation are computing the objective function lower bound and sometimes the objective function itself of a rule list. “This motivates our use of a highly optimized library, designed by Yang et al., for representing rule lists and performing operations encountered in evaluating functions of rule lists.”
CORELS places these calculations within the context of an incremental branch and bound algorithm. Prefix trees (tries) are used to support these incremental computations, a symmetry-aware map is used to facilitate pruning, and a worklist queue orders exploration over the search space. Different ordering policies (e.g. FIFO) can be used to express different search policies.
In our setting, an ideal scheduling policy would immediately identify an optimal rule list, and then certify its optimality by systematically eliminating the remaining search space. This motivates trying to design scheduling policies that tend to quickly find the optimal rule.
Use a priority queue with priority determined by ‘curiosity’ (a measure of the expected objective value of a rule list based on its relation to a rule list whose objective value we know) gave good results in many cases.
CORELS in action
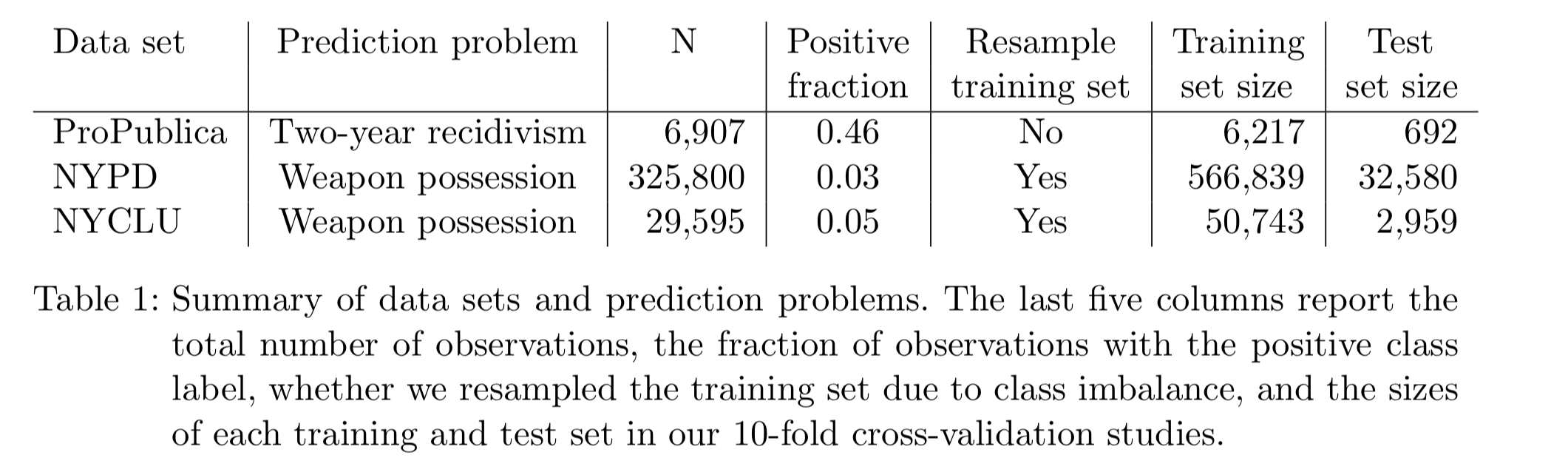
The evaluation focuses on two socially-important prediction problems: predicting which individuals will re-offend within two years (recidivism, cf. COMPAS), and predicting whether a stop-and-frisk procedure will uncover a weapon (based on NYC data).
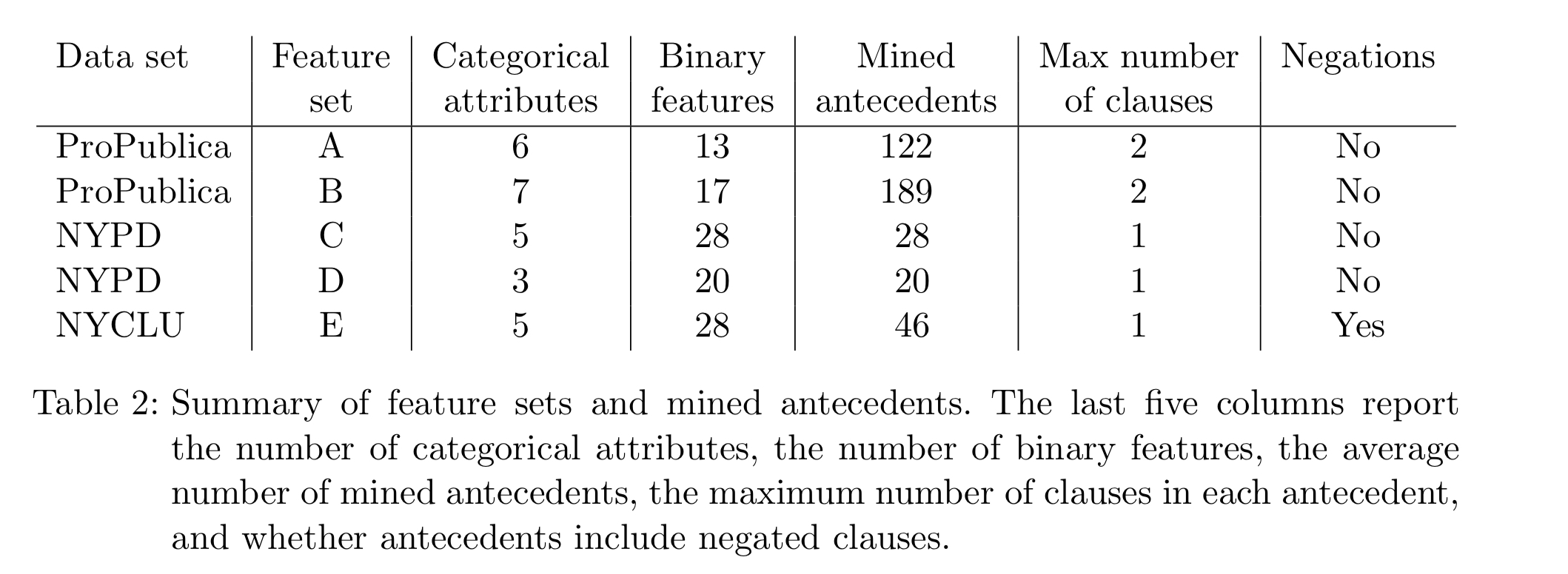
Here are the rule lists found for the ProPublica data set (recidivism):

(The reason CORELS doesn’t just make one rule for age 21-25 and 2-3 priors in the second case, is that the input feature space has different categorical values for age brackets ‘age 21-22’ and ‘age 23-25’ – i.e., CORELS doesn’t understand the mathematical relationship here.)
And here is an example rule list for the stop-and-search problem:
The accuracies of rule lists learned by CORELS are competitive with scores generated by the black box COMPAS algorithm at predicting two-year recidivism for the ProPublica data set.
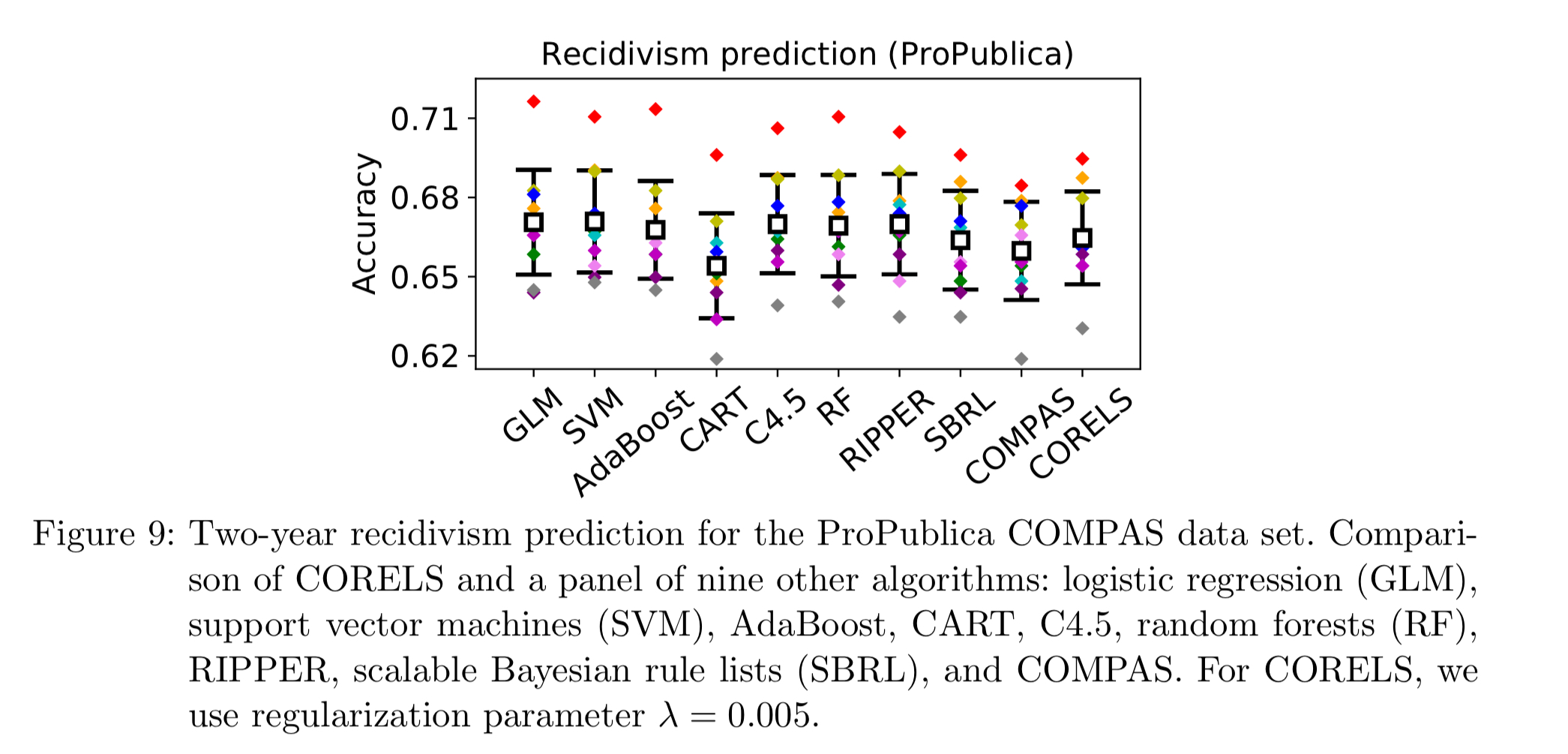
The optimal rule lists learned by CORELS have a mean test accuracy of 0.665, with standard deviation 0.018. COMPAS has a mean test accuracy of 0.660 with standard deviation 0.019.
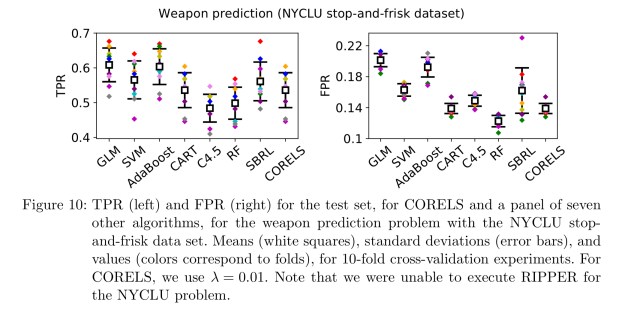
CORELS can also learn short rule lists without sacrificing performance in the NYCLU case too:
If you want to try CORELS for yourself, the code can be found at https://github.com/nlarusstone/corels, or even easier there’s an interactive web interface where you can upload your data and try it out right from within your browser.

3 thoughts on “Learning certifiably optimal rule lists for categorical data”
Comments are closed.