The seven tools of causal inference with reflections on machine learning Pearl, CACM 2018
With thanks to @osmandros for sending me a link to this paper on twitter.
In this technical report Judea Pearl reflects on some of the limitations of machine learning systems that are based solely on statistical interpretation of data. To understand why? and to answer what if? questions, we need some kind of a causal model. In the social sciences and especially epidemiology, a transformative mathematical framework called ‘Structural Causal Models’ (SCM) has seen widespread adoption. Pearl presents seven example tasks which the model can handle, but which are out of reach for associational machine learning systems.
The three layer causal hierarchy
A useful insight unveiled by the theory of causal models is the classification of causal information in terms of the kind of questions that each class is capable of answering. This classification forms a 3-level hierarchy in the sense that questions at level i (i = 1, 2 ,3 ) can only be answered if information from level j (j ≥ i) is available.
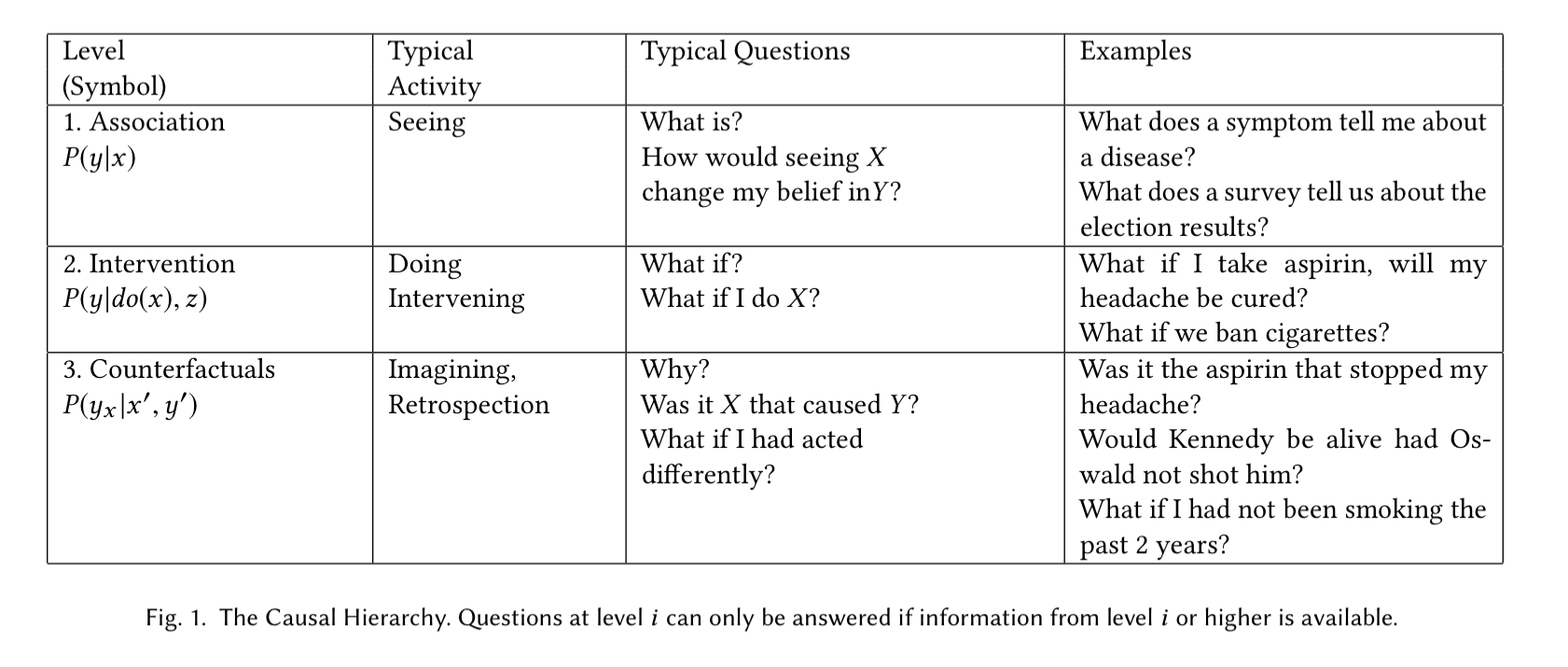
The lowest (first) layer is called Association and it involves purely statistical relationships defined by the naked data. This is the layer at which most machine learning systems operate.
Level two, Intervention involves not just seeing what is, but reasoning about the effects of actions you might take (interventions). I would argue that reinforcement learning systems operate at this level (e.g., ‘what will happen if I move my knight to this square?’). RL systems tend to operate in very well defined environments though, whereas the intervention layer envisioned here encompasses much more open challenges too. As an example of an intervention, Pearl provides the question “What will happen if we double the price?” (of an item we are selling).
Such questions cannot be answered from sales data alone, because they involve a change in customers behaviour, in reaction to the new pricing.
Personally, I would have thought that if we had sales data showing the effects of previous price increases (on the same or similar items) then it might well be possible to build a predictive model from that data alone. Pearl’s counter-argument is that unless we replicate precisely the market conditions that existed the last time the price reached double its current value, we don’t really know how customers will react).
The highest level of causal reasoning is called counterfactuals and addresses what if? questions requiring retrospective reasoning. On a small scale, this is what I see sequence-to-sequence generative models being capable of doing. We can ‘replay’ the start of a sequence, change the next data values, and see what happens to the output.
The levels form a hierarchy in the sense that interventional questions cannot be answered from purely observational information, and counterfactual questions cannot be answered from purely interventional information (e.g., we can’t re-run an experiment on subjects who were given a drug to see what would have happened had they not been given it). The ability to answer questions at level j though implies that we can also answer questions at level i ≤ j.
This hierarchy, and the formal restrictions it entails, explains why machine learning systems, based only on associations, are prevented from reasoning about actions, experiments, and causal explanations.
Structural Causal Models
Structural Causal Models (SCM) combine graphical modeling, structural equations, and counterfactual and interventional logic.
These tools permit us to express causal questions formally, codify our existing knowledge in both diagrammatic and algebraic forms, and then leverage our data to estimate the answers. Moreover, the theory warns us when the state of existing knowledge or the available data are insufficient to answer our questions; and then suggests additional sources of knowledge or data to make the questions answerable.
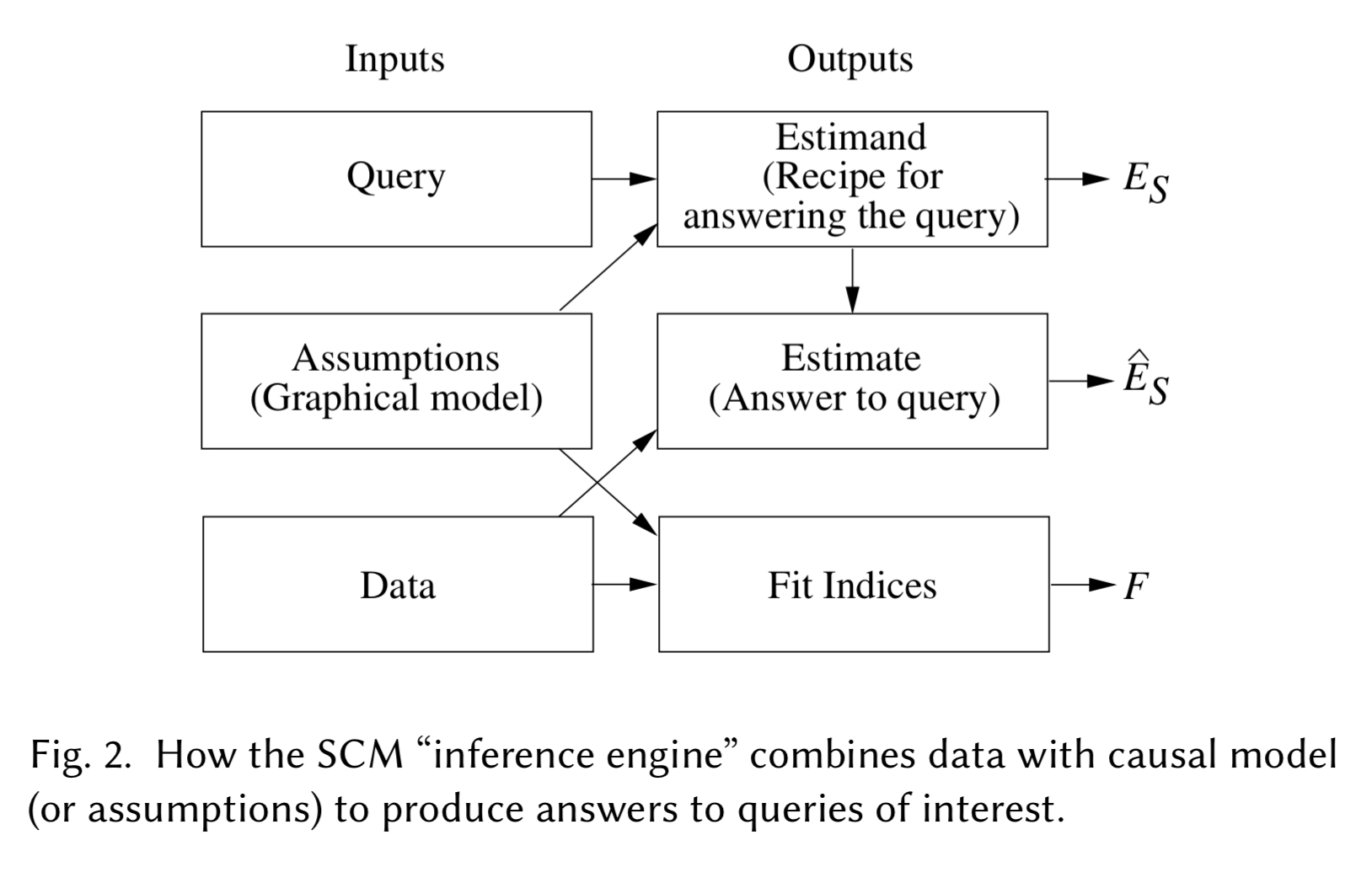
An SCM ‘inference engine’ takes as input assumptions (in the form of a graphical model), data, and a query.
For example, the following graph shows that X (e.g. taking a drug) has a causal effect on Y (e.g. recovery), and a third variable Z (e.g. gender) affects both X and Y.
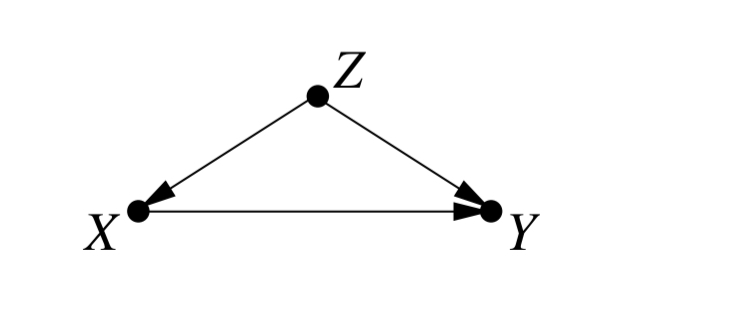
It reminds me of models I have seen in works on Bayesian decision making.
There are three outputs:
- The Estimand is a mathematical formula providing a recipe for answering the Query from any hypothetical data whenever available, given the assumptions.
- The Estimate is the answer to the query, along with statistical estimates of confidence.
- A set of Fit Indices measure how compatible the data are with the assumptions conveyed by the model. If the encoded assumptions do not have any testable implications then the set will be empty.
When the query cannot be answered given the model assumptions it is declared ‘unidentifiable’.
Fortunately, efficient and complete algorithms have been developed to decide identifiability and to produce estimands for a variety of counterfactual queries and a variety of data types.
What can SCM do for us?
Rather than dive deeper into the details of how SCM works, Pearl instead enumerates seven tools of causal reasoning enabled by the SCM framework.
1. Transparency and testability
Transparency enables analysts to discern whether encoded assumptions are plausible, and stems from the compact graphical representation.
Testability is facilitated through a graphical criterion called d-separation, which provides the fundamental connection between causes and probabilities. It tells us, for any given pattern of paths in the model, what pattern of dependencies we should expect to find in the data.
2. Do-calculus and the control of confounding
Confounding here seems to refer to the presence of latent variables which are the unobserved causes of two or more observed variables. How to select covariates to control for confounding was determined back in 1993, with the later do-calculus predicting the effects of policy interventions whenever feasible, and exiting with failure when the assumptions don’t permit predictions.
3. Counterfactuals
One of the crowning achievements of modern work on causality has been to formalize counterfactual reasoning within the graphical representation, the very representation researchers use to encode scientific knowledge. Every structural equation model determines the truth of every counterfactual sentence. Therefore, we can determine analytically if the probability of the sentence is estimable from experimental or observational studies, or combination thereof.
Mediation analysis
Mediation analysis concerns the discovery of intermediate mechanisms through which causes are transmitted into effects. We can ask queries such as “What fraction of the effect of X on Y is mediated by variable Z?”.
Adaptability, external validity, and sample selection bias
The problem of robustness [to change in environmental conditions], in its broadest form, requires a causal model of the environment, and cannot be handled at the level of Association… The do-calculus now offers a complete methodology for overcoming the bias due to environmental changes. It can be used both for re-adjusting learned policies to circumvent environmental changes and for controlling bias due to non-representative samples.
Recovering from missing data
Using SCM causal models it is possible to formalise the conditions under which causal and probabilistic relationships can be recovered from incomplete data and, whenever the conditions are satisfied, produce a consistent estimate of the desired relationship.
Causal discovery
The d-separation criterion let us detect and enumerate the testable implications of a given model. We can also infer the set of models compatible with the data. There are also methods for discovering causal directionality .
In conclusion
On the one hand, the article reads like a sales pitch for SCM, teasing us with possibilities and encouraging us to go deeper. That ‘associational machine learning’ methods are tied to the association level in the hierarchy seems to follow from the definition! (Are there machine learning methods which have escaped the purely associational? I hinted at a couple of techniques that seem to have done so earlier in the piece). On the other hand, the rich theory of causal reasoning does indeed seem to have much to complement traditional approaches to machine learning. Pearl certainly seems to think so!
…given the transformative impact that causal modeling has had on the social and medical sciences, it is only natural to expect a similar transformation to sweep through the machine learning technology, once it is enriched with the guidance of a model of the data-generating process. I expect this symbiosis to yield systems that communicate with users in their native language of cause and effect and, leveraging this capability, to become the dominant paradigm of next generation AI.
For an introduction to the theory for the general reader, Pearl’s recent book “The book of why: the new science of cause and effect” may be of interest. (Disclaimer: I haven’t read it yet, but I’m going to add it to my list!).

8 thoughts on “The seven tools of causal inference with reflections on machine learning”
Comments are closed.