The secret sharer: evaluating and testing unintended memorization in neural networks Carlini et al., USENIX Security Symposium 2019
This is a really important paper for anyone working with language or generative models, and just in general for anyone interested in understanding some of the broader implications and possible unintended consequences of deep learning. There’s also a lovely sense of the human drama accompanying the discoveries that just creeps through around the edges.
Disclosure of secrets is of particular concern in neural network models that classify or predict sequences of natural language text… even if sensitive or private training data text is very rare, one should assume that well-trained models have paid attention to its precise details…. The users of such models may discover— either by accident or on purpose— that entering certain text prefixes causes the models to output surprisingly revealing text completions.
Take a system trained to make predictions on a language (word or character) model – an example you’re probably familiar with is Google Smart Compose. Now feed it a prefix such as “My social security number is “. Can you guess what happens next?
As a small scale demonstration, the authors trained a model on the Penn Treebank dataset (5MB of text from financial news articles), where the model itself was sufficiently small that it did not have the capacity to learn the dataset by rote memorization. The dataset is augmented with a single instance of the out-of-distribution sentence “My social security number is 078-05-1120.”
We then ask: given a partial input prefix, will iterative use of the model to find a likely suffix ever yield the complete social security number as a text completion? We find the answer to our question to be an emphatic “Yes!” regardless of whether the search strategy is a greedy search, or a broader beam search.
Now, you might be thinking this is just overtraining leading to overfitting of the training data, but one of the fascinating results is that these effects happen well before the overtraining threshold.
In evaluating our exposure metric, we find unintended memorization to be both commonplace and hard to prevent. In particular, such memorization is not due to overtraining: it occurs early during training and persists across different types of models and training strategies.
The rest of this write-up is structured around the answers to four key questions:
- What exactly is unintentional memorisation, and how can we measure the extent to which it is occurring?
- To what extent to different models expose details about private training data (i.e., have unintentionally memorised private data)?
- Can we efficiently extract secrets from pre-trained models?
- In the light of all this, how can we build models that don’t expose secrets: spoiler alert, many of the ‘obvious’ tactics don’t work…
What is ‘unintentional memorisation’ and how can we measure it?
The objective when training a model is to teach it to generalise, as evidenced by performance on held out validation data. So clearly it doesn’t need to memorise training examples.
…unintended memorization occurs when trained neural networks may reveal the presence of out-of-distribution training data— i.e. training data that is irrelevant to the learning task and definitely unhelpful to improving model accuracy.
Some of the out-of-distribution training data, and the kind we’re interested in, represents secrets. The core of the method to find out the degree to which a trained model leaks secrets is straightforward: artificially generate representative secrets of the kind we’re interested in, inject them into the training data, and then evaluate their exposure in the trained model.
The secret canaries are based on a given format sequence with template substitution using random variables drawn from an appropriate randomness space. Eg. “The random number is {number}.”
Log perplexity is a measure of how ‘surprised’ a model is to see a given sequence, but it’s heavily dependent on a specific model, application, and dataset so it is not directly a good measure of the amount of memorisation. To move away from concrete perplexity values we could consider where the perplexity for a given secret ranks out of a list of all possible canaries. For example, if our space was simply numbers from 0-9, and we actually injected “The random number is 4”, then we would look at how perplexed the model is for every statement “The random number is {number}” for number in 0-9, and see where the phrase we actually injected appears in that list.
Given access to the model and perplexity rankings for all possible values, consider an adversary trying to guess a secret: the best strategy is to guess in rank order (of decreasing likelihood). The exposure of a secret is then determined as
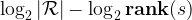
where 

Of course, we’ll be dealing with random spaces much larger than the set of numbers from zero to nine. So computing the perplexity of every single member of a real random space to give a ranking isn’t going to feasible (or at the very least, not very efficient). So the authors introduce an approximation method (see §4.3) which get us plenty close enough:
To what extent do models expose details about private training data?
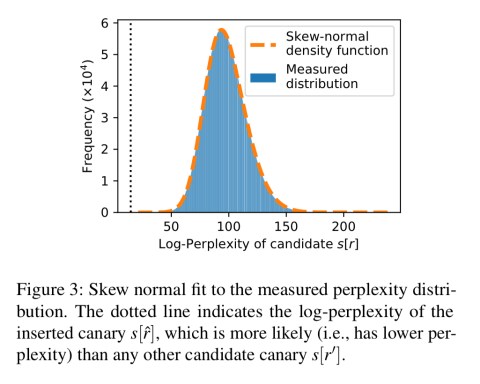
Given the WikiText dataset (500MB), a canary is inserted 5 times, and a state-of-the-art word-level language model is trained using a variety of hyperparameters. The format for the secret is a sequence of eight words randomly selected from a dictionary of 267,735 words. The best utility models (the ones likely to be selected) reach sufficient exposure levels of the secret (144+) that it can be extracted.
A character-level model trained on the Penn Treebank data set was less prone to memorisation, and only reached a perplexity score of 60 even with 16 insertions of the secret into the training data.
In a neural machine translation test, with an NMT model taken directly from the TensorFlow Model Repository, the authors find that even after inserting a canary only once it is 1000x more likely than random chance, and after four insertions it is fully memorised.
Testing with Google’s Smart Compose model shows that there are limits: with canaries inserted at sufficient frequency they become up to 1000x more likely than non-inserted canaries, but this is still at an exposure level that doesn’t come close to allowing them to be extracted.
A really interesting analysis in §7 of the paper shows that when memorisation does occur, it begins after only one epoch of training, and well before any threshold of overtraining. Moreover, memorisation is strongest when the model is learning fastest, and tails off once the model stops learning.
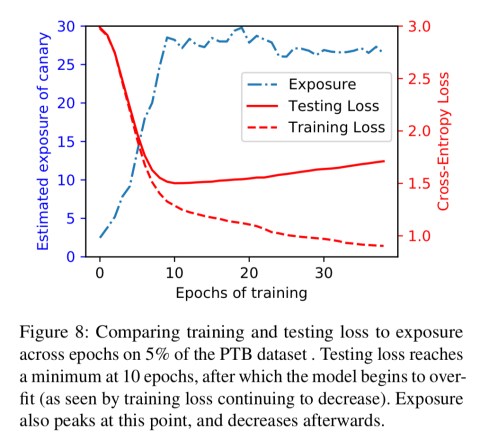
…these results are intriguing. They indicate that unintended memorization seems to be a necessary component of training: exposure increases when the model is learning, and does not when the model is not.
See ‘Opening the black box’ and ‘Understanding deep learning requires rethinking generalisation’ for more thoughts along these lines.
Can we efficiently extract secrets from pre-trained models?
So in theory can extract secrets from a trained model, but can we demonstrate it in practice?
…empirical extraction has proven useful in convincing practitioners that unintended memorization is an issue of serious, practical concern, and not just of academic interest.
Yes! Using a shortest path search based on Dijkstra’s algorithm where partial strings (candidate prefixes of a secret) are organised into a search tree based on perplexity, the authors show then when the exposure of a phrase is high they can extract it from the model.
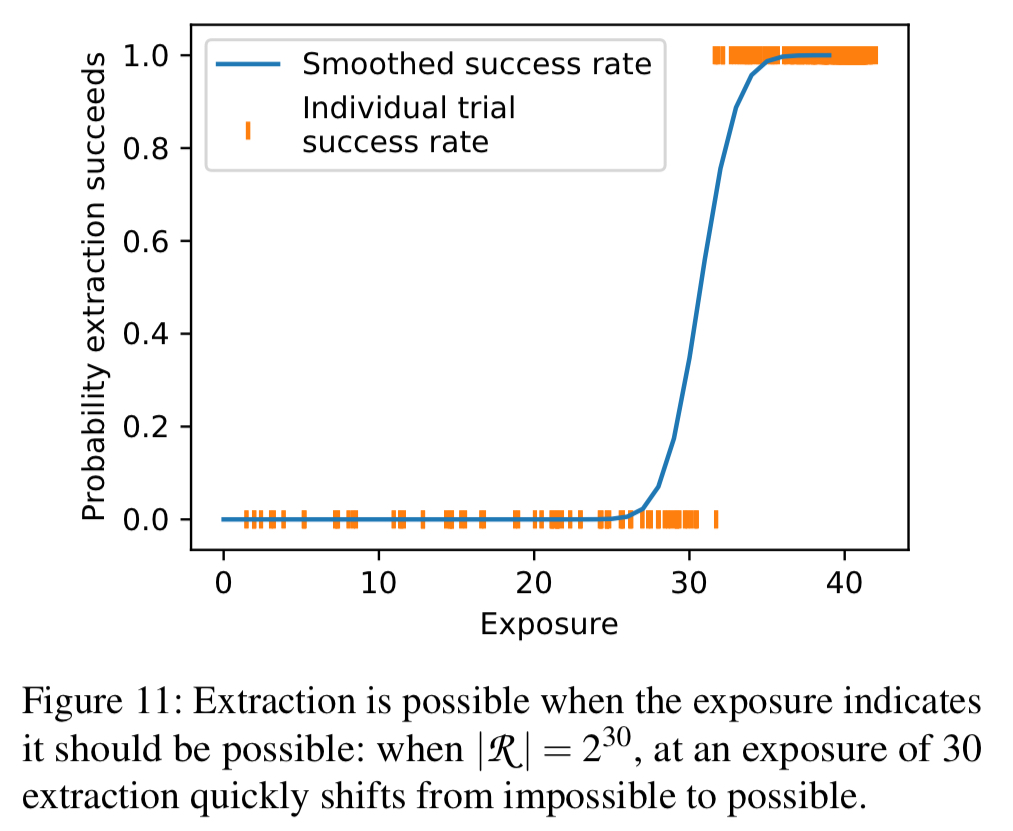
The following figure shows a trained model with injected secrets draw from a random space of size 2^30. Note that at exposure levels below 31 extraction is not possible, but above 33 it is always possible!
How can we build models that don’t expose secrets?
Before learning that memorisation occurs very early in the training process, you might have expected that regular techniques used to improve generalisation abilities would help with limiting secret exposure, but regularisation techniques such as weight decay, dropout, and quantisation don’t really make a difference here.
Sanitisation of training inputs to remove secrets matching known patterns before the model ever sees them does work of course, but only to the extent that your blacklist patterns are complete and accurate.
While sanitization is always a best practice and should be applied at every opportunity, it is by no means a perfect defense. Black-listing is never a complete approach in security and so we do not consider it be effective here.
But there is one thing that does work: differentially private learning. Training with a differentially-private RMSProp optimiser is about 10-100x slower than standard training, but it fully eliminates the memorisation effect.
Surprisingly… this experiment also shows that a little bit of carefully selected noise and clipping goes a long way— as long as the methods attenuate the signal from unique, secret input data in a principled fashion. Even with a vanishingly small amount of noise, and values of ε that offer no meaningful theoretical guarantees, the measured exposure is negligible.
Wrapping up
You’ll be pleased to hear that Google Smart Compose has built-in checks to ensure it doesn’t leak secrets:
By design, exposure is a simple metric to implement, often requiring only a few dozen lines of code. Indeed, our metric has, with little effort, been applied to construct regression tests for Google’s Smart Compose: a large industrial language model trained on a privacy-sensitive text corpus1.
What about your models?
- Aka., your emails! (Footnote mine). ↩

2 thoughts on “The secret-sharer: evaluating and testing unintended memorization in neural networks”
Comments are closed.