Fine-grained, secure and efficient data provenance on blockchain systems Ruan et al., VLDB’19
We haven’t covered a blockchain paper on The Morning Paper for a while, and today’s choice won the best paper award at VLDB’19. The goal here is to enable smart contracts to be written in which the contract logic depends on the history, or provenance of its inputs.
For example, a contract that sends a reward amount of tokens to a user based on that user’s average balance per day over some period.
That’s hard to do in today’s blockchain systems for two reasons:
- Provenance can only be determined by querying and replaying all on-chain transactions, which is inefficient and an offline activity.
- As a consequence the computation of provenance and issuing a subsequent transaction are decoupled and hence there are no serializability guarantees. “In blockchains with native currencies, serializabiliy violations can be exploited for Transaction-Ordering attacks that cause substantial financial loss to the users.”
In other words, smart contracts cannot access historical blockchain states in a tamper-evident manner.
In designing a blockchain-friendly provenance mechanism, three aspects unique to the blockchain environment differentiate the problem from that of traditional database provenance:
- There are no higher-order data operators (e.g. join) whose semantics capture provenance in the form of input-output dependencies. Instead we have to work directly in terms of smart contract read and write sets.
- Blockchains assume an adversarial environment, so the captured provenance must be made tamper-evident
- Provenance queries must be fast to avoid imposing a large cost on miners during verification (see the Verifier’s Dilemma).
Let’s look at each of these in turn.
Capturing provenance
In LineageChain, every contract method can be made provenance-friendly via a helper method (
prov_helper).
LineageChain invokes prov_helper immediately after every successful contract execution. If the smart chain developer doesn’t provide an implementation, then the default behaviour is to make all identifiers in the read set of the transaction be dependencies of every write in the write set.
My biggest question here is what guarantees we can have on provenance when the developer does provide their own implementation. Since we’re assuming an adversarial environment, what stops the prov_helper method from making up whatever it likes? The paper is silent on this question. Presumably we can always check that a write dependency is not declared on a read we didn’t make (because we know the read set), and likewise we can check that we’re not claiming any writes we didn’t make. But outside of that, the whole point of the helper method seems to be to give the developer control over the provenance. For example, suppose the read set is 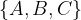
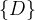
Anyway, putting that question aside, once we’ve got provenance data, smart contracts can access it via three additional smart contract APIs that are exposed: Hist for finding the value of a stateID at the start of a given block, Backward for tracing provenance backwards in the chain, and Forward for tracing provenance forwards in the chain.
Here’s an example that marks an address as blacklisted if one of its last 5 transactions is with a blacklisted address.

Securely storing provenance information
To securely store provenance information, LineageChain turns the original Merkle tree backing a blockchain into a Merkle DAG.
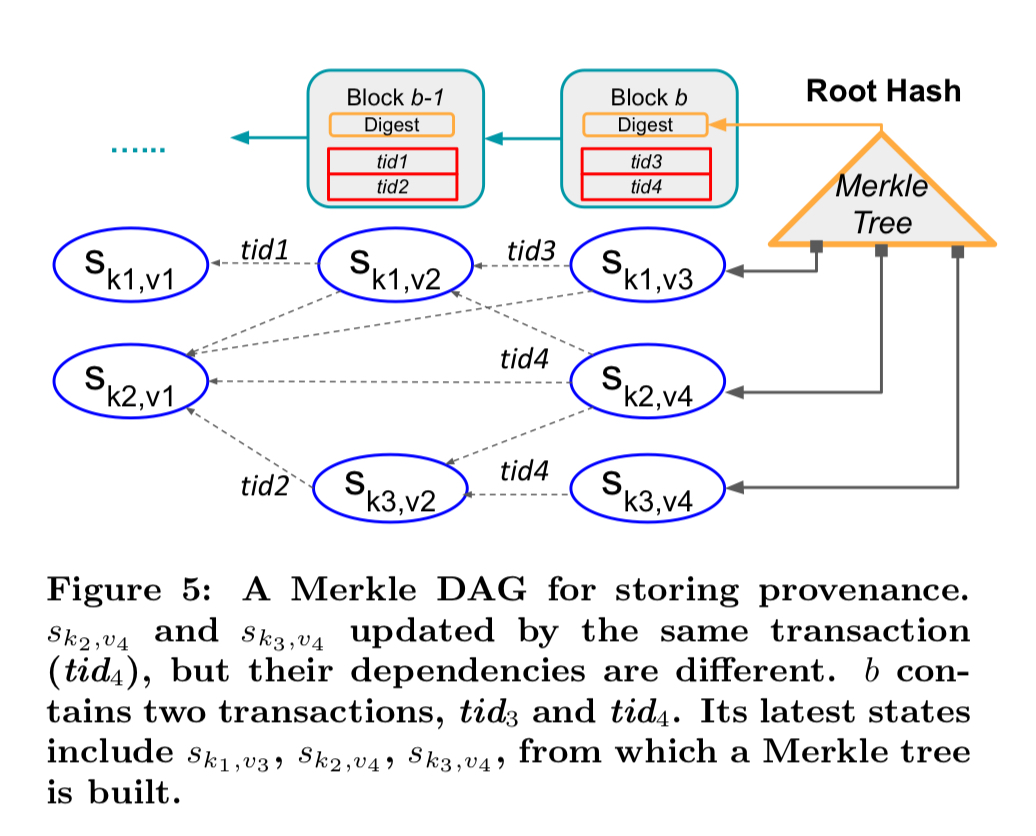
In the above figure, 
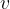
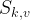
You can see in the figure above that the Merkle tree has additional branches feeding into the root, one for each tracked smart contract, with the smart contract state hashes aggregating along transaction dependency edges.
Our new Merkle DAG can be easily integrated to existing blockchain index structures…. Since the [state entry hash] is protected by the Merkle index for tamper evidence, so is the state history. In other words, we add integrity protection for provenance without any extra cost to the index structure.
Forward dependencies for a version 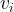

Making provenance queries fast
At this point we have the structures and APIs needed to make version queries, but now we need to make them fast. This is especially important since version queries will have to be executed by miners during verification, and we don’t want an adversary to deliberately submit expensive version queries (e.g. starting from a very early block id).
The solution here is to build a skip-list based index on top of the Merkle DAG. Compared to a normal skip list we have two additional properties: (i) we know that the blockchain is append-only, and (ii) the index structure is uniquely determined by the values of the appended items. This gives us a Deterministic Append-Only Skip List (DASL).
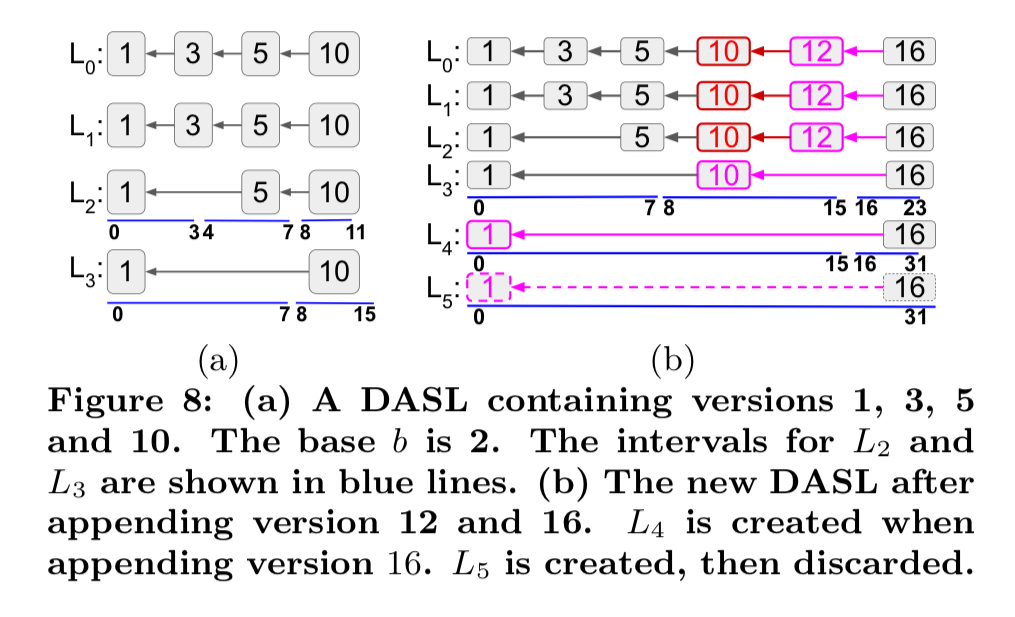
DASL queries are executed in just the same way as for a regular skip list, appends are made using the algorithm below:

The node structure for the DASL nodes is stored in the Merkle DAG state entries. For permissioned blockchains we’re all set. For permissionless blockchains we also need to figure out who pays for the extra storage overheads…
As DASL consumes resources, its costs must be explicitly accounted for in permissionless blockchains. More specifically, during deployment, the contract owner specifies which states require DASL support. Alternatively, DASL support can be automatically inferred from the contract’s source code. The deployment fee should reflect this extra storage cost for DASL…
Implementation and evaluation
The implementation is part of the Hyperledger++ project, and the evaluation uses Blockbench. Full details can be found in sections 6 and 7 of the paper, but the short version is this:
We implemented LineageChain on top of Hyperledger and benchmarked it against several baselines. The results show the benefits of LineageChain in supporting rich, provenance-dependent applications. They demonstrate that provenance queries are efficient, and the system incurs small storage overhead.

Hi, Adrian,
I am Pingcheng, the first author of this paper.
First thank you so much by selecting my paper as today’s morning paper.
I have been your honest blog reader for years.
To be honest, I feel even more pleasant to be selected than winning the best paper.
Let me clarify your biggest question: when the developer does provide their own prov_helper implementation in such adversarial environment.
In typical attack model assumed by blockchain research, the contract developer are honest. When they write their contracts, they expect their logic to be honestly executed by the blockchain network. It is the blockchain node operators which are not trusted (to execute the transactions based on the contract and the protocol). That’s why the protocol of all permissionless public blockchains specify the state digest in the block header. It faciliates all the honest nodes (who follow the protocol strictly) to easily synchronize to the common state.
As you have mentioned, one of the contribution of our paper is how to extend such state digest to incorporate into the provenance information. That’s why we make up a Merkle DAG to secure the states and provenance information.
Another rationale to explain why contract developer must be honest is because they normally place some own crytocurrency inside their developed and deployed contracts, like Ethereum. Due to the economic incentive, they definitely hope that contracts are later executed as expected based on the protocol.It is even true for malicious contract developers, as they aim to manipulate the existing logic for their own goodness.
Even if the contract developer is indeed malicious, (by making up whatever it likes), the protocol designer can simply prohibit this problem why defining the provenance validation rule (the dependency is only allowed to touch the existing read write sets) as part of the protocol. Transactions which break this rule may will be deemed invalid and the consensus protocol will make sure to dispel them in the chain.
For any curious reader, pls feel free to contact me via the email.
Sincerely,
Pingcheng