Updating graph databases with Cypher Green et al., VLDB’19
This is the story of a great collaboration between academia, industry, and users of the Cypher graph querying language as created by Neo4j. Beyond Neo4j, Cypher is also supported in SAP HANA Graph, RedisGraph, Agnes Graph, and Memgraph. Cypher for Apache Spark, and Cypher over Gremlin projects are also both available in open source. The openCypher project brings together Cypher implementors across different projects and products, and aims to produce a full and open specification of the language. There is also a Graph Query Language (GQL) standards organisation.
Cypher is used in hundreds of production applications across many industry vertical domains, such as financial services, telecommunications, manufacturing and retails, logistics, government, and healthcare.
Personally I would have expected that number to be in the thousands by now and there are some suggestions that it is, however Neo4j are still only claiming ‘hundreds of customers’ on their own website.
The read-only core of the Cypher language has already been fully formalised. But when it came time to extend that formalism to include the update mechanisms, the authors ran into difficulties.
Our understanding of updates in the popular graph database model… is still very rudimentary.
What follows is based on the Cypher 9, the current release of the language in Neo4j at time of writing (Neo4j v4.0 alpha is at milestone release 2 at the moment, from the release notes it looks like this version is still based on Cypher 9 afaict, but happy to stand corrected if anyone knows better). Cypher expressions can mix update and query clauses, and the intersection of those two clause types hides a number of dark corners.
After presenting the current state of update features, we point out their shortcomings, most notably violations of atomicity and non-deterministic behaviour of updates. These have not been previously known in the Cypher community.
(Emphasis mine).
Violations of atomicity and non-deterministic update behaviour certainly don’t sound like the kind of things you want in a database!! Fear not, because the outcome of this paper is a set of changes to the Cypher language and semantics which will be incorporated in Cypher 10, restoring law and order. Well, maybe fear a little bit if you’re still using a product based on Cypher 9 or lower ;).
Cypher query language essentials
Let’s use some example queries to get a feel for the Cypher language as it is today. This query finds all vendors offering two products, one of which has the name “laptop” (note that Cypher requires distinct relationship patterns in a query pattern, in this case the ‘arrows’ leading to p and q, to be matched to distinct relationships in the graph).

Note the ‘ASCII art’ style following the arrows from the central v: Vendor node matching pattern.
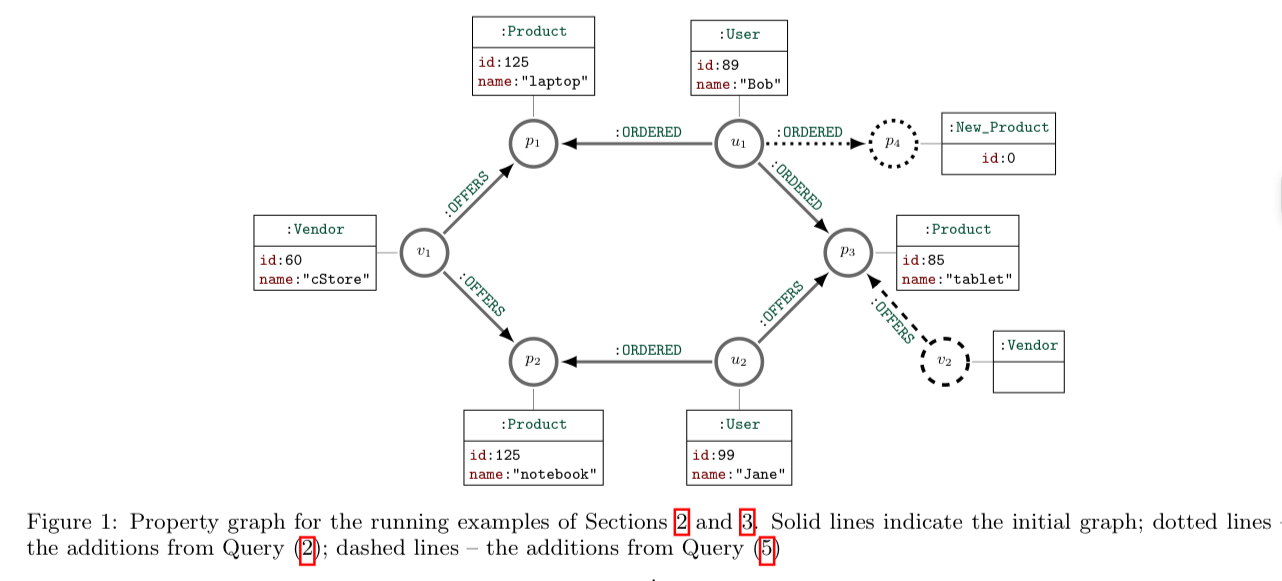
In execution, the MATCH clause populates what’s known as a driving table with 
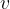
Once we start including updates, things get more interesting :
Cypher’s modular nature allows for chaining arbitrary sequences of reading and writing clauses in one single query, which raises questions regarding atomicity of statements and transaction boundaries.
The CREATE clause inserts new relationships into the graph. For example:
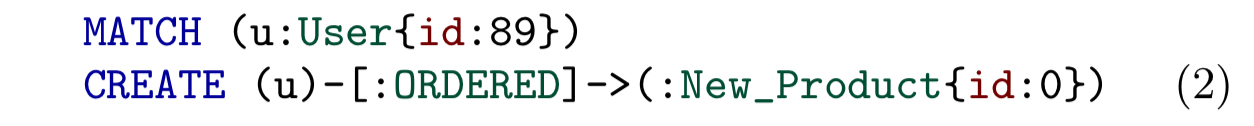
SET and REMOVE manipulate node labels and property maps on existing nodes and relationships (i.e., update):

After CREATE and the update methods, we of course have DELETE!

Graphs aren’t allowed to have any ‘dangling relationships’, so there’s a cascading delete operation called DELETE DETACH will delete all relationships attached to a node at the same time as the node is deleted.
We can mix all this up in something that’s starting to feel half like an imperative script and half like a declarative query:

Finally, there’s an upsert operation called MERGE which will update existing matched patterns, and create new instances if there is no match.
What’s up with updates?
While the update operations described in the previous section may seem clean and simple on the surface, they do in fact have some problems when one takes a closer look.
- SET with multiple variables doesn’t work like you’d expect in SQL. In the following code we don’t in fact swap ids, but instead have the (probably unintended by the user) semantics of implementing the two SETs in series (i.e, the second set does nothing at all here).

- SET can give ambiguous results in the presence of multiple pattern matches. If we have two nodes with the label
Productandid125 in the graph, what’s the value ofp1.nameafter executing the following Cypher statement?

- DELETE can violate atomicity – for example you can set properties of deleted nodes! In the following contrived (but legal!) query, the working graph is in an illegal state after the first DELETE clause where there are dangling relationships, and there could be much more complex data querying on this intermediate state than in this example.

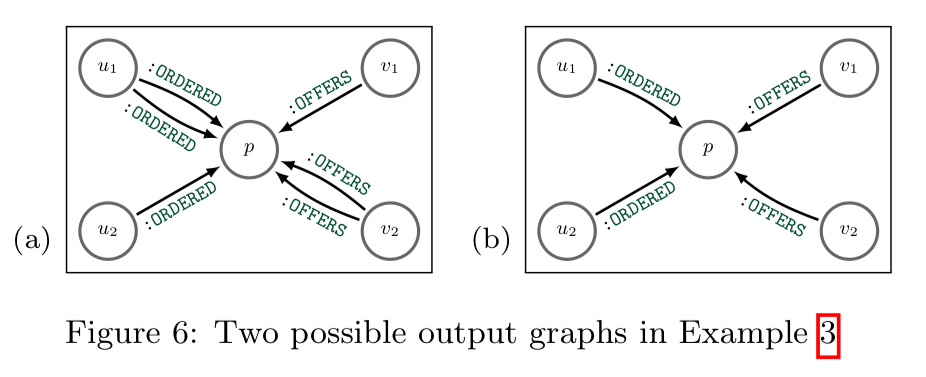
- MERGE has a problem whereby it can read its own writes. This violates clause atomicity and can also lead to cases where the output graph of a MERGE clause depends on the (undefined) processing order of nodes in the driving table. For example, given the following query and associated driving table, we could produce either Fig 6(a) or Fig 6(b) as legitimate outputs depending on processing order.

A path forward
These examples where discussed participants of the open-Cypher Implementers Meeting, and members of Neo4j’s Field Engineering and Developer Relations teams. The straightforward proposal to enforce atomicity of SET and DELETE was overwhelmingly supported (see §7 for details).
[The SET and DELETE] clauses must enforce atomicity, i.e., they cannot see partial results of deletions or changing of values. Indeed, these clauses have their direct SQL counterparts (although they add more complex pattern matching machinery), and thus we can adopt well known solutions from the relational world.
Figuring out what to do about MERGE turned out to be more complicated. This is made harder by the fact that users don’t really understand the current behaviour, and often end up unintentionally creating duplicate nodes and relationships. But there was clear support from the Neo4j teams for
(i) Deterministic and atomic semantics for merge, with clarity on hat in being merged on, and what is expected to be unique
(ii) Amending the term and its syntax to be closer in line with the way that users actually think it works today
Since the core issue with MERGE is that it can read its own writes, the essential idea is to clearly separate the reading (MATCH-like) parts of merge from the writing (CREATE-like) parts. The authors present 4 different variations of how this could be done, and the Neo4j team have chosen to support 2 of those in forthcoming Cypher: Atomic merges (keyword MERGE ALL) and Strong collapse merges (keyword MERGE SAME).
Atomic merge creates a copy of the input pattern for each record in the driving table for which the pattern could not be matched in the original input graph. Once all patterns have have captured, they are all added to the graph in a single atomic step.
Strong collapse merge groups records in the driving table by expressions appearing in the pattern, creating just one copy for each group. All newly created nodes that have the same labels and properties are also collapsed into one, as are all newly created relationships with identical types, properties, and source and target nodes.
Section 8 in the paper outlines how the formal semantics already defined for the core of Cypher can be extended to support the full language given the changes above.
Cypher 10
All of this goodness should be coming to Cypher and Neo4j soon:
Neo4j plans to integrate the refinements and corrections into its Cypher implementation in future versions of the Neo4j database system under the existing deprecation regime to avoid or minimize query breakage for customers. In the Cypher for Apache Spark project and its related upcoming product Neo4j Morpheus, Neo4j is already implementing the MERGE ALL and MERGE SAME clauses as part of the multiple graphs and graph construction capabilities of Cypher 10.

Hi, I’m the project lead and editor for GQL and a co-author of the paper.
Thanks for the review, indeed it is a great example for successful collaboration between industry and academia.
Some of the outcomes are great finds that will help define sane update semantics for graph querying. It is also worth saying that while these issues do show up in practice they are not as frequent as one might think due to actual usage patterns. For example, many users of Cypher mostly use MERGE with single node or single relationship patterns on properties matched with simple expressions that are controlled by a unique constraint. This typically tends to avoid the problems described.
We will continue to explore these questions both for Neo4j and in the context of GQL which just was officially inaugurated as a new project by ISO (The first language by the SQL standards committee since SQL). More details can be found at: https://neo4j.com/press-releases/query-language-graph-databases-international-standard/
Cheers