Statiscal foundations of virtual democracy Kahng et al., ICML’19
This is another paper on the theme of combining information and making decisions in the face of noise and uncertainty – but the setting is quite different to those we’ve been looking at recently. Consider a food bank that receives donations of food and distributes it to those in need. The goal is to implement an automated decision making system such that when a food donation is received, the system outputs the organisation (e.g. housing authority or food pantry) that should receive it. We could hard code a set of rules, but what should they be? And who gets to decide?
A democratic solution to this would be to give each of the stakeholders a vote on every decision. In the food bank setting, identified classes of stakeholders include the donors, the recipients, the volunteers (who pick up food from the donor and deliver it to the recipient), and employees. Their votes encode their own preferences and biases, perhaps in a way that even the voters themselves couldn’t neatly codify in a set of explicit rules.
It’s not really practical to have an actual vote with all stakeholders participating every time a food donation is made though!
One of the most basic ideas underlying democracy is that complicated decisions can be made by asking a group of people to vote on the alternatives at hand. As a decision-making framework, this paradigm is versatile, because people can express a sensible opinion about a wide range of issues. One of its seemingly inherent shortcomings, though, is that voters must take the time to cast a vote— hopefully an informed one— every time a new dilemma arises.
The big idea behind virtual democracy is that we learn the voting preferences of each stakeholder, essentially creating an agent which is able to vote in their place, a virtual voter. Then when we need to make a decision we ask those virtual voters to cast their votes (in the form of a preference ranking). The central question in this paper is this: given a set of preference rankings, how should we combine them to produce an actual decision? The procedure for doing this is known as the voting rule.
… the choice of voting rule can have a major impact on the efficacy of the system. In fact, the question of which voting rule to employ is one of the central questions in computational social choice.
It’s one thing to come up with a voting rule that works well when we have the actual true preference rankings of all of the stakeholders. In a virtual democracy setting though, where we have learned approximations to those preference rankings, a highly desirable feature of a voting rule is that it is robust to noise. I.e., we want a voting rule whereby…
… the output on the true preferences is likely to coincide with the output on noisy estimates thereof.
Learning preferences
To learn voter preferences, voters are asked to make a set of pairwise comparisons (about 100) between alternatives. I.e., given this donation, should it be sent to recipient A or recipient B? Each alternative is presented as a set of pre-determined features. In the case of the food bank question voters are given information about the type of donation, and seven additional features such as distance between the donor and recipient, and when the recipient last received a donation.
At the end of this process, the training data is used to learn a model of the preferences of the voter. This model is then used to predict the voter’s preference ranking over many hundreds of recipients for a given donation.
The Mallows model
To be able to compare the efficacy of various voting rules, we’re going to need a way to compare how good their outputs are. The Kendall tau (KT) distance between two rankings (permutations) of a set is defined as the number of pairs of alternatives on which the rankings disagree. By disagree we mean that given a pair 
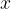
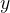
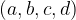
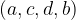
The Mallows (1957) model was originally designed for use in situations where there is true ranking of the alternatives, and assigns a probability that a given voter is associated with a given alternative ranking. The probability decreases exponentially with the number of pairs of alternatives on which the true and alternative ranking disagree, i.e., their KT distance. A Mallows model is parameterised by a parameter ![\phi \in (0,1]](https://s0.wp.com/latex.php?latex=%5Cphi+%5Cin+%280%2C1%5D&bg=ffffff&fg=000000&s=1&c=20201002)
Our technical approach relies on the observation that the classic Mallows (1957). model is an unusually good fit with our problem.
In the problem at hand, instead of a single true ranking, each voter has their own true ranking. When validating a learned model, the test for accuracy is done using pairwise comparisons, just like in Mallows. Given an observed prediction accuracy 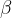
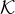
Voting rules and the Borda count
The next piece of the puzzle is the selection of a voting rule to combine rankings and produce a final decision. The main result in the paper concerns the Borda count voting rule. Borda count is a positional scoring rule. Positional scoring rules give a score vector that assigns points to each position in a ranking. E.g. 5 points for being ranked first, 3 points for being ranked second, and so on. The score of an alternative is the sum of its ranking points across all of the voters. The alternative with the biggest score wins (break ties via random selection).
The Borda count uses a very straightforward score vector: if there are 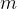
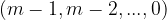
The heart of the paper is §4, where drawing on the properties of the Mallows model, it’s relationship to the predicted accuracy, and the Borda count rule, the authors show the Borda count is surprisingly robust to noise. I’m going to happily skip over the proofs here and leave you to follow up on those if you’re interested!
… it is intuitive that the separation in Borda scores has to depend on
Other rules
So far so good, but what about other voting rules? Are they also robust to noise or is there something special about the Borda count? The main alternative to positional scoring rules are pairwise-majority consistent (PMC) rules, of which there are many examples (e.g., the ranked pairs method). The key result in §5 of the paper is that all rules in this class are not robust to noise.
It is instructive to contrast our positive result, Theorem 1, with this negative result. On a very high level, the former result asserts that “if Borda count says that the gaps between alternatives are significant, then the alternatives will not flip under Borda count,” whereas the latter says “even if a PMC rule says that the gaps between alternatives are very significant, some alternatives are likely to flip under that rule.”
Borda count FTW
So there you have it: if you need to robustly combine noisy rankings of alternatives to make a decision, use the Borda count!
Our theoretical and empirical results identify Borda count as an especially attractive voting rule for virtual democracy, from a statistical viewpoint.
Another important feature of the Borda count rule is that the decisions it takes can be easily explained. An explanation consists of two elements: first the average position in the predicted preferences of each of the stakeholder groups, and second the features that were most important in achieving that ranking position (possible since alternatives are presented as vectors of features).

There are several good books on voting problems. Might be worth reading:
Gaming The Vote: Why Elections Aren’t Fair by William Poundstone ISBN 9780739499214
Decisions and Elections: Explaining The Unexpected by Donald G.Saari ISBN 0521004047
Basic Geometry of Voting by Donald G. Saari ISBN 9783540600640
Mathematics and Politics: Strategy Voting Power and Proof by Alan D Taylor ISBN 0387943919
Chaotic Elections!: A Mathematician Looks at Voting by Donald G. Saari ISBN 0821828479
What a great list, thank you!
And for explanations of the de Borda count that are clear to non-mathematicians read one of Peter Emerson’s books. See http://www.deborda.org.