What bugs cause production cloud incidents? Liu et al., HotOS’19
Last time out we looked at SLOs for cloud platforms, today we’re looking at what causes them to be broken! This is a study of every high severity production incident at Microsoft Azure services over a span of six months, where the root cause of that incident was a software bug. In total, there were 112 such incidents over the period March – September 2018 (not all of them affecting external customers). Software bugs are the most common cause of incidents during this period, accounting for around 40% of all incidents (so we can infer there were around 280 incidents total in the pool).
The 112 incidents caused by software bugs are further broken down into categories, with data-format bugs, fault-related bugs, timing bugs, and constant_value bugs being the largest categories. Interestingly, outages caused by configuration errors represented only a small number of incidents in this study. This could be an artefact of that data set in some way, or it might be due to the tool chain that Microsoft uses:
The types of bugs we observed in production are biased by the fact that Microsoft uses effective tools to mostly eliminate many types oft bugs before they can manifest in production, and hence our study includes zero or few of such bugs. For example, we observed only a small number of configuration bugs caused by mis-specification of configuration entries in configuration files, even though such bugs were reported to be common in other settings.
Most Azure code is written in .Net managed languages such as C#, reducing memory leak bugs. Tools like CHESS and PCT are used to expose shared-memory concurrency bugs. TLA+ is used to model concurrent and distributed system protocols helping to eliminate high level design and semantic bugs. In addition, Azure’s Fault Analysis Service supports various types of fault injections during testing, such as node restart, data migration, and random faults. Microsoft is also using fuzz testing, cloud contract checking, and network configuration verification tools.
Data formats
Of the software bugs that survive all of this and end up causing high severity incidents, one of. the most common causes are data format change (21%).
Different components of cloud services interact with each other through various types of “data”, including inter-process/node messages, persistent files, and so on. At the same time, cloud software goes through frequent updates. As a result, different software components in the cloud could hold conflicting assumptions about the format of certain data, leading to service incidents.
It looks like data validation isn’t only useful in a machine learning context!
All but one of the data format bugs involved multiple processes or nodes. In 40% of cases different parties assume different formats for shared files or database tables. For example, an upgrade has been deployed to a component ‘owning’ the table which changes the schema. The other 60% of cases are caused by a service changing the interface of its external message APIs. For example, a service that used to return 200 together with an empty list when no results were found changes to returning a 404, and breaks existing clients.
The large scale, frequent updates, and long running nature of cloud services likely have facilitated the occurrence of these bugs.
I’d expect this class of bugs to also surface in microservices systems. Does that match your experience?
Fault related
Next up is an old chestnut: error and exception handling faults (31%).
- Components that fail and report an error that can’t be handled (e.g., missing exception handlers) (43% of this category)
- Unresponsive components that hang and are not picked up by fault-detection mechanisms, leading to user-visible timeouts (29% of this category)
- Silent corruption of data with no error detection code in place, leading to incorrect results returned to users (17% of this category)
Exception / error handlers contribute to the incidents by either ignoring error reports (35%), over-reacting (35%), or containing bugs within the handlers themselves leading to infinite loops, timing issues, and so on (30%).
Timing incidents
13% of the incidents are related to timing, with only 14% of the timing incidents actually recorded as deadlocks. Compared to classic timing bugs racing between threads in the same process, here many of these bugs are about race conditions between multiple nodes and many of them are racing on persistent data like cached firewall rules, configuration, database tables, and so on.
Constant-value setting incidents
7% of all software bug incidents are caused by mistakes in constants: hard-code configuration, special purpose strings such as URLs, and enum-typed values.
Bug resolution
Facing tight time pressure, more often than not, software bug incidents were resolved through a variety of mitigation techniques (56%) without patching the buggy code (44%), providing quick solutions to users and maximizing service availability.
(Mitigated incidents may well have been followed up later with code changes, but these aren’t recorded in the respective incident reports).
When mitigating there are three main types of mitigation uncovered:
- Code mitigation involves rolling back to an earlier version of the software
- Data mitigation involves manually restoring, cleaning up, or deleting data in a file, table, etc.
- Environment mitigation involves killing and restarting processes, migrating workloads, adding fail-over resources, etc..
When mitigating, environment mitigations are the most common.
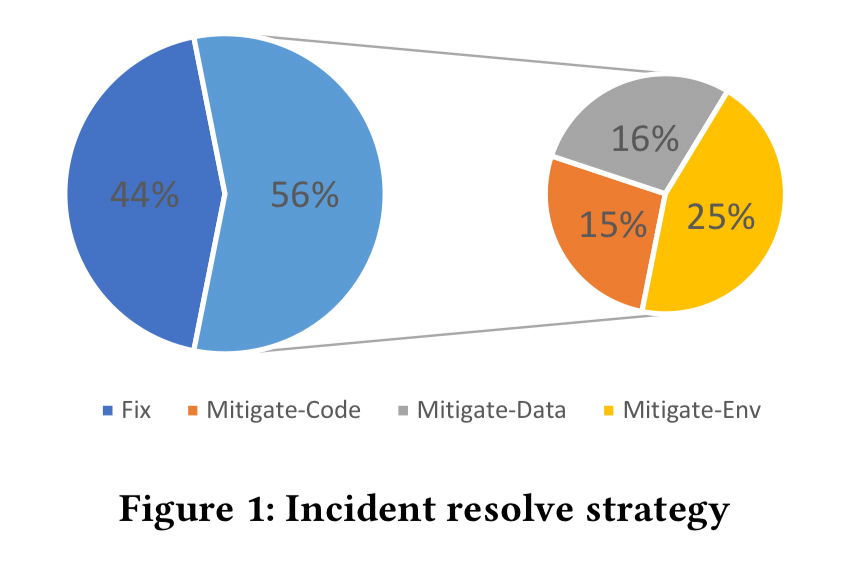
Although the kind of mitigate employed does vary based on root cause:
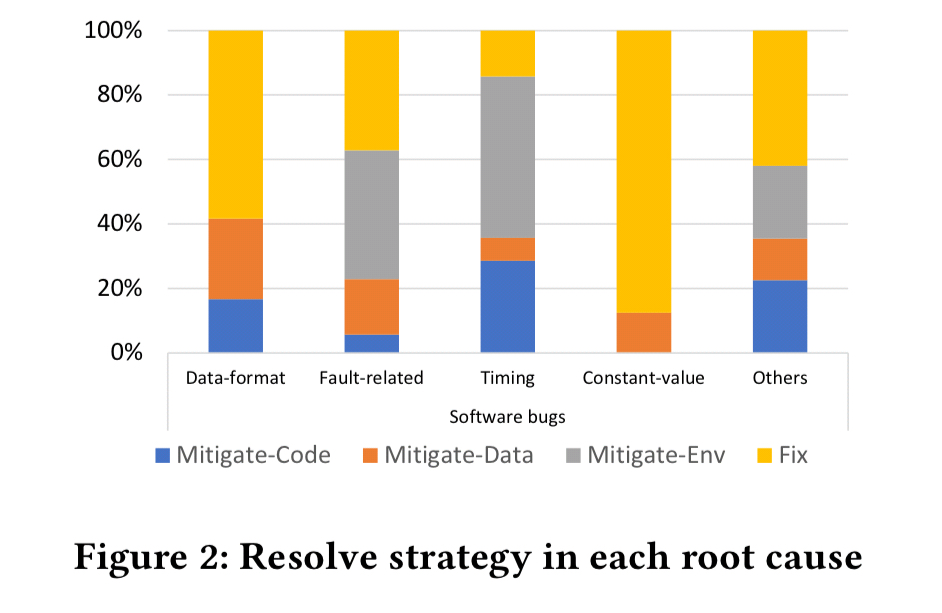
Much recent work looked at how to automatically generate new patches. In comparison, automatically generating mitigation steps has not been well studied and is worth more attention in the future.

“I’d expect this class of bugs to also surface in microservices systems. Does that match your experience?”
yes, very much exactly so :)