Noria: dynamic, partially-stateful data-flow for high-performance web applications Gjengset, Schwarzkopf et al., OSDI’18
I have way more margin notes for this paper than I typically do, and that’s a reflection of my struggle to figure out what kind of thing we’re dealing with here. Noria doesn’t want to fit neatly into any existing box!
We’ve seen streaming data-flow engines that maintain state and offer SQL interfaces and even transactions (e.g. Apache Flink, and data Artisan’s Streaming Ledger for Flink). The primary model here is data-flow, and SQL is bolted on as an interface to the state. The title of this paper sets me off thinking along those lines, but from the end user perspective, Noria looks and feels more like a database. The SQL interface is primary, not ancillary, and it maintains relational data in base tables (using RocksDB as the storage engine). Noria makes intelligent use of data-flow beneath the SQL interface (i.e., dataflow is not exposed as an end-user programming model) in order to maintain a set of (semi-)materialized views. Noria itself figures out the most efficient data-flows to maintain those views, and how to update the data-flow graphs in the face of schema / query set changes.
The primary use case Noria is designed for is read-heavy web applications with high performance (low latency) requirements. Such applications today normally include some kind of caching layer (e.g., memcached, Redis) to accelerate read performance and lighten database load. A lot of application developer effort can go into maintaining these caches and also denormalised and computed state in the database.

In general, developers must choose between convenient, but slow, ‘natural’ relational queries (e.g., with inline aggregations), and increased performance at the cost of application and deployment complexity (e.g. due to caching).
Noria simplifies application development by keeping data in base tables (roughly, the core persistent data) and maintaining derived views (roughly, the data an application might choose to cache). Any computed information derived from the base tables is kept out of those tables. Programmers don’t need to worry about explicit cache management/invalidation, computing and storing derived values, and keeping those consistent. Noria does all this for them.
At its core, Noria runs a continuous, but dynamically changing, dataflow computation that combines the persistent store, the cache, and elements of application logic. Each write to Noria streams through a joint data-flow graph for the current queries and incrementally updates the cached, eventually-consistent internal state and query results.
(Which is also reminiscent of CQRS, but again, the pattern here is used inside the datastore).
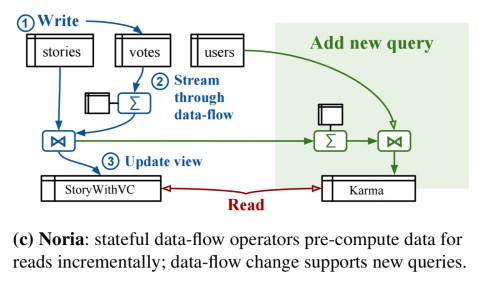
It’s not enough for Noria to maintain just some recent window of state, it needs to store all the persistent state. So state explosion is a potential problem. That’s where the ‘partially-stateful data-flow’ part from the paper title comes in, as Noria has a mechanism for retaining only a subset of records in memory and re-computing any missing values from the upstream operators (and ultimately, base tables) on demand.
The current prototype has some limitations, but it’s also showing a whole lot of promise:
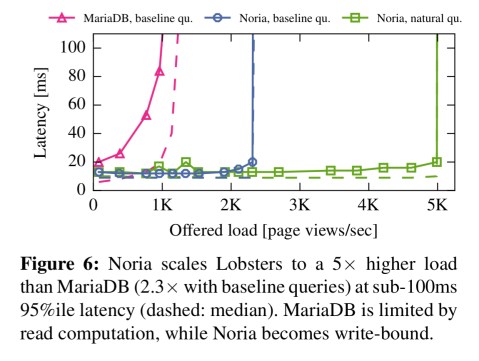
When serving the Lobsters web application on a single Amazon EC2 VM, our prototype outperforms the default MySQL-based backend by 5x while simultaneously simplifying the application. For a representative query, our prototype outperforms the widely-used MySQL/memcached stack and the materialized views of a commercial database by 2-10x. It also scales the query to millions of writes and tens of millions of reads per seconds on a cluster of EC2 VMS, outperforming a state-of-the-art data-flow system, differential dataflow.
The end-user perspective
A Noria program looks like SQL DDL and includes definitions of base tables, internal views used as shorthands in other expressions, and external views which the application can later query. Data is retrieved via parameterised SQL queries. Data in base tables can be updated with SQL insertions, updates, and deletes. Noria applies these changes to the appropriate base tables and updates dependent views.

Noria also implements the MySQL binary protocol, so existing applications using prepared statements against a MySQL database can work directly on top of Noria with no changes required.
The consistency model is eventual with a guarantee that if writes quiesce, all external views eventually hold results that are the same as if the queries had been executed directly against the base table data. “Many web applications fit this model: they accept the eventual consistency imposed by caches that make common-case reads fast.”
One very nice feature of Noria is that it accepts the fact that application queries and schema evolve over time. Noria plans the changes needed to the data-flow graph to support the changes and transitions the application with no downtime.
Porting a MySQL-based application to Noria typically proceeds in three steps:
- Import existing data into Noria from a database dump, and point the application at the Noria MySQL adapter. You should see performance improvements for read queries, especially those that are frequently used.
- Create views for computations that the MySQL application currently manually materialises.
- Incrementally rewrite the application to rely on these natural views, updating the write path so that the application itself no longer manually updates views and caches.
During the third phase application performance should steadily improve while the code simplifies at the same time.
Data-flows in Noria
Noria creates a directed acyclic data-flow graph of relational operators with base tables at the roots and external views at the leaves.
When an application write arrives, Noria applies it to a durable base table and injects it into the data-flow as an update. Operators process the update and emit derived updates to their children; eventually updates reach and modify the external views. Updates are deltas that can add to, modify, and remove from downstream state.
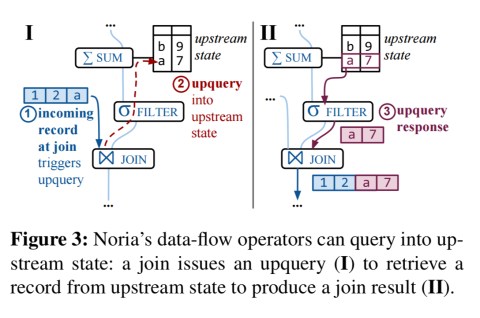
Joins are implemented using upqueries: requests for matching records from stateful ancestors.
Consistency
To provide its eventual consistency guarantees Noria requires that:
- operators are deterministic functions over their own state and the inputs from their ancestors;
- there are no races between updates and upqueries;
- updates on the same data-flow path are not reordered; and
- races between related updates that arrive independently at multi-ancestor operators via different data-flow paths are resolved. Noria addresses this by requiring such operators to be commutative. “The standard relational operators Noria supports have this property.“
With respect to ordering, each operator totally orders all updates and upquery requests it receives for an entry, and the downstream dataflow ensures that all updates and upquery responses from the entry are processed by all consumers in that order.
Upqueries require special care since upquery responses don’t commute with each other or with previous updates. Noria handles this by ensuring that no updates are in flight between the upstream stateful operator and the join when a join upquery occurs: each join upquery is scoped to an operator chain processed by a single thread. (Updates on other chains can be processed in parallel).
State
The partially-stateful data-flow model lets operators maintain only a subset of their state. This concept of partial materialization is well-known for materialized views in databases, but novel to data-flow systems. Partial state reduces memory use, allows eviction of rarely-used state, and relieves operators from maintaining state that is never read… Noria makes state partial whenever it can service upqueries using efficient index lookups. If Noria would have to scan the full state of an upstream operator to satisfy upqueries, Noria disables partial state for that operator.
Partial-state operators start out empty and are gradually and lazily populated by upqueries.
Like a cache, entries can be evicted under memory pressure. Eviction notices flow along the update data-flow path, indicating that some state entries will no longer be updated. If it is later required to read from evicted state Noria recomputes it via recursive upqueries (all the way to the base tables if necessary).

For correct handling of joins, once upstream state has been filled in via recursive upqueries, a special join upquery executes within a single operator chain and excludes concurrent updates.
Data-flow transitions
Changes to a Noria program over time (e.g. the set of SQL query expressions) are handled by adapting the data-flow dynamically.
Noria first plans the transition, reusing operators and state of existing expressions where possible. It then incrementally applies these changes to the data-flow, taking care to maintain its correctness invariants. Once both steps complete, the application can use new tables and queries.
See section 5 in the paper for full details.
Evaluation
Noria is 45kloc of Rust and supports both single server and clustered usage. The prototype is evaluated using backend workloads generated from the production Lobsters web application. It is compared against vanilla MySQL (MariaDB), a MySQL/memcached stack, the materialized views of a commercial database, and an idealized cache-only deployment (the latter not offering any persistence, but giving an estimate of the performance when all reads are served from memory).
Here’s how Noria compares to MariaDB on Lobsters, where “Noria achieves both good performance and natural, robust queries.”
Noria’s space overhead is around 3x the base table size for Lobsters.
The rest of the comparisons are done with single server setups and a subset of Lobsters. For read-heavy workloads Noria outperforms all other systems except for the pure memcached at 100-200K requests/sec. With a mixed read-write workload Noria again beats everything except for the (unrealistic) pure memcached solution.

See section 8.2 for an interesting comparison of Noria with DBToaster as well.
Compared to a Differential Dataflow implementation based on Naiad and a 95% read Lobsters subset workload, Noria scales competitively and starts to show advantage from 4 machines onwards.
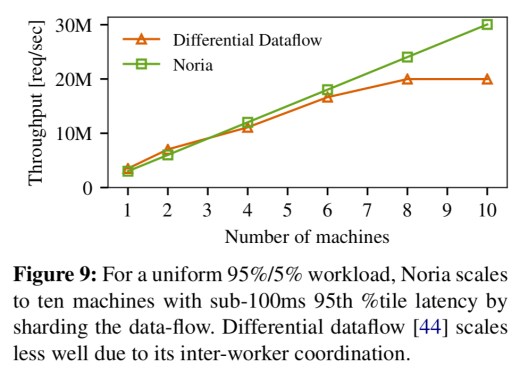
To achieve truly large scale Noria can shard large base tables and operators with large state across machines. “Efficient resharding and partitioning the data-flow to minimize network transfers are important future work for Noria…”
So let’s return to the question we started with, what kind of thing is Noria? In the authors’ own words:
Noria is a web application backend that delivers high performance while allowing for simplified application logic. Partially-stateful data-flow is essential to achieving this goal: it allows fast reads, restricts Noria’s memory footprint to state that is actually used, and enables live changes to the data-flow.
Noria is available at https://pdos.csail.mit.edu/noria.<

3 thoughts on “Noria: dynamic, partially-stateful data-flow for high-performance web applications”
Comments are closed.