Moment-based quantile sketches for efficient high cardinality aggregation queries Gan et al., VLDB’18
Today we’re temporarily pausing our tour through some of the OSDI’18 papers in order to look at a great sketch-based data structure for quantile queries over high-cardinality aggregates.
That’s a bit of a mouthful so let’s jump straight into an example of the problem at hand. Say you have telemetry data from millions of heterogenous mobile devices running your app. Each device tracks multiple metrics such as request latency and memory usage, and is associated with dimensional metadata (categorical variables) such as application version and hardware model.
In applications such as A/B testing, exploratory data analysis, and operations monitoring, analysts perform aggregation queries to understand how specific user cohorts, device types, and feature flags are behaving.
We want to be able to ask questions like “what’s the 99%-ile latency over the last two weeks for v8.2 of the app?”
SELECT percentile(latency, 99) FROM requests WHERE time > date_sub(curdate(), 2 WEEK) AND app_version = "v8.2"
As well as threshold queries such as “what combinations of app version and hardware platform have a 99th percentile latency exceeding 100ms?”
SELECT app_version, hw_model, PERCENTILE(latency, 99) as p99 FROM requests GROUP BY app_version, hw_model HAVING p99 > 100
Instead of starting from raw data every time when answering this type of query, OLAP engines can reduce query time and memory usage by maintaining a data cube of pre-aggregated summaries for each tuple of dimension values. The ultimate query performance then depends on just how quickly we can merge those summaries to compute quantile roll-ups over the requested dimensions.
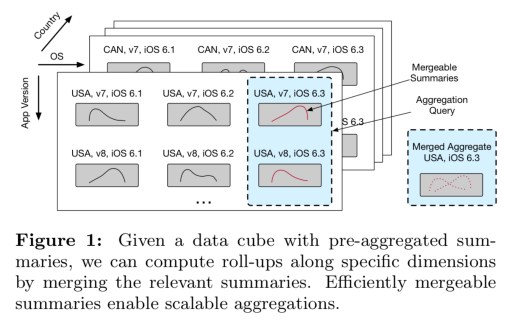
Let’s take a very simple example. Suppose I have two dimensions, letter (with values A and B), and colour (with values red and green), and I have request latency data from log messages including these attributes. Then I will have four summary sketches, one accumulating latency values for (A, red) one for (A, green), one for (B, red) and one for (B, green).
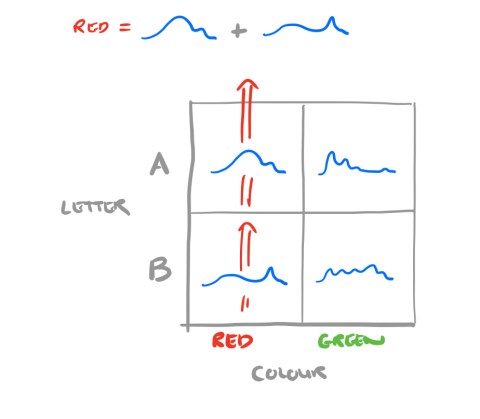
If a query wants to know the P99 latency for ‘red’ requests, we can add together the (A, red) and (B, red) sketches to get a complete sketch for red.
In this paper, we enable interactive quantile queries over high-cardinality aggregates by introducing a compact and efficiently mergeable quantile sketch and associated quantile estimation routines.
The data structure than makes all this possible is called a moments sketch (named after the method of moments statistical technique). It’s easy to construct, but a bit more difficult to interpret. It’s worth the effort though, as the evaluation shows:
- The moments sketch supports 15-50x faster query times that comparably accurate summaries on quantile aggregations
- The moments sketch gives good accuracy across a range of real-world datasets using less than 200 bytes of storage
- Integration of the moments sketch in Druid provides 7x faster quantile queries than the default quantile summary in Druid workloads.
There’s a Java implementation available at https://github.com/stanford-futuredata/msketch.
Mergeable quantile summaries
Intuitively, a summary is mergeable if there is no accuracy cost to combining pre-computed summaries compared with constructing a summary on the raw data. Thus, mergeable summaries are algebraic aggregate functions in the data cube literature… Mergeable summaries can be incorporated naturally into a variety of distributed systems [e.g. MapReduce].
The moments sketch mergeable summary is based on the method of moments, “a well established statistical technique for estimating the parameters of probability distributions.” Given a sketch recording moments (we’ll look at those in just a minute), the method of moments helps us to construct a distribution with moments matching those in the sketch. There could be many such distributions meeting those criteria. The principle of maximum entropy is used to select the distribution that encodes the least additional information about the data beyond that captured by the given moment constraints (i.e., just enough to fit the facts, and no more).
Maintaining and merging moments sketches
A moments sketch is a set of floating point values containing:
- the minimum value seen so far
- the maximum value seen so far
- the count of the number of values seen so far
- k moments, and
- k log moments

The k sample moments are given by 


For long-tailed datasets where values can vary over several orders of magnitude we can recover better quantile estimates using log-moments.
In general, when updating a moments sketch in a streaming manner or when maintaining multiple moments sketches in a distributed setting, we cannot know a priori whether standard moments or log moments are more appropriate for the given data set. Therefore, our default approach is to store both sets of moments up to the same order k.
The functions to initialise an empty sketch, accumulate a new point-wise addition, or merge two sketches together are very straightforward given these definitions (the figure below complicates things by showing how to accumulate the scaled moments rather than the unscaled versions).

Estimating quantiles given a moment sketch
So it’s easy to maintain the sketch data structures. But the small matter of how to use these data structures to estimate quantiles remains.
… given a moments sketch with minimum
and maximum
, we solve for a pdf
supported on
with moments equal to the values in the moments sketch… We can then report the quantiles of
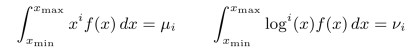
The differential Shannon entropy H is used to measure the degree of uniformativeness in a distribution ( ![H[f] = - \int_{x} f(x) \log f(x) dx](https://s0.wp.com/latex.php?latex=H%5Bf%5D+%3D+-+%5Cint_%7Bx%7D+f%28x%29+%5Clog+f%28x%29+dx&bg=eeeeee&fg=666666&s=0&c=20201002)
With a little mathematical juggling (§4.2), we can solve the problem of finding the maximum entropy distribution 
You also need to be aware of bumping into the limits of floating point stability. In practice data centered at 0 have stable higher moments up to k=16. With double precision floating point moments and data in a range [c-1, c+1] you can get numerically useful values with moments up to
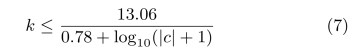
Overall, these optimisations bring quantile estimation overhead down to 1ms or less, sufficient for interactive latencies on single quantile queries.
Optimisations for threshold queries
For threshold queries (e.g. P99 greater than 100ms) we can do a further optimisation.
Instead of computing the quantile on each sub-group directly, we compute a sequence of progressively more precise bounds in a cascade and only use more expensive estimators when necessary… Given the statistics in a moments sketch, we apply a variety of classical inequalities to derive bounds on the quantiles. These provides worst-case error guarantees for quantile estimates, and enable faster query processing for threshold queries over multiple groups.
Two kinds of bounds are used, one based on Markov’s inequality, and a slightly more expensive to compute bound called the RTTBound (see §5.1). The bounds are used to see if the threshold predicate can be resolved immediately, if not then we solve for the maximum entropy distribution as previously. It all comes together like this:

Evaluation
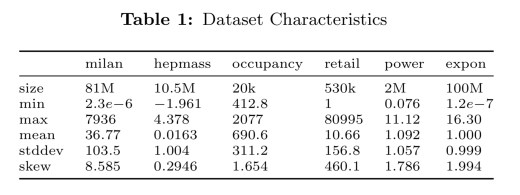
The moment sketch (M-Sketch) is evaluated against existing quantile summaries and also integrated into Druid and MacroBase. Six real-valued datasets are used, with statistics as captured in the following table:
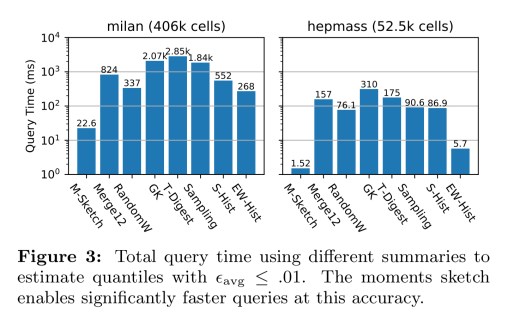
Microbenchmarks evaluating query times and accuracy show that M-Sketch offers best-in-class query times for the same accuracy.
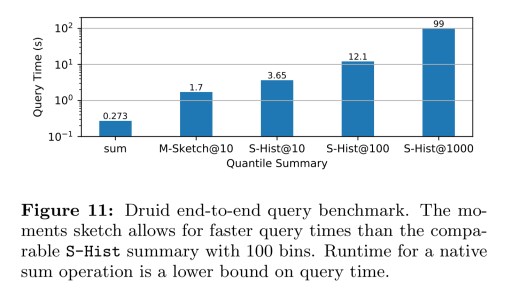
The moments sketch gets its advantage from fast merge times, which means the more merges required (the bigger the datacube) the better its relative performance. With 

When integrated into Druid and compared to Druid’s default S-Hist summary using the Milan dataset with 26 million entries the moments sketch gives a 7x lower query time (note the log scale).
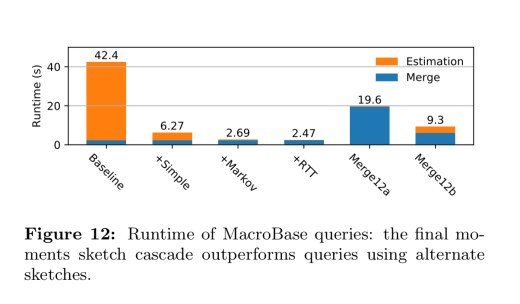
The following figure shows the impact of the bounds checking optimisation for threshold queries. Concentrating on the first four bars we see (a) a baseline calculating quantile sketches directly, (b) the moments sketch with no bounds optimisations, (c) adding in the Markov bounds test, and (d) using both the Markov bound and RTTBound tests.
Low merge overhead allows the moments sketch to outperform comparably accurate existing summaries when queries aggregate more than 10 thousand summaries…. the use of numeric optimizations and cascades keep query times at interactive latencies.

One thought on “Moment-based quantile sketches for efficient high cardinality aggregation queries”
Comments are closed.