Dynamic control flow in large-scale machine learning Yu et al., EuroSys’18
(If you don’t have ACM Digital Library access, the paper can be accessed either by following the link above directly from The Morning Paper blog site).
In 2016 the Google Brain team published a paper giving an overview of TensorFlow, “TensorFlow: a system for large-scale machine learning.” This paper is a follow-up, taking a much deeper look at how TensorFlow supports dynamic control flow, including extending automatic differentiation to control flow constructs.
Embedding control flow within the dataflow graph
With a wide range of machine learning models in use, and rapid exploration of new techniques, a machine learning system needs to be expressive and flexible to support both research and production use cases. Given the ever larger models and training sets, a machine learning system also needs to be scalable. These means both using individual devices efficiently (anything from phones to custom ASCIs in datacenters), and also supporting parallel execution over multiple devices.
Both the building blocks of machine learning and the architectures built up using these blocks have been changing rapidly. This pace appears likely to continue. Therefore, rather than defining RNNs, MoEs (mixture of experts), and other features as primitives of a programming model, it is attractive to be able to implement them in terms of general control-flow constructs such as conditionals and loops. Thus, we advocated that machine learning systems should provide general facilities for dynamic control flow, and we address the challenge of making them work efficiently in heterogeneous distributed systems consisting of CPUs, GPUs, and TPUs.
The demand for dynamic control flow has been rising over the last few years. Examples include while-loops used within RNNs, gating functions in mixture-of-experts models, and sampling loops within reinforcement learning.
Instead of relying on programming languages outside of the graph, TensorFlow embeds control-flow as operations inside the dataflow graph. This makes whole program optimisation easier and keeps the whole computation inside the runtime system, avoiding the need to communicate with the client (which can be costly in some deployment scenarios). The implementation supports both parallelism and asynchrony, so e.g. control-flow logic on CPUs and compute kernels on GPUs can overlap.
The main control flow operators are a conditional cond(pred, true_fn, false_fn), and a while loop while_loop(pred, body, inits). There are other higher order constructs built on top of these (for example, map_fn, foldl, foldr, and scan).
We analyzed more than 11.7 million (!) unique graphs for machine learning jobs at Google over the past year, and found that approximately 65% contain some kind of conditional computation, and approximately 5% contain one or more loops.
Control flow in TensorFlow
The basic design of TensorFlow is as follows: a central coordinator maps nodes in the dataflow graph to the given set of devices, and then partitions the graph into a set of subgraphs, one per node. Where the partitioning causes an edge to span two devices the edge is replaced with pair of send and receive communication operations using a shared rendezvous key.
When dynamic control flow is added into the mix, we can no assume that each operation in the graph is executed exactly once, and so unique names and rendezvous keys are generated dynamically. Conditional branches and loops may be arbitrarily partitioned across devices.
We rely on a small set of flexible, expressive primitives that serve as a compilation target for high-level control-flow constructs within a dataflow model of computation.
Those primitives are switch, merge, enter, exit, and nextIteration. Every execution of an operation takes place within an ‘frame’. Without control flow, each operation is executed exactly once. With control flow, each operation executes at most once per frame. The following figure shows how a while-loop can be translated into these primitives to give you the idea:
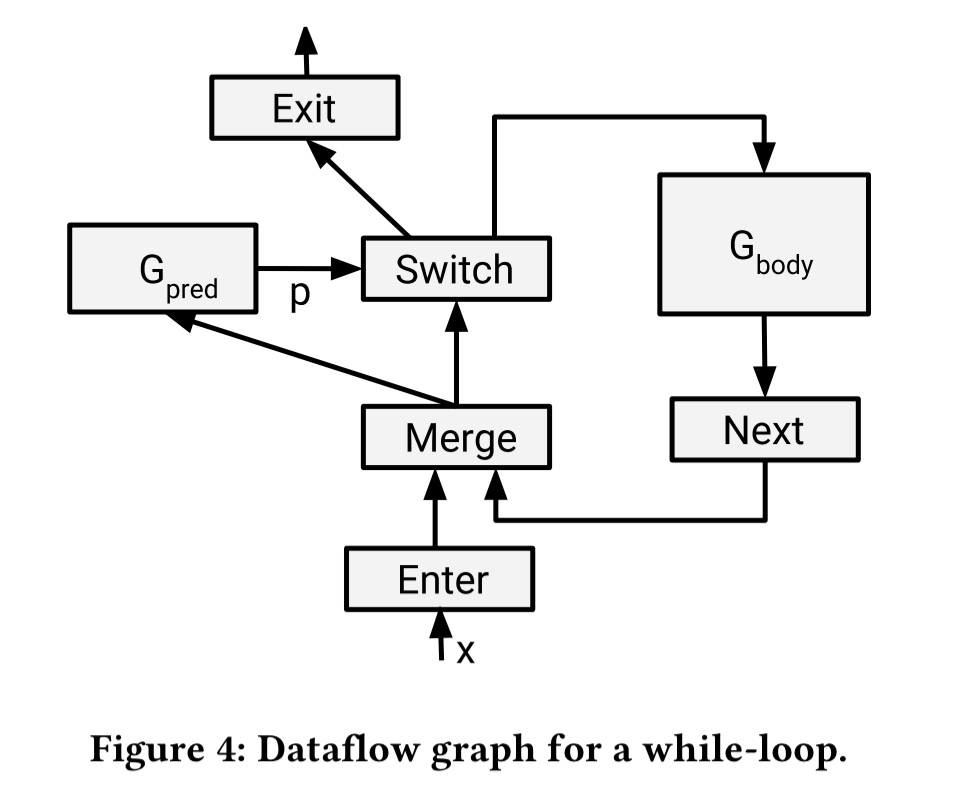
Tensors inside executors are represented by tuples (value, isDead, tag), where isDead is a boolean indicating whether the tensor is on an untaken branch of a switch, and the tag identifies a frame. The evaluation rules are shown in the following figure:

The rules allow multiple loop iterations to run in parallel, but left unchecked this will use a lot of memory. Empirically, a limit of 32 parallel executions at a time seems to work well.
When the subgraph of a conditional branch or loop body is partitioned across devices partitions are allowed to make progress independently. (There is no synchronisation after each loop iteration, and no central coordinator). The receive operation of a conditional is always ready and can be started unconditionally. If the corresponding send is never executed though (the branch is not chosen) that means we’d be blocking forever waiting for input. Therefore the system propagates an isDead signal across devices from send to receive to indicate the branch has not been taken. This propagation may continue across multiple devices as needed.
For distributed execution of loops each partition needs to know whether to proceed or exit at each iteration. To handle this the graph is rewritten using simple control-loop state machines. Here’s an example partitioning a simple while-loop. The dotted lines represent the control edges.
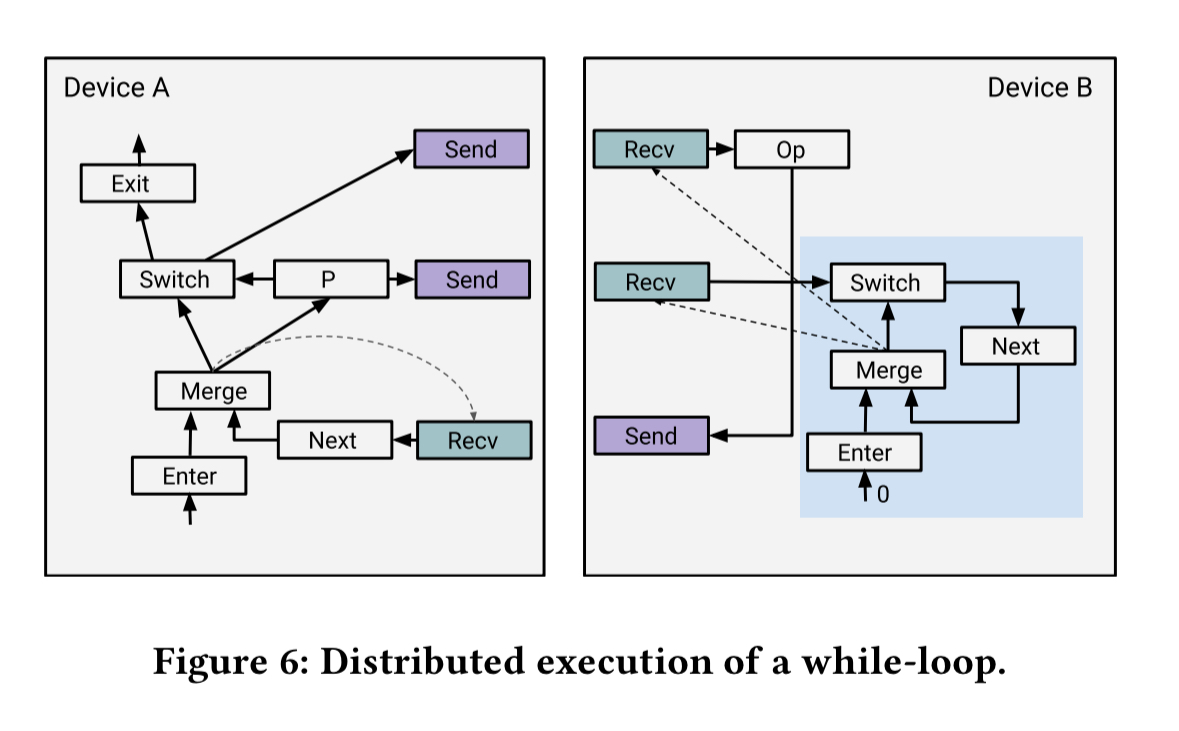
The overhead for the distributed execution of a loop is that every participating device needs to receive a boolean at each iteration from the device that produces the loop predicate. However, the communication is asynchronous and computation of the loop predicate can often run ahead of the rest of the computation. Given typical neural network models, this overhead is minimal and largely hidden.
Differentiation
TensorFlow supports automatic differentiation. That is, given a graph representing a neural network, it will generate efficient code for the corresponding distributed gradient computations. In the base case this is back-propagation using the chain rule, and TensorFlow includes a library of gradient functions corresponding to most of its primitive operations.
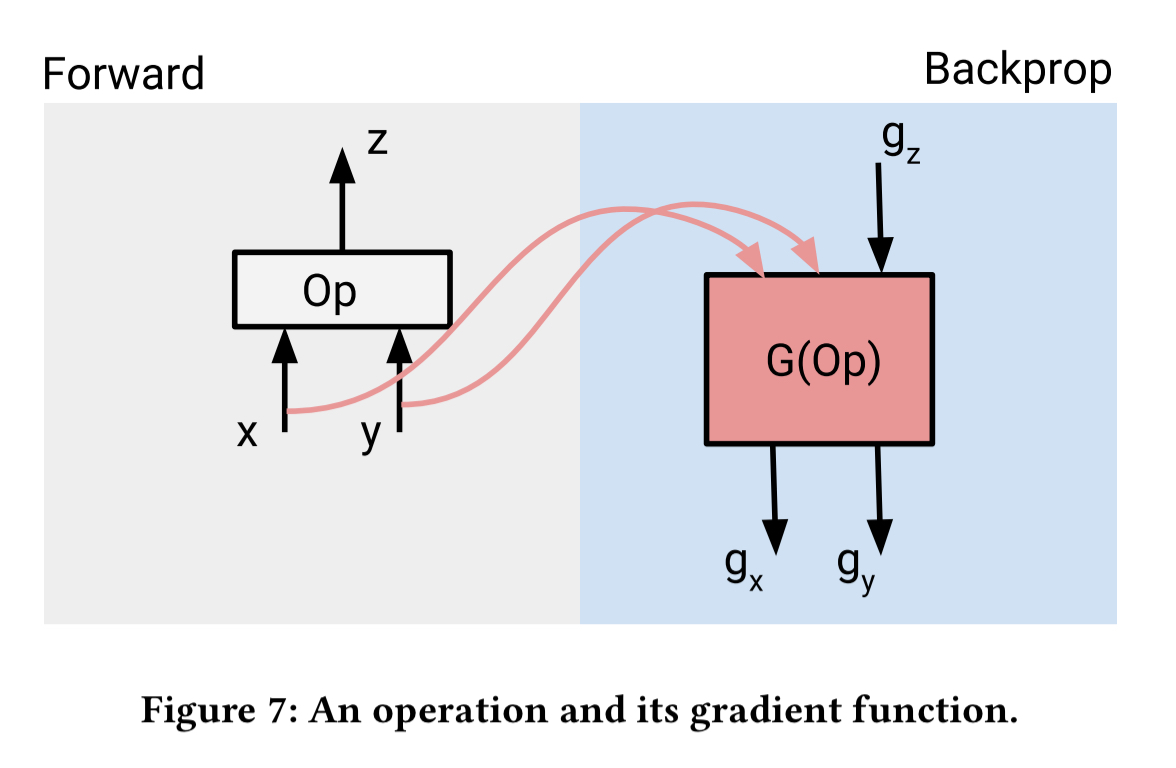
Tensors used in the gradient function (e.g., x and y in the above example) are kept until the gradient computation is performed. That can consume a lot of memory in deep neural networks, and it gets worse when we add loops. To support back-propagation through control flow constructs:
Each operation in the graph is associated with a ‘control flow context’ that identifies the innermost control-flow construct of which that operation is a member. When the backpropagation traversal first encounters a new control-flow content, it generates a corresponding control-flow construct in the gradient graph.
For a conditional tf.cond(pred, true_fn, false_fn) with output gradients g_z this is simply tf.cond(pred, true_fn_grad(g_z), false_fn_grad(g_z)). For while loops:
- The gradient of a while loop is another loop that executes the gradient of the loop body for the same number of iterations as the forward loop, but in reverse.
- The gradient of each differentiable loop variable becomes a loop variable in the gradient loop.
- The gradient of each differentiable tensor that is constant in the loop is the sum of the gradients for that tensor at each iteration.
The overall performance is heavily dependent on how intermediate values are treated. To avoid recomputing these values they are pushed onto a stack during loop execution, and popped during gradient computation. Stack operations are asynchronous so they can run in parallel with actual computation.
Memory management
Especially on GPUs, where memory is more limited, memory management is crucial. When tensors are pushed onto stacks they are moved from GPU to CPU memory. Separate GPU streams are used for compute and I/O operations to improve their overlap. Each stream is a sequence of sequentially executed GPU kernels. A combination of TensorFlow control edges and GPU hardware events are used to synchronise dependent operations executed on different streams.
Future directions
Dynamic control flow is an important part of bigger trends that we have begun to see in machine learning systems. Control-flow constructs contributed to the programmability of theses systems, and enlarge the set of models that are practical to train using distributed resources. Going further, we envision that additional programming language facilities will be beneficial. For instance, these may include abstraction mechanisms and support for user-defined data structures. The resulting design and implementation challenges are starting to become clear. New compilers and run-time systems such as XLA (Accelerated Linear Algebra), will undoubtedly play a role.

2 thoughts on “Dynamic control flow in large-scale machine learning”
Comments are closed.