BDS: A centralized near-optimal overlay network for inter-datacenter data replication Zhang et al., EuroSys’18
(If you don’t have ACM Digital Library access, the paper can be accessed either by following the link above directly from The Morning Paper blog site).
This is the story of how inter-datacenter multicast transfers at Baidu were sped-up by a factor of 3-5x. That’s a big deal!
For large-scale online service providers, such as Google, Facebook, and Baidu, an important data communication pattern is inter-DC multicast of bulk data — replicating massive amounts of data (e.g., user logs, web search indexes, photo sharing, blog posts) from one DC to multiple DCs in geo-distributed locations.
To set the scene, the authors study inter-DC traffic at Baidu over a period of seven days. Nearly all inter-DC traffic is multicast (91.1%), highlighting the importance of optimising the multicast use case.
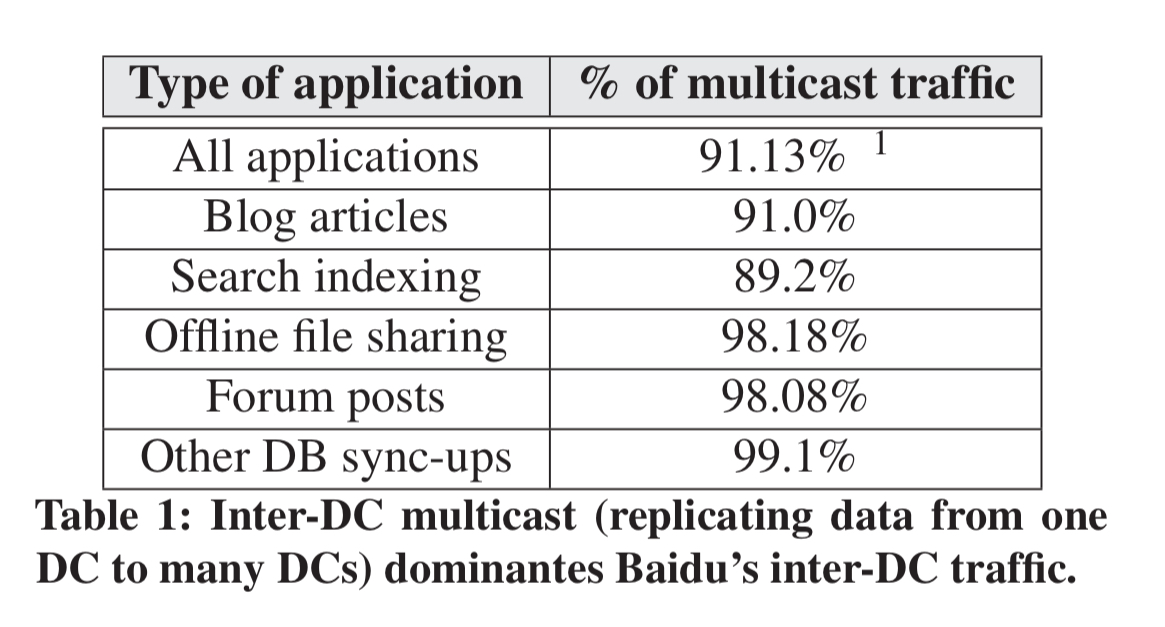
When looking at the individual transfers, there is great diversity in the source and destination DCs. Thus it’s not going to suffice to pre-configure a few select routes: “we need a system to automatically route and schedule any given inter-DC multicast transfers.”
60% of the transferred files are over 1TB in size (and 90% are over 50GB). The total WAN bandwidth per transfer is on the order of several Gb/s, so these transfers last for many tens of seconds. Long enough that any system should be able to adapt to performance variation during a data transfer. It’s also long enough that we can afford a small amount of delay to make routing decisions though.
Problems with the current solution (Gingko)
To meet the need of rapid growth of inter-DC data replication, Baidu has deployed Gingko, an application-level overlay network, a few years ago… Gingko is based on a receiver-driven decentralized overlay multicast protocol, which resembles what was used in other overlay networks (such as CDS and overlay-based live video streaming).
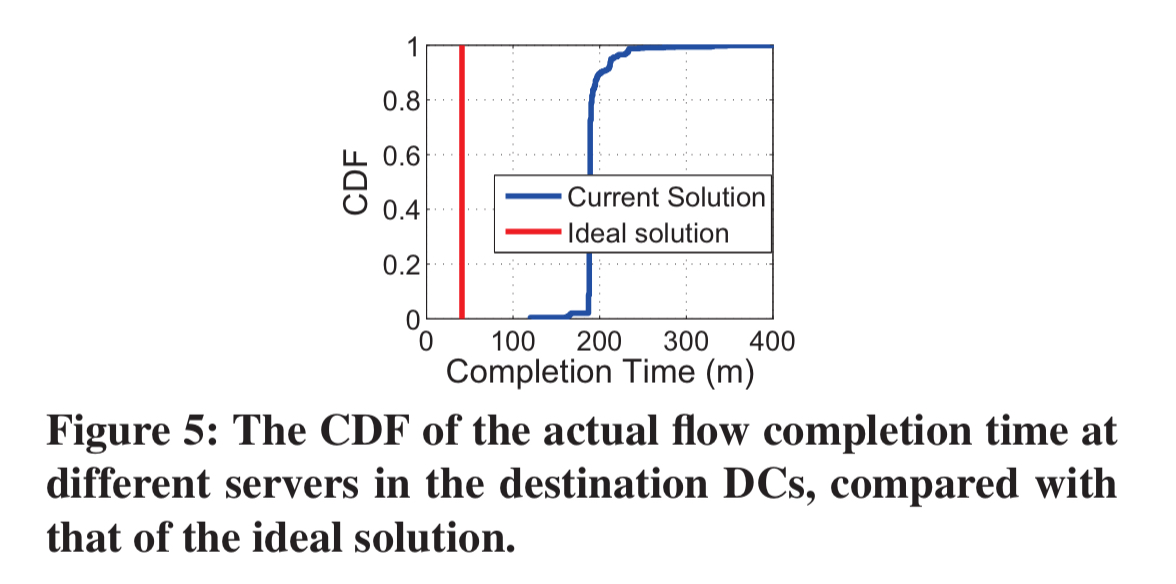
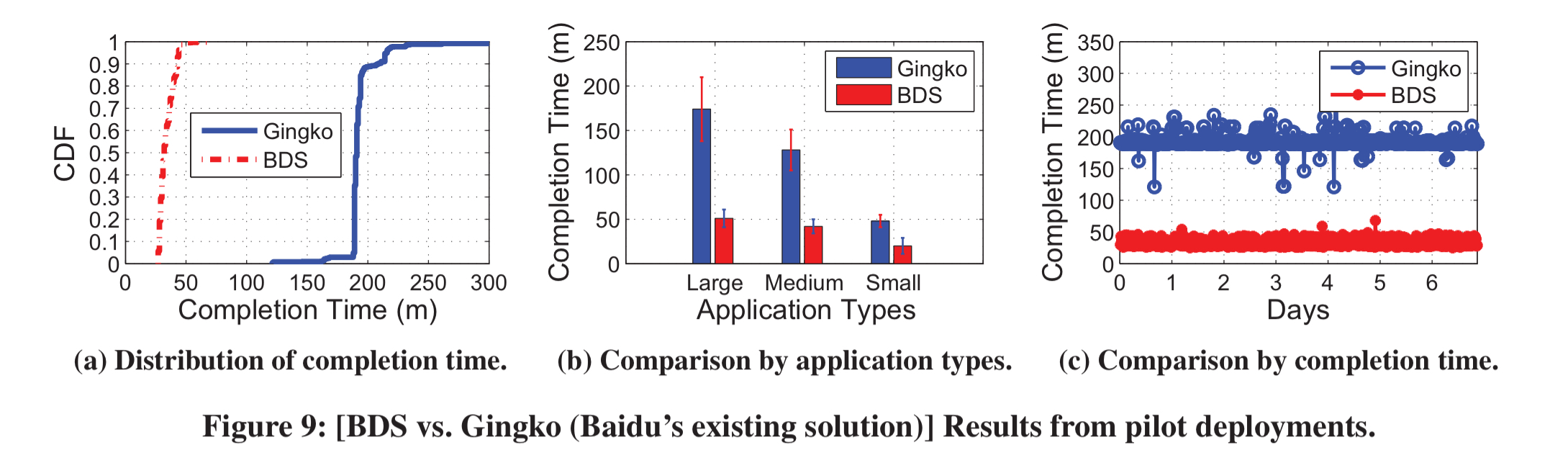
Individual servers operate on limited information, meaning that they make sub-optimal decisions compared to those that could be taken given perfect knowledge. As an example, the authors sent a 30GB file from one DC to two destination DCs (each with 640 servers) in Baidu’s network. The theoretical optimum completion time for this particular transfer should be 41 minutes, but servers in the destination DCs took on average 195 minutes to receive data.
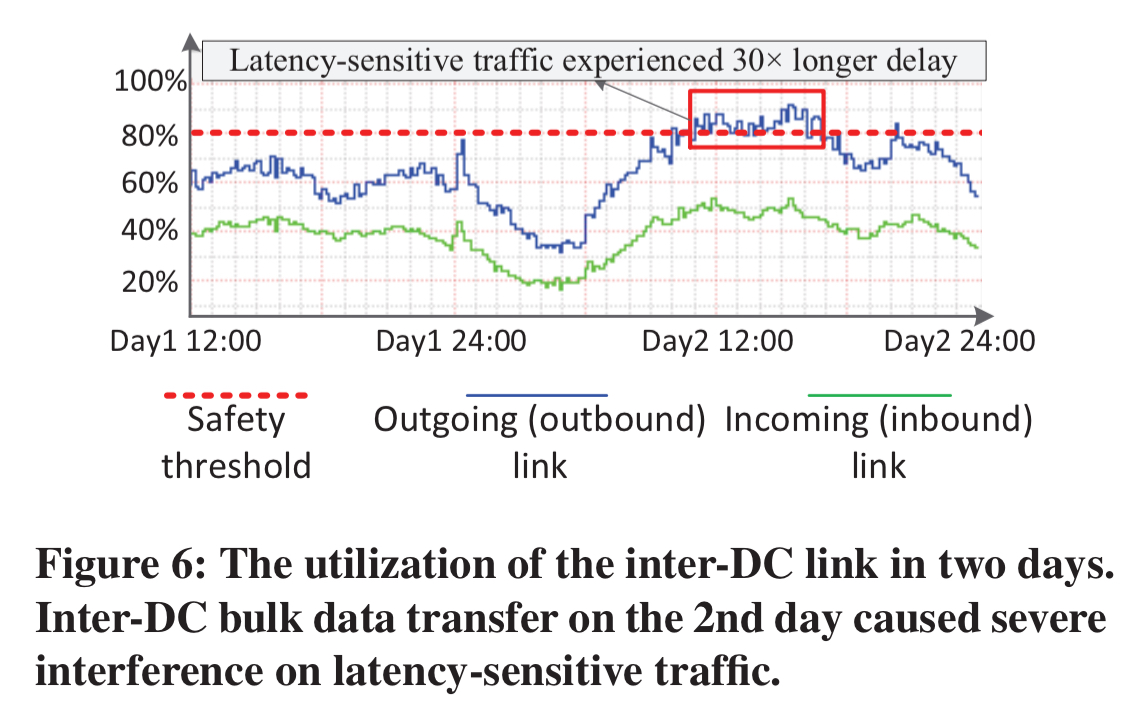
Just as troubling, and despite using standard QoS techniques, bursty arrivals of bulk-data multicast traffic have negative impacts on latency-sensitive traffic. The following trace shows bandwidth utilisation of an inter-DC link over 2 days, during which a 6-hour bulk transfer started at 11am on day two. The latency-sensitive traffic experienced over a 30x delay inflation.
The opportunity: application-level overlays
While lots of effort has gone into improving the performance of the WAN paths between DCs, there is still a lot of potential for improvement by using application-level overlay paths and the capabilities of servers to store-and-forward data.
Consider a 3GB file that we want to send from datacenter A to datacenters B and C, with WAN links of 1GB/s. The file is chopped up into three 1GB blocks. If we use direct replication it’s going to take three seconds to send the file from A to B. We can send the file from A to C in parallel, so the total elapsed time is three seconds.
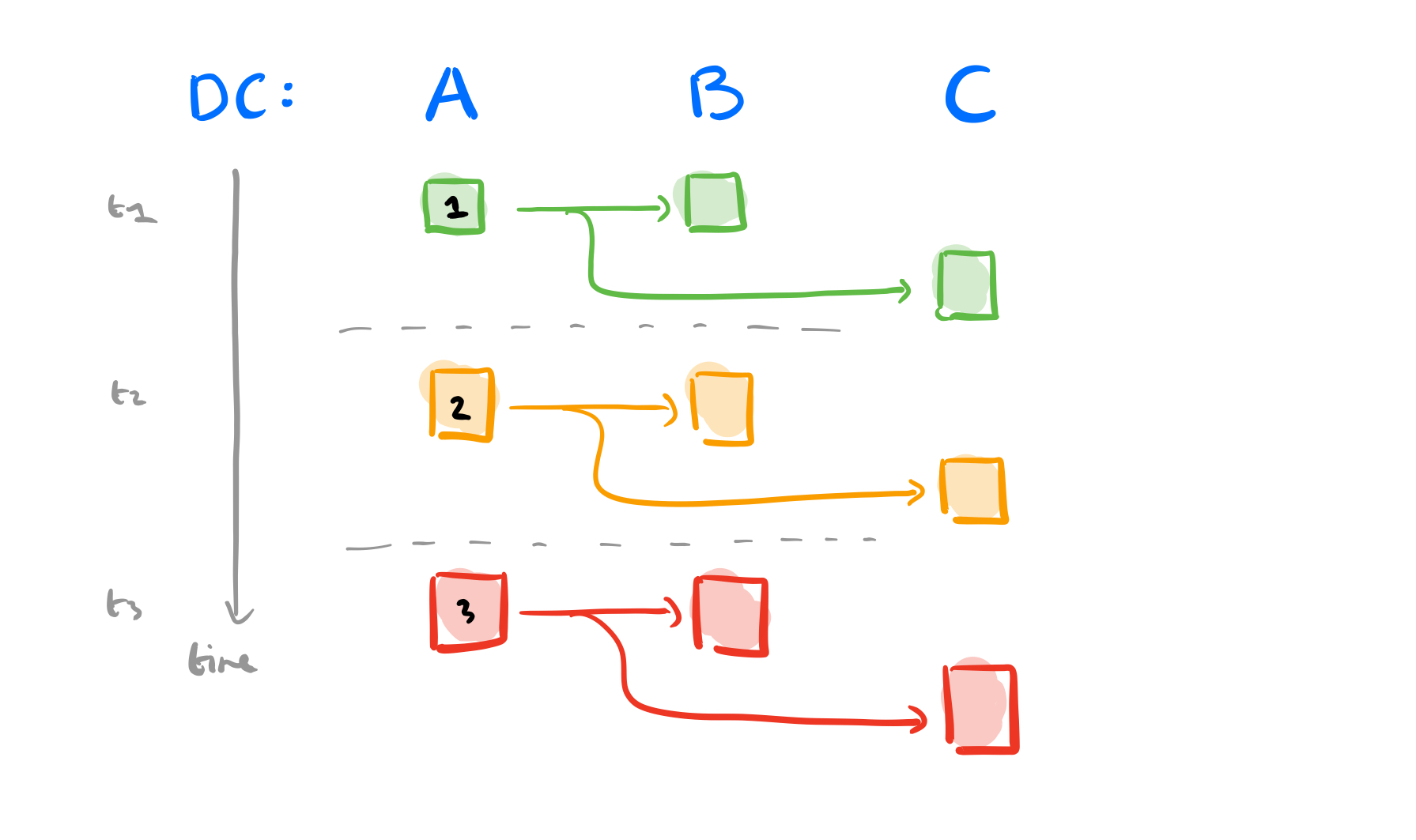
Now let’s introduce some overlay paths. We’ll make use of a server b in B that can store-and-forward traffic for C, and a server c in C that can store-and-forward traffic for B. Thus we have paths A → b → C, and A → c → B. At step one, send block 1 on route A → b → C, and block 2 on route A → c → B. In step two, send block 3 from A to B and C in parallel. At the same time the store-and-forward server in C sends block 1 to B, and the store-and-forward server in B sends block 2 to C. The total elapsed time for the transfer is now 2 seconds.
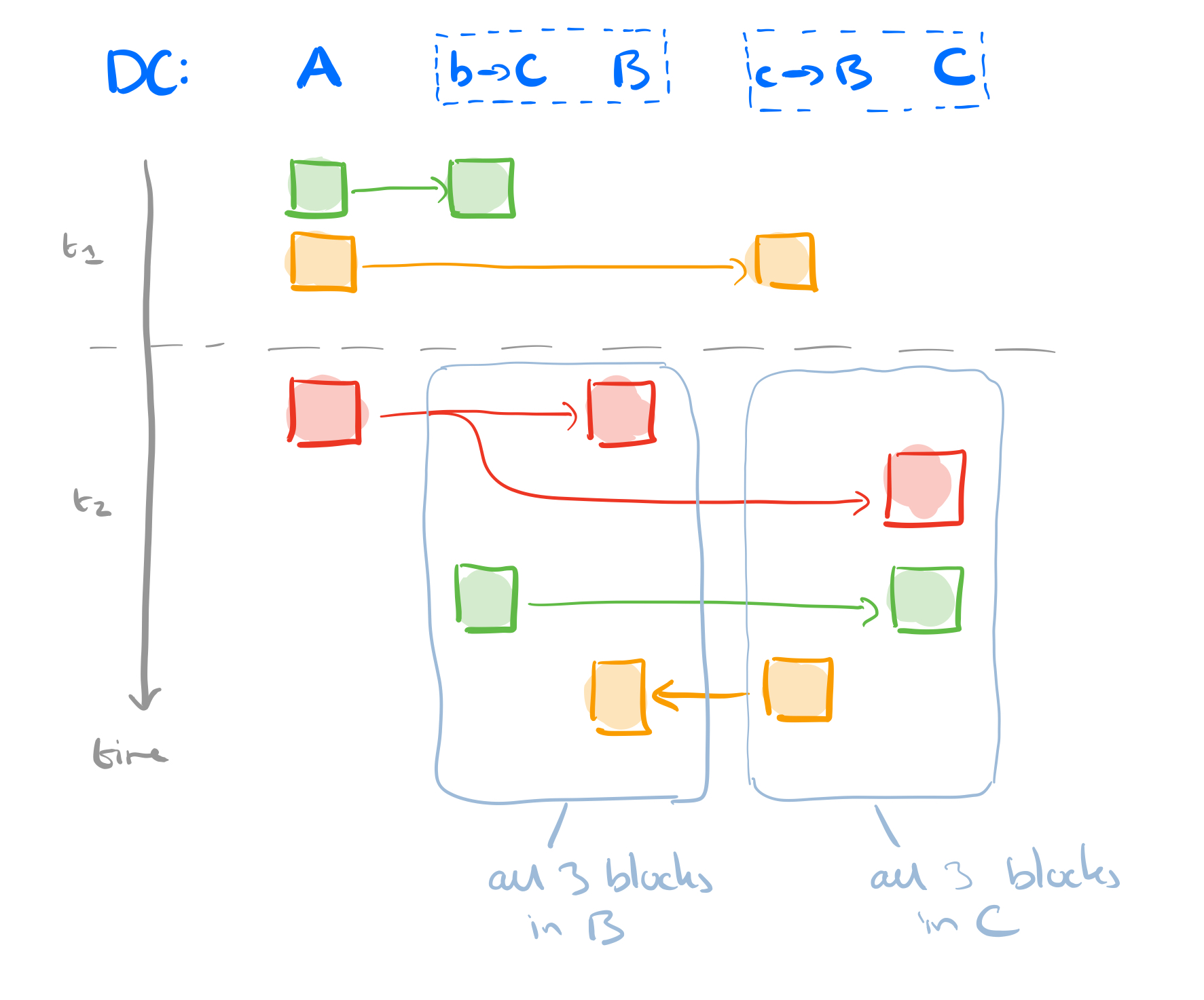
We only realise a time saving of course if the overlays routes aren’t competing with the WAN links for bandwidth. Or more precisely, the overlay paths should be bottleneck disjoint, not sharing common bottleneck links.
This paper presents BDS, an application-level multicast overlay network, which splits data into fine-grained units, and sends them in parallel via bottleneck-disjoint overlay paths.
We can estimate the number of bottleneck disjoint overlay paths available in the wild by observing that if two overlay paths have different end-to-end throughput at the same time, they should be bottleneck-disjoint (AC: assuming that the paths are run at capacity??). An analysis at Baidu looking at traffic from A to C, in conjunction with overlay paths from A → b → C, for all possible values of A, b, and C, more than 95% of pairs were bottleneck disjoint.
An intractable problem?
BDS is a fully centralised near-optimal application-level overlay network. It uses a centralised controller periodically pulling information from all servers, updating overlay routing decisions, and pushing them out to agents running locally on servers. Centralised designs are somewhat out of fashion these days, so here are the four reasons BDS was designed this way:
- There are a huge number of possible inter-DC routing paths, making it difficult for individual servers to explore all possible paths based only on local measurements. With a global view it is possible to significantly improve performance.
- The long transfer times mean that BDS can tolerate a short delay in order to get better routing decisions from a centralised controller.
- Without coordination across overlay servers, it is difficult to avoid hotspots and prevent inter-DC multicast traffic having a negative impact on latency-sensitive traffic. This is simpler to handle with a centralised controller.
- Lower engineering complexity!
… the design of BDS performs a trade-off between incurring a small update delay in return for the near-optimal decisions brought by a centralized system. Thus, the key to striking such a favorable balance is a near-optimal routing algorithm that can update decisions in near realtime. At first glance, this in indeed intractable.
Why intractable? At each step, the algorithm must pick next hops for 10^5 data blocks across 10^4 servers. With fine-grained block partitioning and growth in the number of overlay paths through these servers, the problem grows exponentially. But all is not lost! BDS makes the problem tractable again but breaking it into two parts. First it chooses the set of blocks to be sent (scheduling), and then it makes routing decisions just for those blocks. Each of these problems can be solved efficiently and near optimally.
Scheduling
The key to do the scheduling (pick the subset of blocks) is to make sure that the subsequent data transmission can be done in the most efficient manner. Inspired by the “rarest-first” strategy in BitTorrent that tries to balance block availability, BDS adopts a simple-yet-efficient way of selecting the data blocks: for each cycle , BDS simply picks the subset of blocks with the least amount of duplicates. In other words, BDS generalizes the rarest-first approach by selecting a set of blocks in each cycle, instead of a copy of a single block.
(I had to read that paragraph a few times for it to sink in. If you consider the example we looked at earlier in this post, what the authors are saying is that they prefer to send e.g. blocks 1 and 2 in a given time step – a different block on each path – , rather than sending e.g. just block 1 along both paths)
Routing
The routing step decides the paths for the blocks selected by the scheduler, with a goal of maximising throughput. This is an instance of an integer multi-commodity flow (MCF) algorithm, which is known to be NP-complete. It in turn is made practical by splitting data into tens of thousands of fine-grained data blocks and then grouping those with the same source and destination, enabling efficient solving via linear programming.
Dynamic bandwidth separation
BDS monitors the aggregated bandwidth usage of all latency-sensitive flows on each inter-/intra-DC link and dynamically allocates bandwidth to multicast transfers. It uses 80% link utilisation as a safety threshold.
Evaluation
The key results from the evaluation (a combination of pilot deployment within Baidu, plus trace-driven simulation and microbenchmarking) are as follows:
- BDS completes inter-DC multicast 3-5x faster than Baidu’s existing solutions, as well as other baselines used in industry
- BDS significantly reduces the incidents of interference between bulk-data multicast traffic and latency sensitive traffic
- BDS can scale to the traffic demand of Baidu, tolerate various failure scenarios, and achieve close to optimal flow completion time.
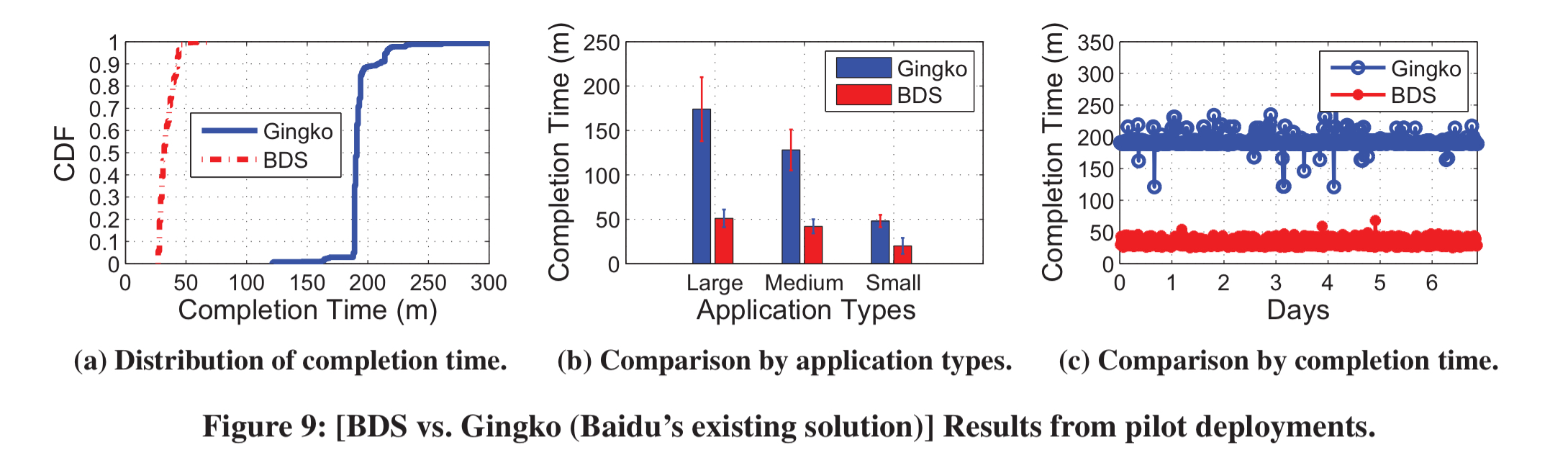
(Enlarge)

{kind=link}
Fascinating and very timely. _Slightly_ side-tracked by the fact that *Ginkgo* is also the name of a test framework for *Golang*. But it is no relation. :-)