Photo-realistic single image super-resolution using a generative adversarial network Ledig et al., arXiv’16
Today’s paper choice also addresses an image-to-image translation problem, but here we’re interested in one specific challenge: super-resolution. In super-resolution we take as input a low resolution image like this:

And produce as output an estimation of a higher-resolution up-scaled version:

For the example above, here’s the ground truth hi-resolution image from which the low-res input was initially generated:

Especially challenging of course, is to recover / generate realistic looking finer texture details when super-resolving at large upscaling factors. (Look at the detail around the hat band and neckline in the above figures for example).
In this paper, we present SRGAN, a generative adversarial network (GAN) for image super-resolution (SR). To our knowledge, it is the first framework capable of inferring photo-realistic natural images for 4x upscaling factors.
In a mean-opinion score test, the scores obtained by SRGAN are closer to those of the original high-resolution images than those obtained by any other state-of-the-art method.
Here’s an example of the fine-detail SRGAN can create, even when upscaling by a factor of 4. Note how close it is to the original.

Your Loss is my GA(i)N
A common optimisation target for SR algorithms is minimisation of the mean-squared error on a pixel-by-pixel basis between the recovered image and the ground truth. Using MSE also has the advantage of maximising the peak signal-to-noise ratio (PSNR), a common measure used to evaluate SR algorithms.
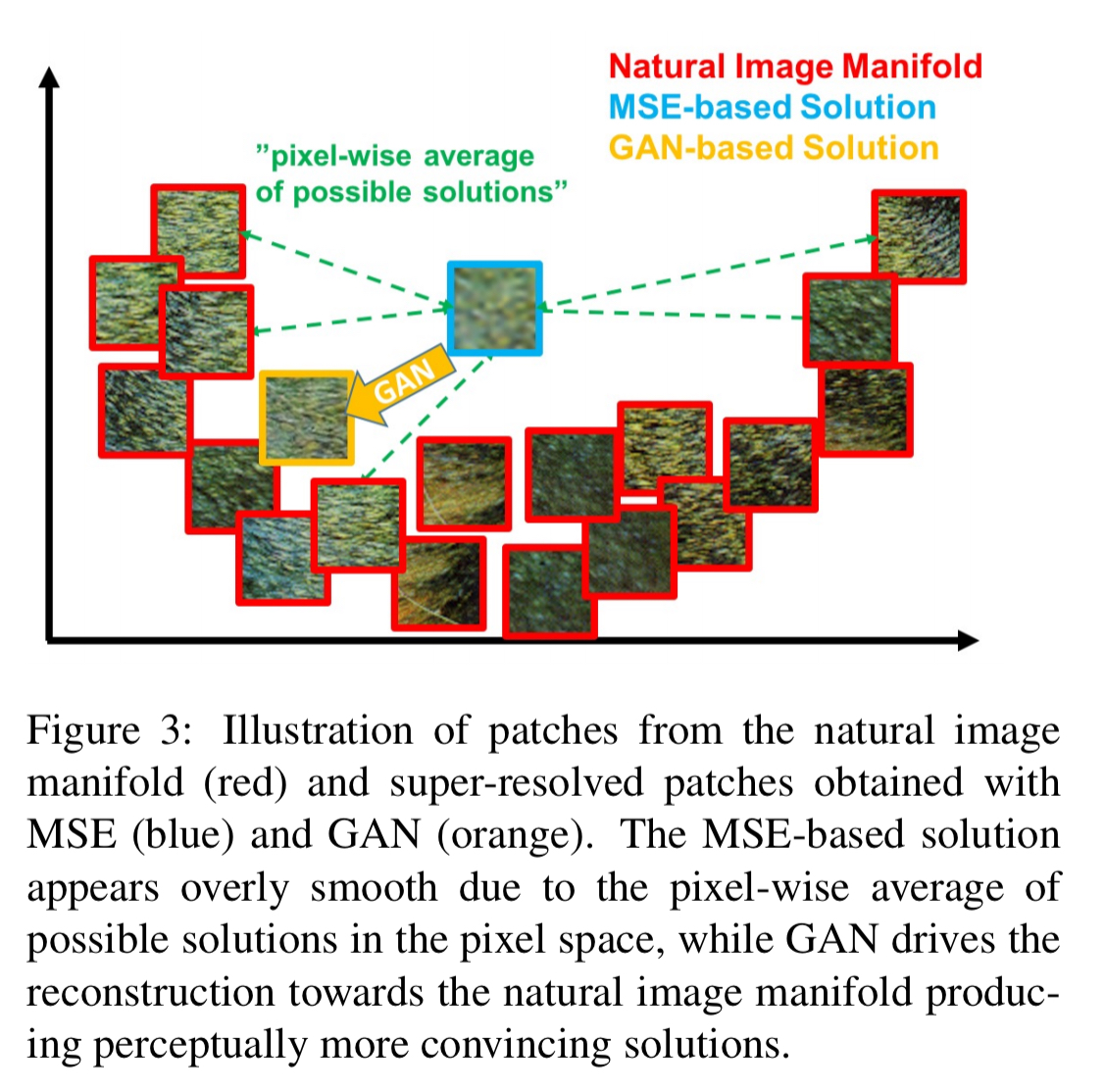
Pixel-wise loss functions such as MSE struggle to handle the uncertainty inherent in recovering lost high-frequency details such as texture; minimizing MSE encourages finding pixel-wise averages of plausible solutions which are typically overly-smooth and thus have poor perceptual quality.
Note in the example below how the blue bordered sample (MSE-based) looks blurred compared to that produced by the GAN-based technique (yellow border) advocated in this paper.
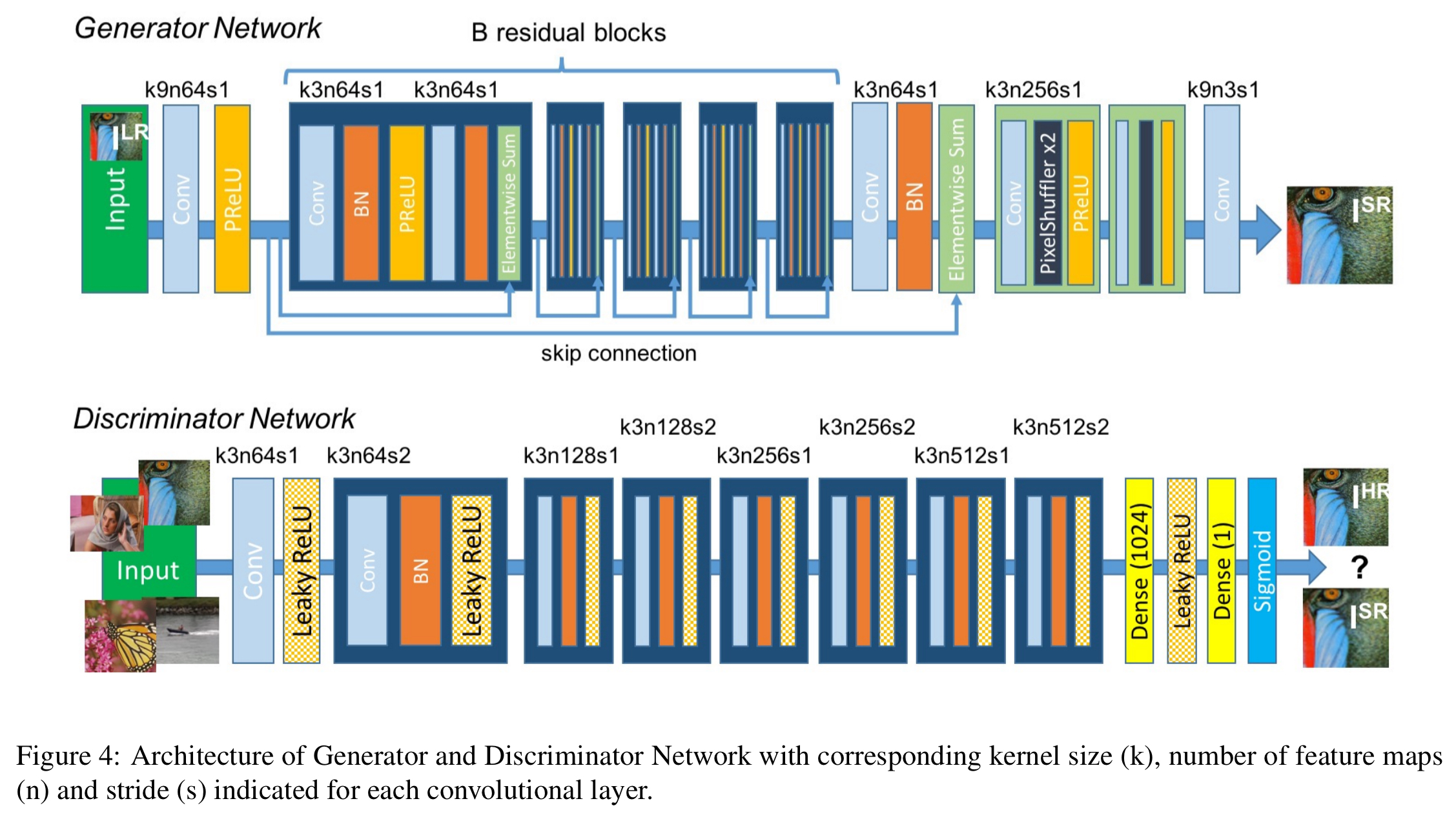
The basic setup has a generator network G trained with a SR-specific loss function, and a discriminator network D trained to distinguish super-resolved images from real images. (See Generative Adversarial Nets for background on how these networks are jointly trained if you’re not familiar with GAN architectures).
With this approach, our generator can learn to create solutions that are highly similar to real images and thus difficult to classify by D. This encourages perceptually superior solutions residing in the subspace, the manifold, of natural images. This is in contrast to SR solutions obtained by minimizing pixel-wise error measurements, such as the MSE.
The generator and discriminator networks are CNNs, using the architecture shown below:
A perceptual loss function
The secret sauce is in the definition of the loss function used by the generator network. It’s a weighted sum of a content loss component, and an adversarial loss component.
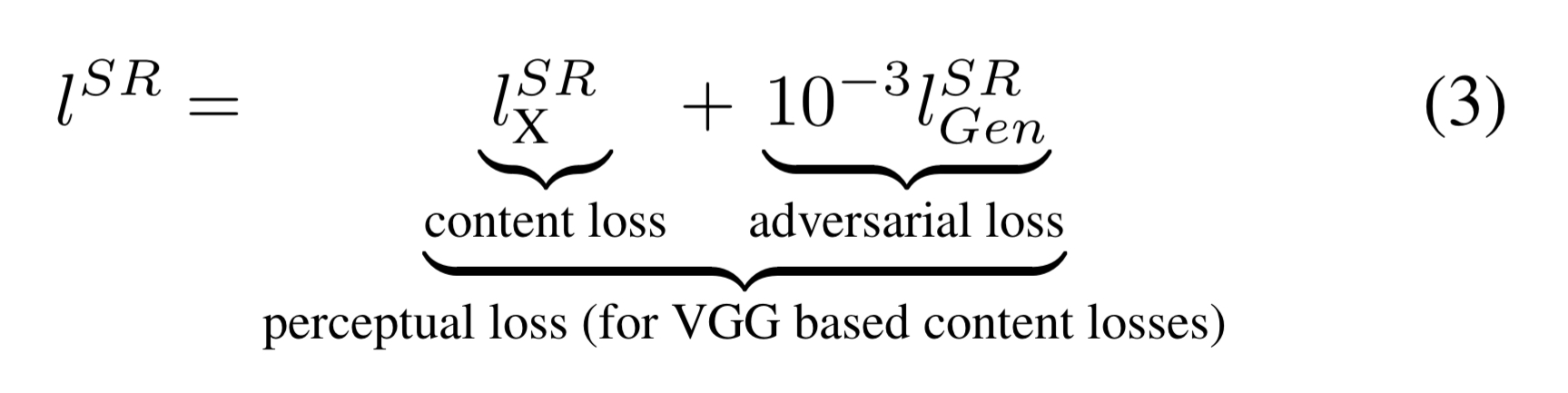
As we’ve seen, it’s traditional to use a pixel-wise MSE loss for content loss. But Gatys et al., Bruna et al. and Johnson et al. all show that it is possible to create loss functions that are closer to perceptual similarity. The trick is to use features extracted from a pre-trained VGG network instead of directly comparing pixels.
We define the VGG loss based on the ReLu activation layers of the pre-trained 19 layer VGG network described in Simonyan and Zisserman… the VGG loss is the euclidean distance between the feature representations of a reconstructed image and the reference image.
The adversarial loss component comes from the traditional GAN approach, and is based on how well the discriminator can tell apart a generated image from the real thing.
In the evaluation, the best results were obtained using feature map from the 4th convolution (after activation) before the 5th maxpooling layer within the VGG19 network. This combination is denoted SRGAN-VGG54 in the figures.
We speculate that feature maps of these deeper layers focus purely on the content while leaving the adversarial loss focusing on texture details which are the main difference between the super-resolved images without the adversarial loss and photo-realistic images.
In the following figure, you can see the contributions of the various components of the architecture. The ground truth image is on the right. On the left-hand side, SRResNet is a deep residual network trained using MSE loss, but no discriminator component. SRGAN-MSE shows the GAN result when using MSE as the content-loss component. SRGAN-VGG22 shows the GAN result when using VGG loss at shallower layers. SRGAN-VGG54 is the best performing variation.

You can see how participants rated SRGAN against SRResNet and other SR solutions in a mean opinion score (MOS) test in figure 5 below.

Using extensive MOS testing, we have confirmed that SRGAN reconstructions for large upscaling factors (4x) are, by a considerable margin, more photo-realistic than reconstructions obtained with state-of-the-art reference methods.
Perceptually convincing reconstruction of text or structured scenes remains challenging and is part of future work.

4 thoughts on “Photo-realistic single image super-resolution using a generative adversarial network”
Comments are closed.