Image-to-image translation with conditional adversarial networks Isola et al., CVPR’17
It’s time we looked at some machine learning papers again! Over the next few days I’ve selected a few papers that demonstrate the exciting capabilities being developed around images. I find it simultaneously amazing to see what can be done, and troubling to think about a ‘post-reality’ society in which audio, images, and videos can all be cheaply synthesised to tell any story, with increasing realism. Will our brains really be able to hold the required degree of skepticism? It’s true that we have a saying “Don’t believe everything you hear,” but we also say “It must be true, I’ve seen it with my own eyes…”.
Anyway, back to the research! The common name for the system described in today’s paper is pix2pix. You can find the code and more details online at https://github.com/phillipi/pix2pix. The name ‘pix2pix’ comes from that fact that the network is trained to map from input pictures (images) to output pictures (images), where the output is some translation of the input. Lots of image problems can be formulated this way, and the figure below shows six examples:
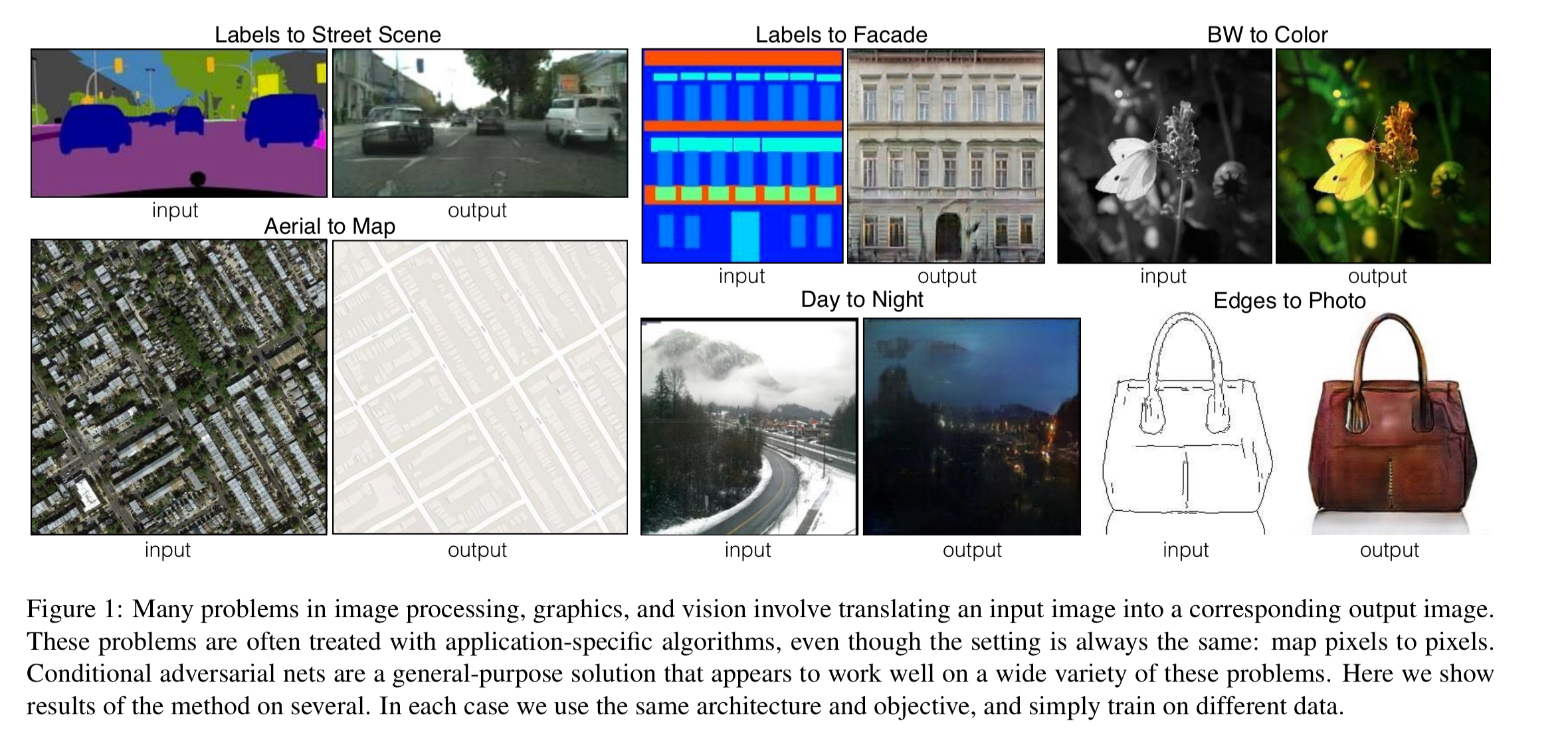
The really fascinating part about pix2pix is that it is a general-purpose image-to-image translation. Instead of designing custom networks for each of the tasks above, it’s the same model handling all of them – just trained on different datasets for each task. From the abstract:
We investigate conditional adversarial networks as a general-purpose solution to image-to-image translation problems. These networks not only learn the mapping from input image to output image, but also learn a loss function to train this mapping. This makes it possible to apply the same generic approach to problems that traditionally would require very different loss formulations… As a community, we no longer hand-engineer our mapping functions, and this work suggests we can achieve reasonable results without hand-engineering our loss functions either.
Pix2pix can produce effective results with way fewer training images, and much less training time, than I would have imagined. Given a training set of just 400 (facade, image) pairs, and less than two hours of training on a single GPU, pix2pix can do this:

High level approach: GANs and cGANs
Convolutional Neural Nets (CNNs) have become the go-to workhorse for a variety of image tasks, but coming up with loss functions that force the CNN to do what we really want – for example, creating sharp realistic images – is an open problem generally requiring expert knowledge. Generative Adversarial Networks (GANs) get around this issue by pitting one image generating network against another adversary network, called the discriminator. It’s the job of the generative network to produce images which the discriminator network cannot distinguish from the real thing.
GANs learn a loss that tries to classify if the output image is real or fake, while simultaneously training a generative model to minimize this loss.
Instead of hand-designing the loss function, we simply collect lots of examples of ‘the real thing’ and ask the network to generate images that can’t be distinguished from them.
This works well for creating realistic images that are representative of the target class (by mapping from a random noise vector), but for image-to-image translation tasks we don’t want just any realistic looking image, we want one that is the translation of an input image. Such a network is said to be conditioned on the input image, and the result is called a conditional GAN or cGAN. The generator network is given both an observed image and a random noise vector as input, and learns to create images that the discriminator cannot tell apart from genuine translations of the input. Thus we need to collect (image, translation) pairs for training. Here’s an example where the input is a map, and the output is an aerial photo of area shown in the map.
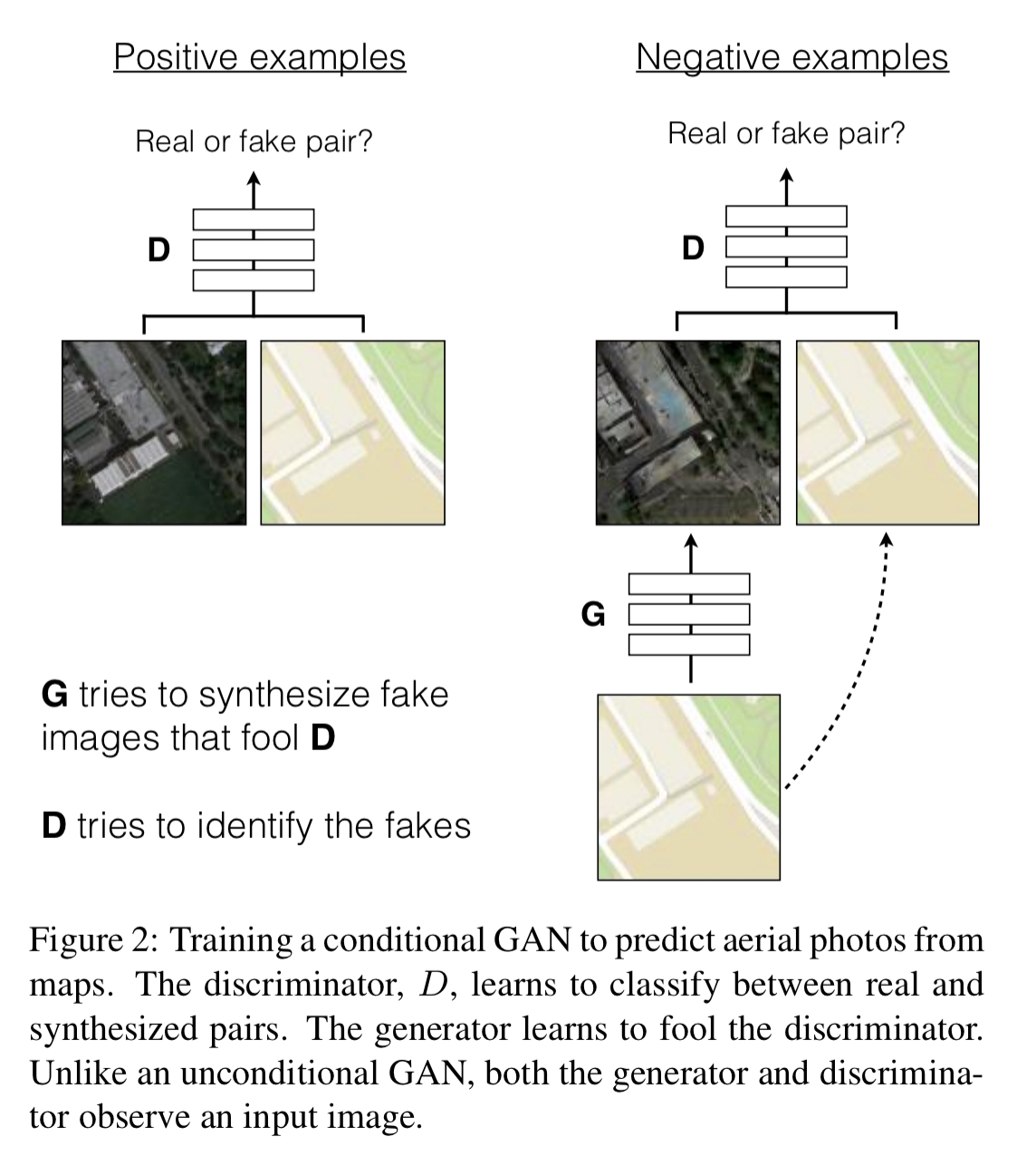
This example also illustrates why some element of randomisation is still needed in addition to the conditioning image: without it the network would always create the same output image for the same input, and we want to be able to create a variety of plausible outputs. However, experiments showed that when the randomness was provided as an input, the network just learned to ignore it. So instead noise is provided only in the form of dropout, applied at several layers during both training and test. Even then, the full available entropy is not fully exploited.
The GAN objective is also mixed with a more traditional loss, based on L1 distance. “The discriminator’s job remains unchanged, but the generator is tasked to not only fool the discriminator but also to be near the ground truth output in an (L1) sense.”
Network architecture highlights
The basic structure of the network is an encoder-decoder: the input passes through a series of layers which progressively downsample, until a bottleneck layer, after which the process is reversed.
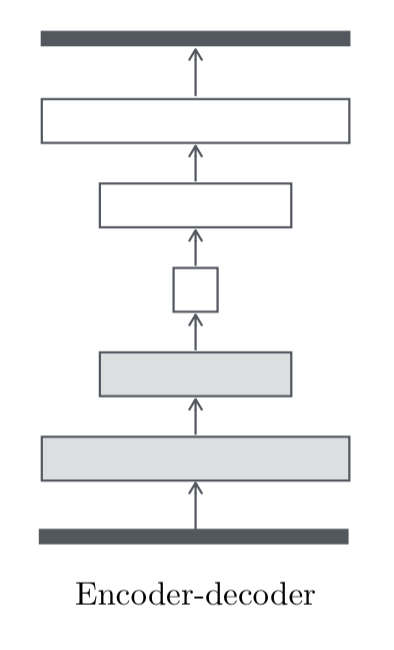
In many image-to-image translation problems there is a a lot of low level information shared between the input and the output, and we’d like to be able to take advantage of this more directly.
To give the generator a means to circumvent the bottleneck for information like this, we add skip connections, following the general shape of a “U-Net”.
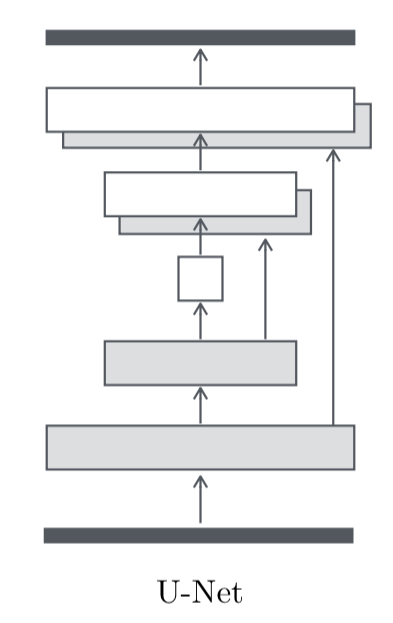
Skip connections are added between matching layer pairs on either side of the bottleneck. You can see the benefit of the skip connections by comparing the top and bottom rows in the following figure:

The L1 loss term accurately captures low-frequency structure, leaving the GAN discriminator to focus on capturing high-frequency structure.
In order to model high-frequencies, it is sufficient to restrict our attention to the structure in local image patches. Therefore, we design a discriminator architecture – which we term a PatchGAN – that only penalizes structure at the scale of patches. This discriminator tries to classify if each NxN patch in an image is real or fake. We run this discriminator convolutionally across the image, averaging all responses to provide the ultimate output of D.
N can be much smaller than the full size of the image and still produce high quality results.
The following figure shows the visual impact of varying patch sizes:

Sample results and evaluation
The method is tested on a variety of tasks and datasets:
- Semantic labels to photos, trained on the Cityscapes dataset.

- Architectural labels to photos, trained on the CMP facades dataset. (We saw this example earlier in the post).
-
Maps to aerial photos, trained on data scraped from Google Maps.

- Black and white to colour photos.

- Edges to photos

- Sketches to photos

- Day to night photo translation

The results in this paper suggest that conditional adversarial networks are a promising approach for many image-to-image translation tasks, especially those involving high structured graphical outputs.
