PrivacyGuide: Towards an implementation of the EU GDPR on Internet privacy policy evaluation Tesfay et al., IWSPA’18
(Note: the above link takes you to the ACM Digital Library, where the paper should be accessible when accessed from the blog site. If you’re reading this via the email subscription and don’t have ACM DL access, please follow the link via my blog.)
…if a user was to read the privacy policy of every service she visits on the Internet, she would on average need 244 hours annually which is slightly more than half of the average time a user would spend on the Internet by then.
Studies have shown that only 1% or less of total users click on privacy policies, and those that do rarely actually read them. The GDPR requires clear succinct explanations and explicit consent (i.e., no burying your secrets on page 37 of a 70 page document), but that’s not the situation on the ground right now, and it’s hard to see that changing overnight on May 25th.
So we know that privacy is an important matter, and that a solution involving reading lengthy terms of service to determine the privacy implications of using a particular app/service/site is untenable. What can we do (beyond legislating for shorter ToS’s)? We could try either:
- Crowdsourcing interpretations of privacy policies. For example, Terms of Service: Didn’t Read (ToS:DR) is a community based project to evaluate privacy policies by crowdsourcing, and provides a browser add-on. Unfortunately it lacks coverage (68 web sites covered since its launch in 2012, and only 11 of them given a final grade), and is nearly impossible to keep up to date since companies frequently update their policies.
- Automating the interpretation of privacy policies to highlight the key information a prospective user really needs to know. That’s what PrivacyGuide does. It turns lengthy terms of service documents into this:
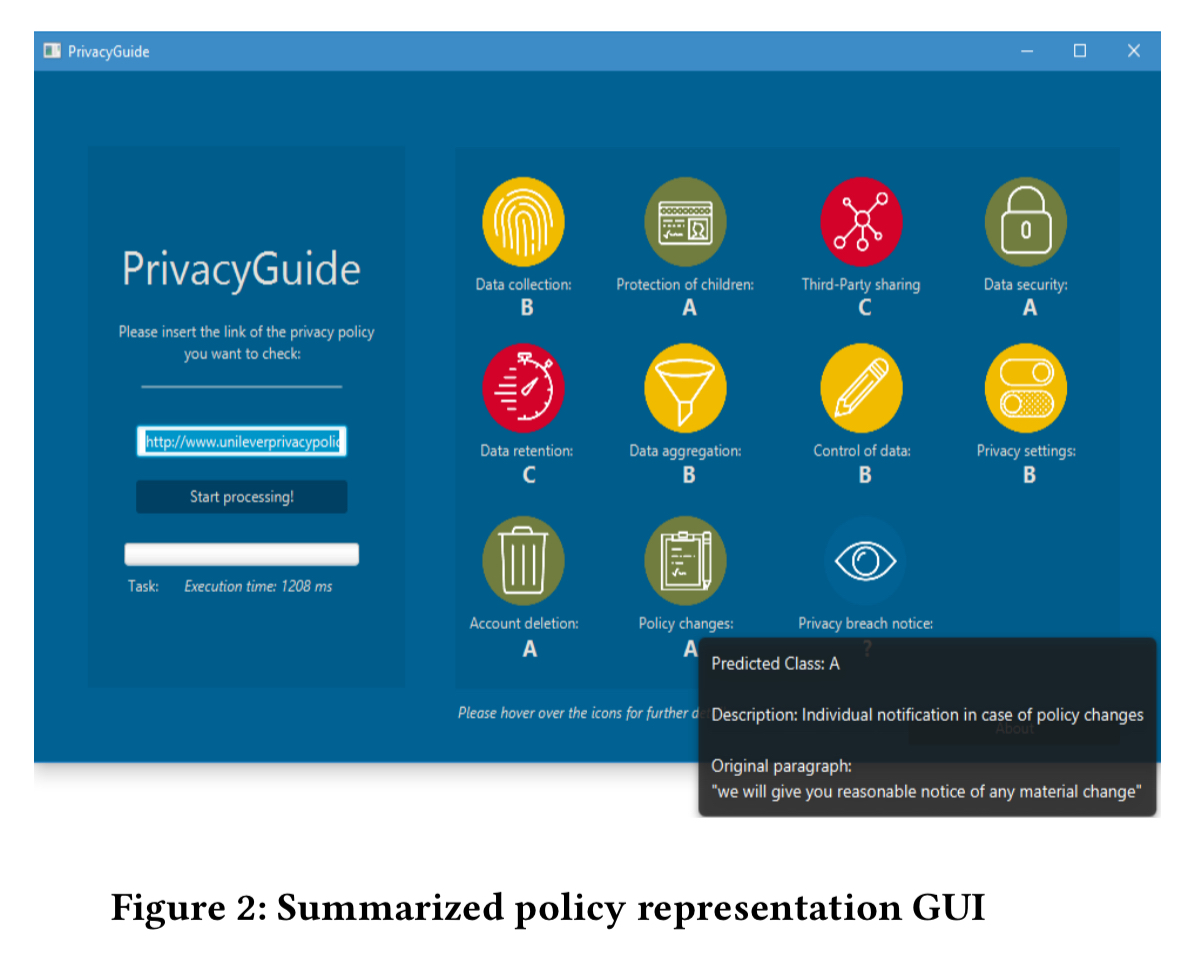
PrivacyGuide breaks down privacy policies into 11 standard categories, based on an analysis of the GDPR requirements. It presents a simple dashboard summary with green (low risk), orange (average risk) and red (high risk) indicators for each. You can drill down into the detail behind the icons to see a short description of the meaning and consequence of the risk class, and the closest original sentence or paragraph on which the assessment was performed. The idea is to present a consistent format across sites, similar to the way nutrition labels are standardised. This would be a big step forward. But even then, ‘The curious case of the pdf converter that liked Mozart’ study that we looked at last year showed that people still tend to just click-through. The dialogs developed in that study showing the privacy implications of permissions granted by a policy remains my favourite.
Understanding privacy policies
To start with, the authors conducted an extensive analysis of the GDPR with the support of legal experts. Comparing the privacy aspects of the GDPR with classification categories used in previous studies, resulted in the following set of 11 categories:

(Enlarge)
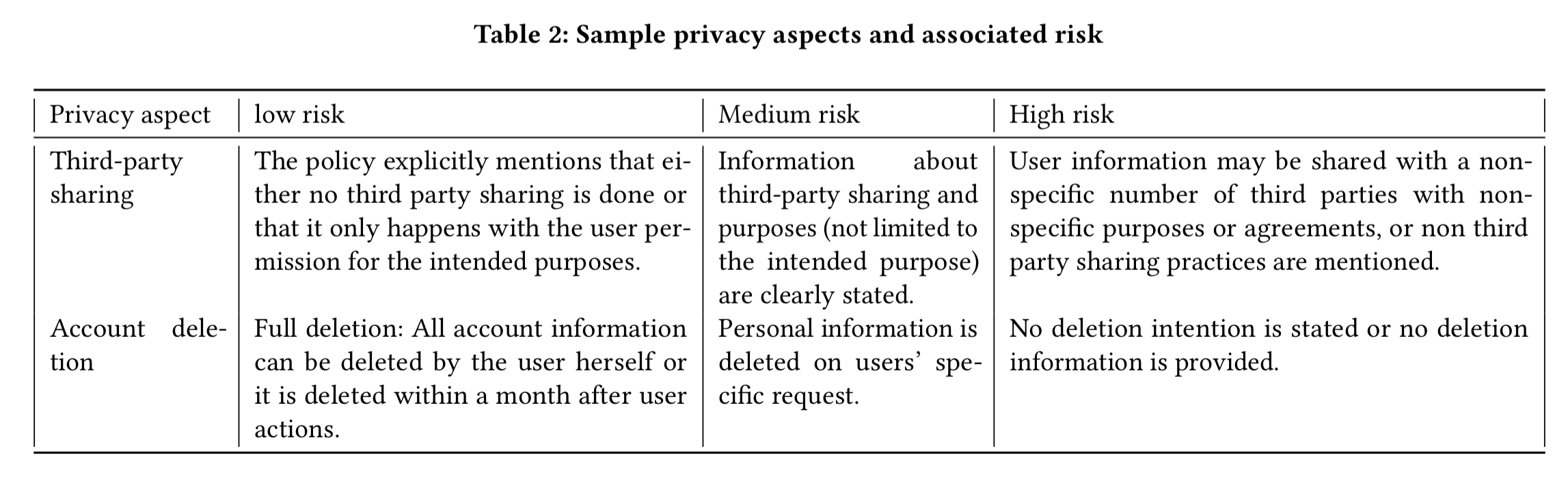
Within each category a group of privacy experts determined three risk levels. Here are examples for the third-party sharing and account deletion categories:
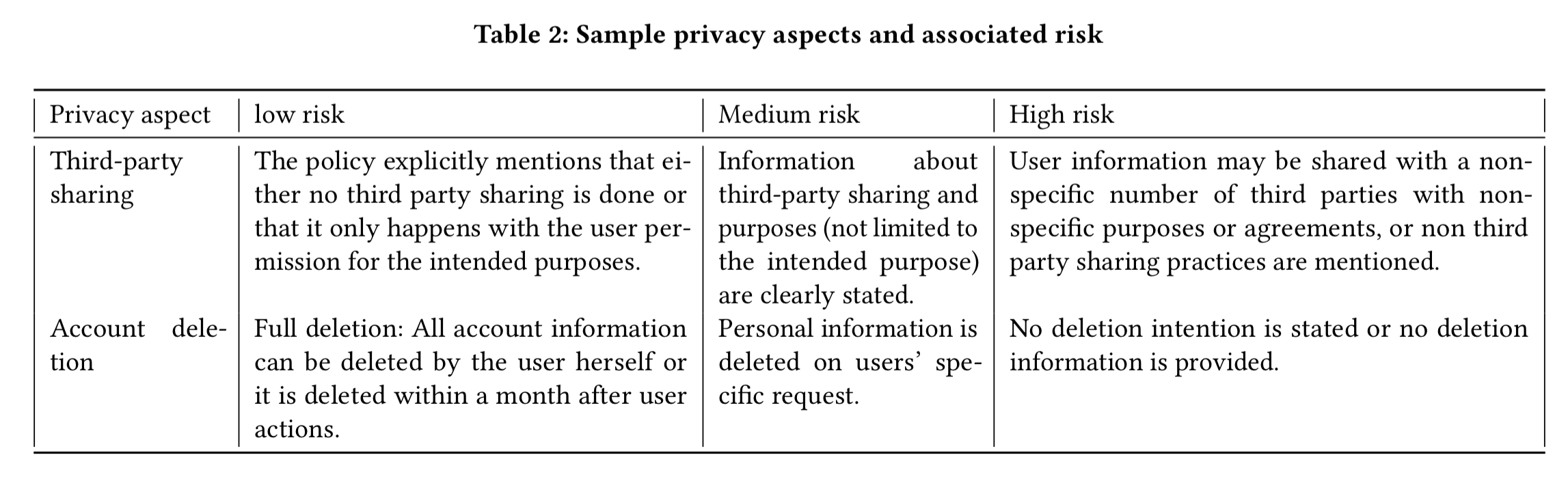
(Enlarge)
With this framework in hand, a privacy corpus was built using the privacy policies of the 45 most accessed websites in Europe according to the results provided by Alexa. (It’s a shame the authors don’t make this assessment available anywhere that I’m aware of…). 35 participants manually extracted on average 12,666 text passages from a single privacy policy, of which 433 ended up being assigned to a privacy category and classified with a risk level.
Classification
The next step is to train a multi-class classifier (11 privacy categories, and three risk levels per category) using this corpus. The team experimented with Naive Bayes, SVM, Decision Trees, and Random Forests: Naive Bayes turned out to work the best for this problem.
The PrivacyGuide workflow looks like this:
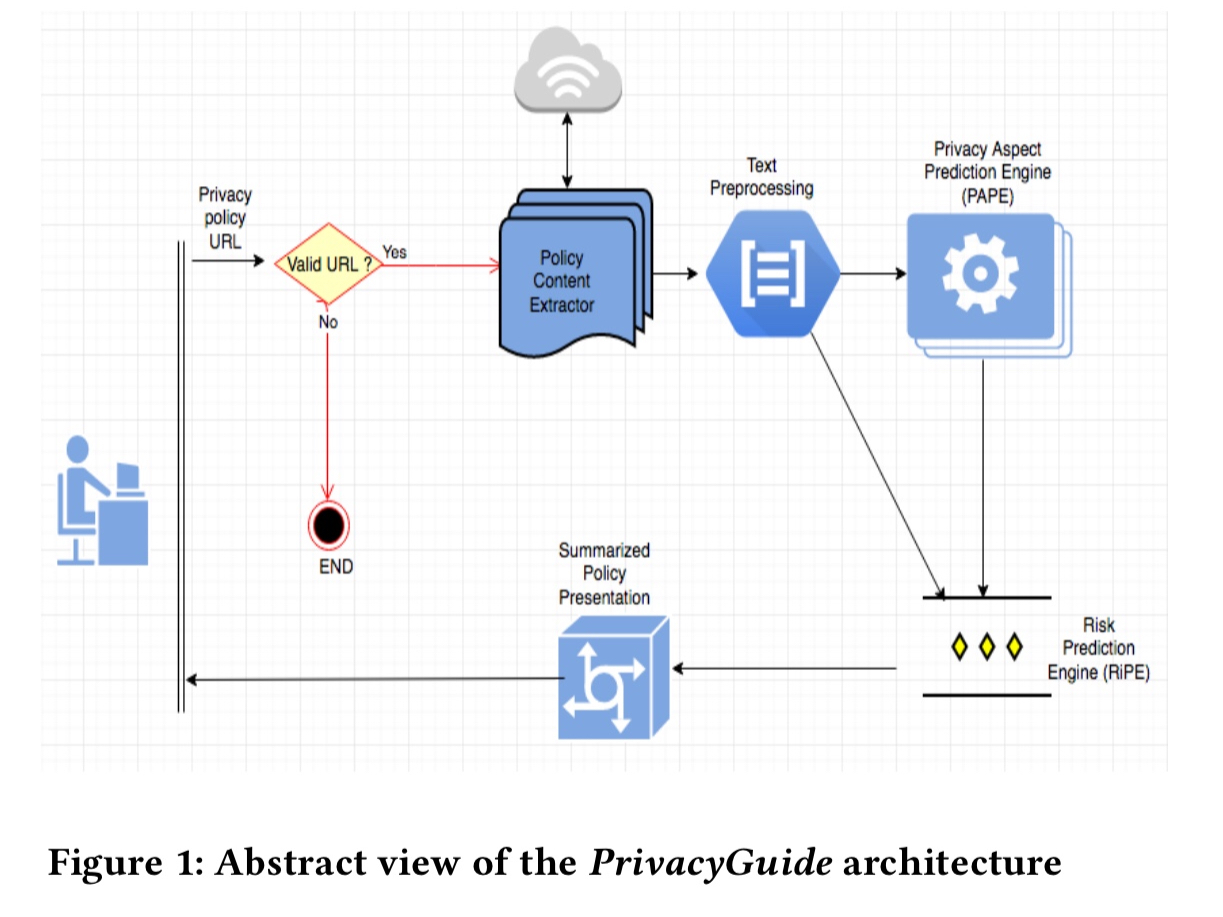
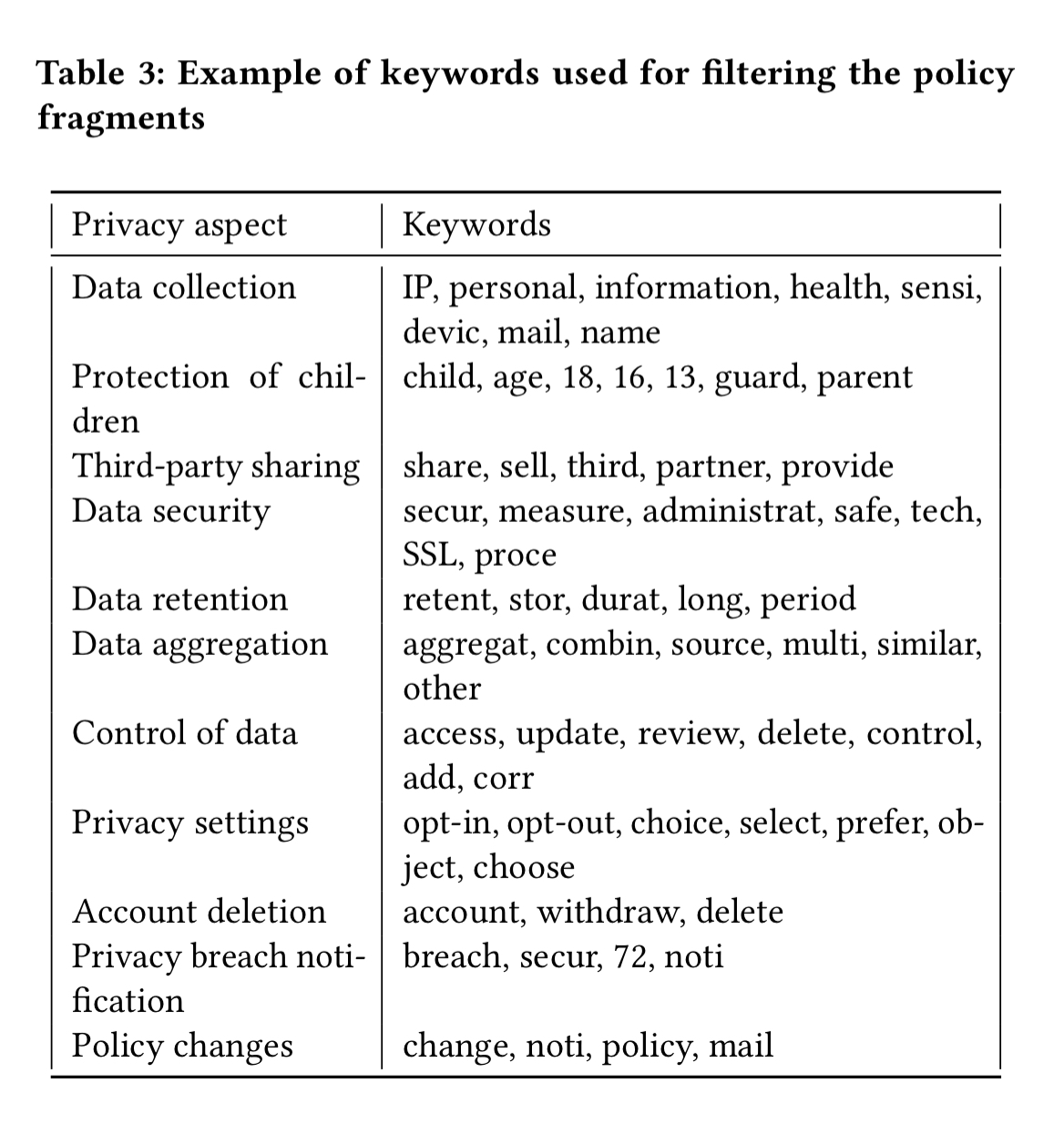
Content extraction is done using the Boilerpipe library. The resulting text is then split into individual sentences, and a set of keywords (obtained from the training data) used to identify informative sentences. Fragments not including any of these keywords are filtered out at this stage.
From the resulting set of sentences, stop word removal, tokenisation, and stemming are performed, and WEKA’s StringToWordVector filter is used to create sentence vectors. TF-IDF is also used to consider the most relevant words.
Using these features, classification is done in two steps.
- The Privacy Aspect Prediction Engine (PAPE) predicts a privacy category, and is trained using 10-fold cross-validation.
- Given a category, the Risk Prediction Engine (RiPE) predicts an associated risk class. In order to provide explanations to the user, the best representative sentence on which the risk classification is based is also captured.
Evaluation
The next 10 most accessed sites in Europe (according to Alexa) are then used for evaluation.

The table below shows the performance of the classifier on these sites.
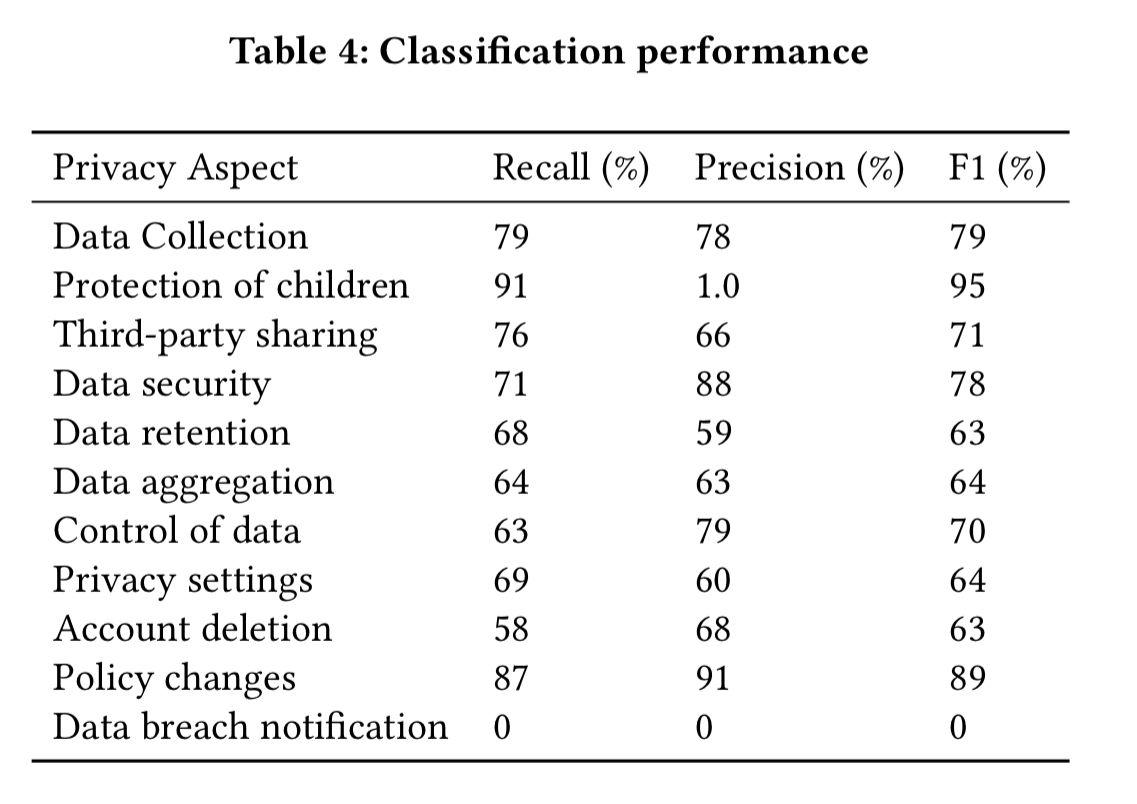
Not perfect, but considering you weren’t going to read the policy otherwise and PrivacyGuide can produce its results in less than 2 seconds, it’s pretty good! Note the incidental discovery that none of the sites specified data breach notification plans in their policies.

{kind=link}
{kind=link}
Interesting. Is the tool available? or am I just missing the right link …
The code is on GitHub here: https://github.com/InfiniteCoding/PrivacyGuide (with thanks to Ben Kehoe for the link).