Tracing fake news footprints: characterizing social media messages by how they propagate Wu & Liu, WSDM’18
This week we’ll be looking at some of the papers from WSDM’18. To kick things off I’ve chosen a paper tackling the problem of detecting fake news on social media. One of the challenges here is that fake news messages (the better ones anyway), are crafted to look just like real news. So classifying messages based on their content can be difficult. The big idea in ‘Tracking fake news footprints’ is that the way a message spreads through a network gives a strong indication of the kind of information it contains.
A key driving force behind the diffusion of information is its spreaders. People tend to spread information that caters to their interests and/or fits their system of belief. Hence, similar messages usually lead to similar traces of information diffusion: they are more likely to be spread from similar sources, by similar people, and in similar sequences. Since the diffusion information is pervasively available on social networks, in this work, we aim to investigate how the traces of information diffusion in terms of spreaders can be exploited to categorize a message.
In a demonstration of the power of this idea, the authors ignore the content of the message altogether in their current work, and still manage to classify fake news more accurately than previous state-of-the-art systems. Future work will look at adding content clues back into the mix to if the results can be improved even further.
TraceMiner consists of two main phases. Since information spreads between nodes in the network, we need a way to represent a node. Instead of 1-of-n (one hot) encoding, in the first phase a lower-dimensionality embedding is learned to represent a node. In other words, we seek to capture the essential characteristics of a node (based on friendship and community memberships). In the second phase the diffusion trace of a message is modelled as a sequence of its spreader nodes. A sequence classifier built using LSTM-RNNs is used to model the sequence and its final output is aggregated using softmax to produce a predicted class label.
The first step utilizes network structures to embed social media users into space of low dimensionality, which alleviates the data sparsity of utilizing social media users as features. The second step represents user sequences of information diffusion, which allows for the classification of propagation pathways.
Let’s take a closer look at each of these two steps, and then we’ll wrap up by seeing how well the method works compared to previous systems.
Learning an embedding for social media users
Social networks of interest for fake news spreading tend to be those with the largest reach – i.e., they have a lot of users. Hence there is comparatively little information about the majority of users in any given trace.
Just as most words appear infrequently, and a few words very frequently:
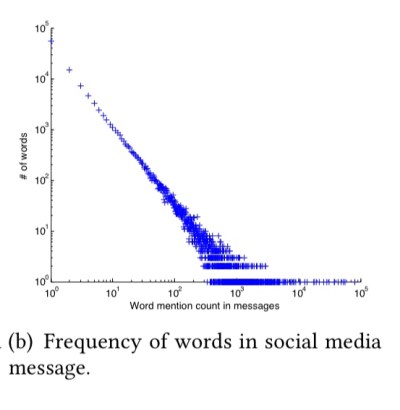
So most users appear infrequently in information diffusion traces, and a small number of users appear much more frequently:
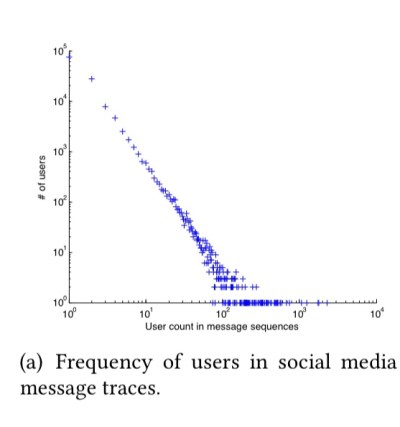
(Both of these plots are log-log).
[The user and word frequency plots] both follow a power-law distribution, which motivates us to embed users into low dimensional vectors, as how embedding vectors of words are used in natural language processing.
Two state of the art approaches for user embedding in social graphs are LINE and DeepWalk. LINE models first and second degree proximity, while DeepWalk captures node proximity using a random walk (nodes sampled together in one random walk preserve similarity in the latent space). These both capture the microscopic structure of networks. There is also larger mesoscopic structural information such as social dimensions and community membership we would like to capture (as is done for example by SocDim).
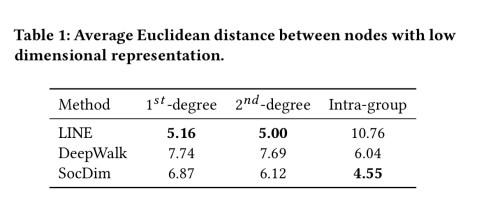
… the ideal embedding method should be able to capture both local proximity and community structures… we propose a principled framework that directly models both kinds of information.
The model combines an adjacency matrix and a two auxiliary community matrices, one capturing community membership and the other capturing representations of communities themselves as embeddings. Full details are in section 3.2 of the paper.
Diffusion traces and sequence modeling
The topology of information spreading is a tree rooted with the initial spreader (or perhaps a forest). Dealing directly with this tree structure leads to a state space explosion though: with n nodes (users), there can be 
The problem can be simplified by flattening the trees into a linear sequence of spreaders. For example, 



When the trees are flattened like this, some of the immediate causality is lost. For example, consider this tree and it’s flattened representation:
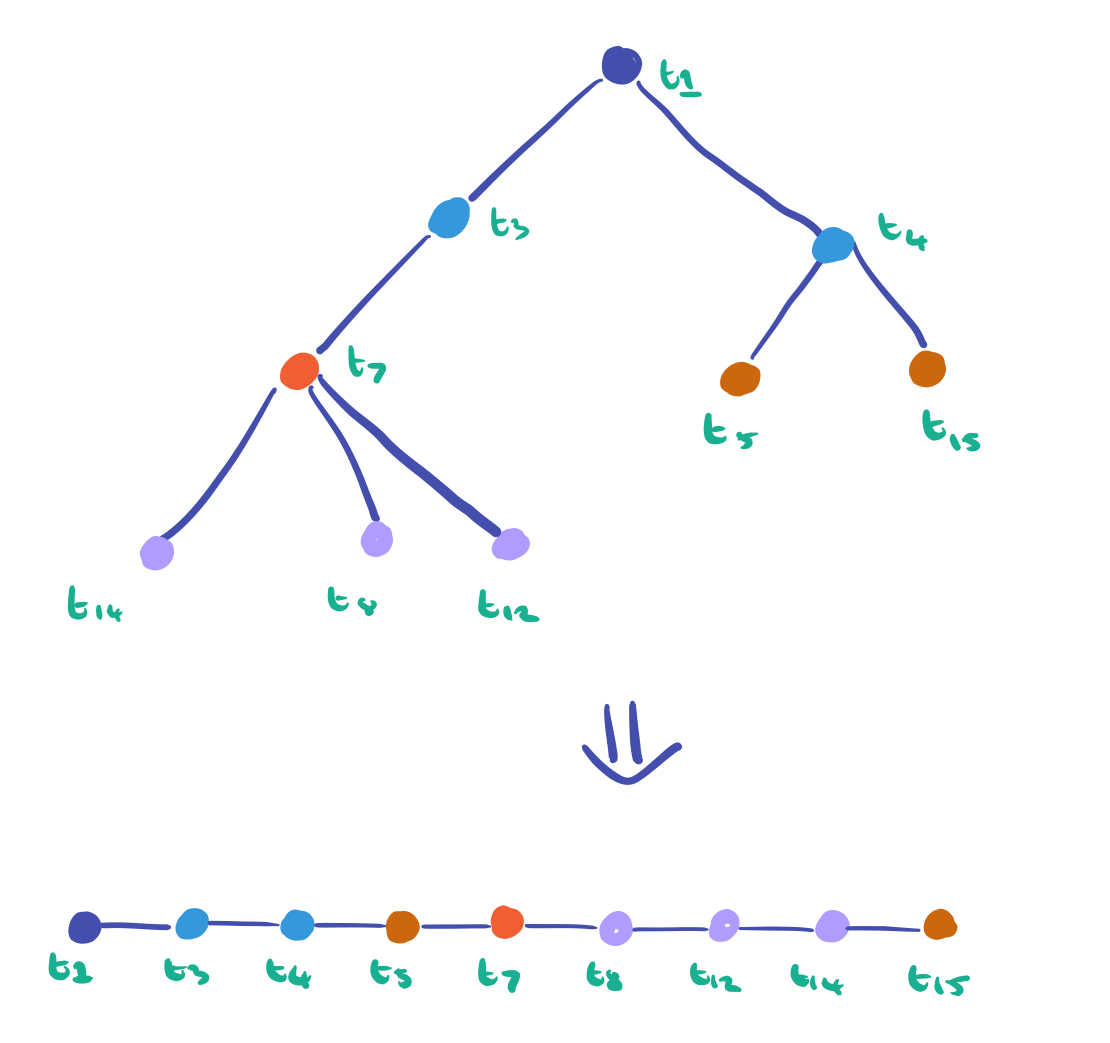
The problem here is that the direct dependencies we’ve lost are important. “For example, the information flow from a controller account to botnet followers is a key signal in detecting crowdturfing.” They should still be close to each other in the sequence though. That’s something an RNN can cope with…
We propose to use an RNN to sequentially accept each spreader of a message and recurrently project it into a latent space with the contextual information from previous spreaders in the sequence… In order to better encode the distant and separated dependencies, we further incorporate Long Short-Term Memory cells into the model, i.e., the LSTM-RNN.
Now it’s likely that the account which first originated a message is a better predictor of its class than the last accounts to spread it. So the diffusion trace is sent through the LSTM-RNN in reverse so that the originator is seen as close as possible to when the final prediction is made.
TraceMiner in action
TraceMiner is evaluated alongside an SVM classifier trained on message content, and XGBoost fed with pre-processed content produced by the Stanford CoreNLP toolkit. “XGBoost presents the best results among all the content-based algorithms we tested.” Variants of TraceMiner that use only microscopic network structure for node embeddings (i.e., DeepWalk and LINE) are also tested, to assess the impact of the community embeddings. Experiments are run on two Twitter datasets:
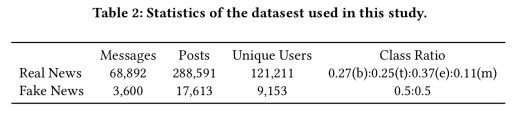
With the first dataset the challenge is to determine the news category, which is one of business; science and technology; entertainment; and medical. (On this task, you would expect the message-content based approaches to do well). The second dataset contains a 50:50 mix of genuine news and fake news, and the task is to tell them apart.
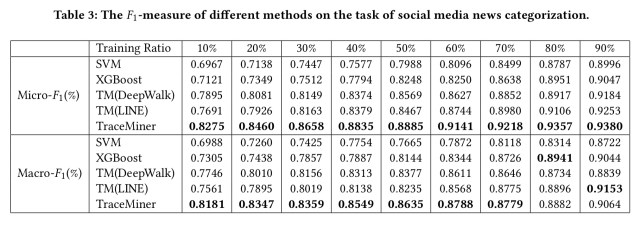
For the first news categorisation task, a variety of models are tested, using differing percentages of the training data. Two different accuracy measures are reported: Macro-F1 is just the average F1 score across the four categories, and Micro-F1 is the harmonic mean of the precision and recall scores. (The point of the Micro-F1 score is to be less sensitive to class imbalances).
On the Micro-F1 measure, TraceMiner does best across the board, and outperforms all other approaches on the Macro-F1 score until the amount of data used for training goes above the 80% threshold. XGBoost (which looks at message content) does best on this measure at the 80% mark.
With fake news, as we would hope, the advantage of the TraceMiner approach is even more distinct (based on the hypothesis that content is less distinguishing between real and fake news):
Unlike posts related to news where the content information is more self-explanatory, content of posts about fake news is less descriptive. Intentional spreaders of fake news may manipulate the content to make it look more similar to non-rumor information. Hence, TraceMiner can be useful for many emerging tasks in social media where adversarial attacks are present, such as detecting rumors and crowdturfing.
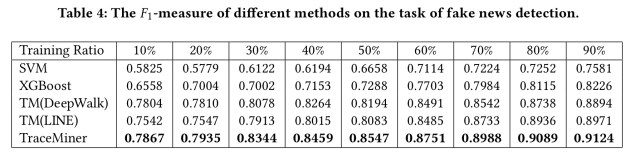
Now, in the case of fake news it is perhaps of some utility to be able to say after a piece of news has spread that “yes, that was fake news.” But by then it will have done it’s work and exposed its message to many people. So it’s notable in the table above that TraceMiner still performs well even with little training data.
… optimal performance with very little training information is of crucial significance for tasks which emphasise earliness. For example, detecting fake news at an early stage is way more meaningful that detecting it when 90% of its information is known.

Missing image on latest iPhone safari? Aftet the paragraph “When the trees are flattened like this, some of the immediate causality is lost. For example, consider this tree and it’s flattened representation:” there is no diagram for me just next text section.
Oops, yes. That sketch is missing from the email and the blog post. I’ll add it to the online blog post asap… Thanks, A.
Zipf’s law is everywhere…
The data was split into train and test not having time dimension into account, correct? How then one is able to make a very last conclusion?