Learning representations by back-propagating errors Rumelhart et al., Nature, 1986
It’s another selection from Martonosi’s 2015 Princeton course on “Great moments in computing” today: Rumelhart’s classic 1986 paper on back-propagation. (Geoff Hinton is also listed among the authors). You’ve almost certainly come across back-propagation before of course, but there’s still a lot of pleasure to be had from reading the paper and seeing again with fresh eyes the birth of the idea. Plus, we get the opportunity to take things nice and slow!
We want to build self-organising neural networks that can develop an internal structure appropriate for a particular task domain. Tasks are specified by giving the desired state vector of the output units for each state vector of the input units.
If the input units are directly connected to the output units it is relatively easy to find learning rules that iteratively adjust the relative strengths of the connections so as to progressively reduce the difference between the actual and desired output vectors. Learning becomes more difficult when we introduce hidden units whose actual or desired states are not specified by the task…
Back-propagation is a breakthrough (c. 1986!) algorithm that allows us to build and train neural networks with hidden layers. The learning procedure decides under what circumstances the hidden units should be active in order to achieve the desired input-output behaviour. “This amounts to deciding what these units should represent”. I.e., the hidden units are going to learn to represent some features of the input domain.
Consider networks with a layer on input units at the bottom, any number of intermediate (hidden) layers, and a layer of output units at the top. Connections within a layer, or from higher to lower layers are forbidden. Connections can skip intermediate layers though. (Skip connections would go on to be important components in the training of deep neural networks).
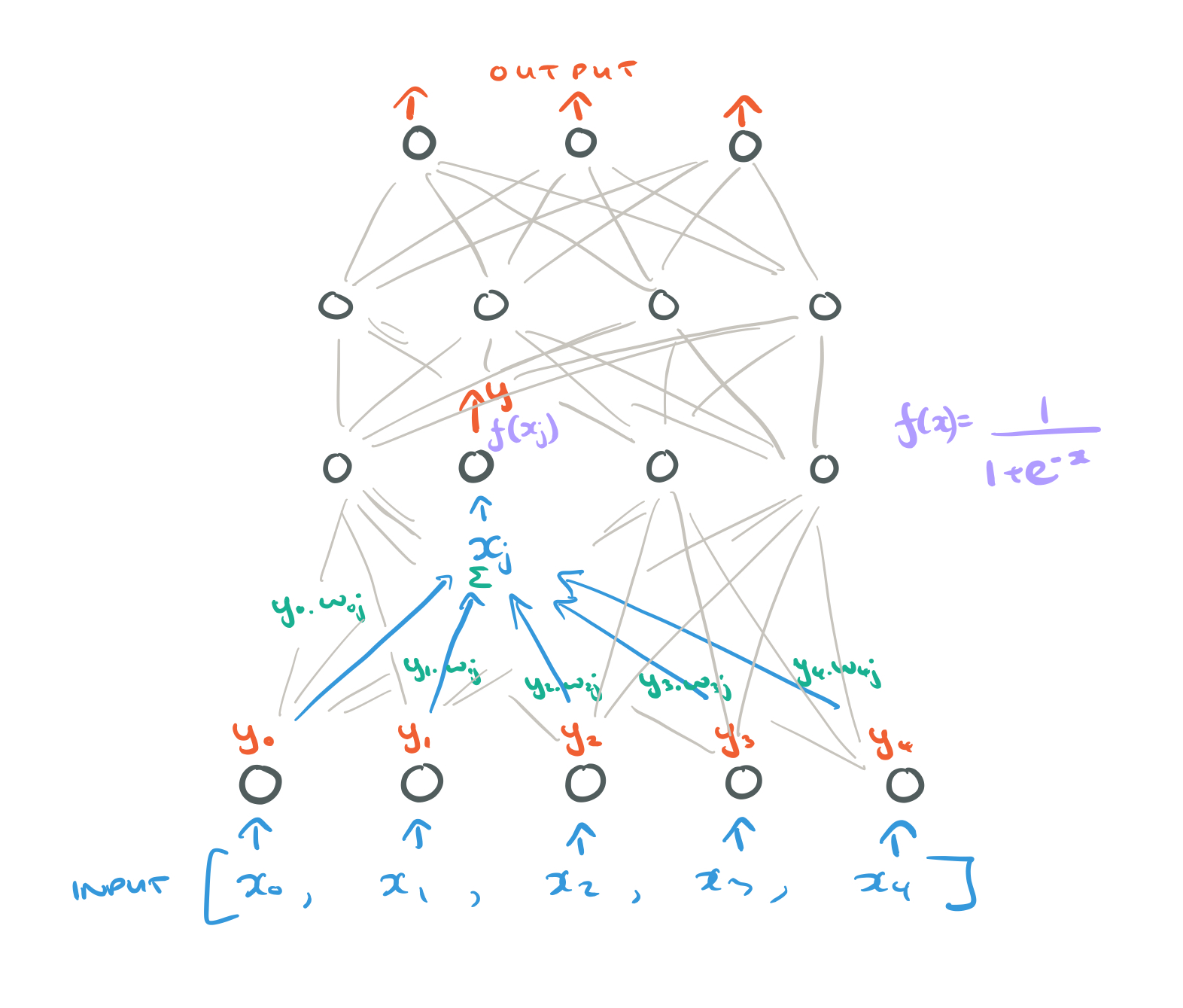
Feeding forward
Consider a unit j, with an input 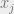
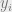

[EQN 1]

We’ll assume that each unit is given an extra input which always has the value of 1. The weight on this extra input is the ‘bias’. (The bias lets us control the value of b in 
We now know how to calculate the input to unit j, but what should j output? The output should be some function of the input, which we call the activation function. The chosen activation function in the paper is the sigmoid function:
[EQN 2]

This produces real-valued output, and is differentiable.
By repeating this procedure, starting with the input layer, we can feed-forward through the network layers and arrive at a set of outputs for the output layer.
Patching things up
We can now compare the calculated outputs to the desired output vector.
The aim is to find a set of weights that ensure that for each input vector the output vector produced by the network is the same as (or sufficiently close to) the desired output vector.
For a given input-output case, the error is given by:
[EQN 3]

Where 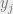

(Squaring things is handy when we sum, because it makes all differences positive so that positive and negative differences don’t cancel each other out).
We’d like to make the total error as small as possible (minimise it). To do that, we need to adjust the weights (the only parameters we have available to play with). But how should we adjust them to achieve our goal?
To minimize E by gradient descent it is necessary to compute the partial derivative of E with respect to each weight in the network.
We’d like to know how the error changes as we change the weights, 


So now we know how the error changes in relation to the outputs y. Recall that 
If we denote the sigmoid function by 


Getting closer! We know how the error changes with the output y, and we know how y changes with its input x. Now remember that 

Let’s put all those pieces together in a chain. If we know how the error changes with the output y, and how y changes with the input x, and how x changes with the weight w, then we can chain them together to figure out how the error changes with the the weights. Which is what we wanted to know in order to be able to adjust our weights using gradient descent. This is of course the chain rule from differentiation:

Almost there!
With

This method does not converge as rapidly as methods which make use of the second derivatives, but it is much simpler and can be easily implemented by local computations in parallel hardware. It can be significantly improved, without sacrificing the simplicity and locality, by using an acceleration method in which the current gradient is used to modify the velocity of the point point weight space instead of its position:

Where t is incremented by 1 for each sweep through the whole set of input-output cases, and 
Variants on the learning procedure have been discovered independently by David Parker (personal communication) and Yann Le Cun.

Amazing. Two weeks ago I decided to brush op on neural networks (Tensorflow spiked my interest) and spent a few days going through this identical process. As a Java developer I used the JShell to play with this and developed a very simple multilayer network class that implements backpropagation. If you’re in the same boat as me, Java, then it might be interesting: http://aqute.biz/2018/01/17/TensorFlow.html
The mixing in of gradients from previous timesteps is known as Broyden mixing scheme in self-consistent field calculations in condensed matter theory. This works in some cases but fails in others. The latter is the case when you may get into oscillatory regimes; in these cases the conjugate gradient method to minimise the error functional may the best bet.