Deep Neural Networks for YouTube Recommendations Covington et al, RecSys ’16
The lovely people at InfoQ have been very kind to The Morning Paper, producing beautiful looking “Quarterly Editions.” Today’s paper choice was first highlighted to me by InfoQ’s very own Charles Humble. In it, Google describe how they overhauled the YouTube recommendation system using deep learning. The description of the system is certainly of interest, and we’ll get to that in a moment. The thing that strikes me most about the paper though is how it represents a changing of the guard as we enter the deep learning era…
In conjugation with other product areas across Google, YouTube has undergone a fundamental paradigm shift towards using deep learning as a general purpose solution for nearly all learning problems… In this paper, we describe the system at a high level and focus on the dramatic performance improvements brought by deep learning.
The YouTube system is built on top of Google Brain, or as we now know it, TensorFlow. To give an idea of scale, the models learn approximately one billion parameters and are trained on hundreds of billions of examples. The basic problem is posed as “given this user’s YouTube activity history, which videos are they most likely to watch next?” The system is structured in two parts. First, a candidate generation model selects a small number (hundreds) of candidate videos from the overall corpus, and then a ranking model scores these candidates. The highest scoring videos are presented to the user as recommendations.
The two-stage approach to recommendation allows us to make recommendations from a very large corpus (millions) of videos while still being certain that the small number of videos appearing on the device are personalized and engaging for the user.
Dealing with this kind of scale is one of the three key challenges for YouTube. The other two are freshness and noise.
The freshness challenge reflects the facts that YouTube has a very dynamic corpus with hours of video uploaded every second, and users prefer newer content:
Recommending recently uploaded (“fresh”) content is extremely important for YouTube as a product. We consistently observe that users prefer fresh content, though not at the expense of relevance. In addition to the first-order effect of simply recommending new videos that users want to watch, there is a critical secondary phenomenon of bootstrapping and propagating viral content.
Since they’re trained on historical data, machine learning systems can exhibit an implicit bias towards the past. To correct for this, the age of a training example is included as a feature during training, and when making predictions it is set to zero. This makes a big difference as the following graph shows – the blue line shows the model predictions without the age feature, and the red line with it. The green line is the actual distribution.

The noisy data challenge is due to to the fact that “we rarely observe the ground truth of user satisfaction and instead model noisy implicit feedback signals.” Watch time is the ultimate arbiter:
Ranking by click-through rate often promotes deceptive videos that the user does not complete (“clickbait”) whereas watch time better captures engagement.
Candidate Generation
Candidate generation is inspired by continuous bag of words language models used in word vectors. A high dimensional embedding is learned for each video, and these are fed into a feed-forward neural network. The input vector combines a user’s watch history, search history, demographic and geographic features.
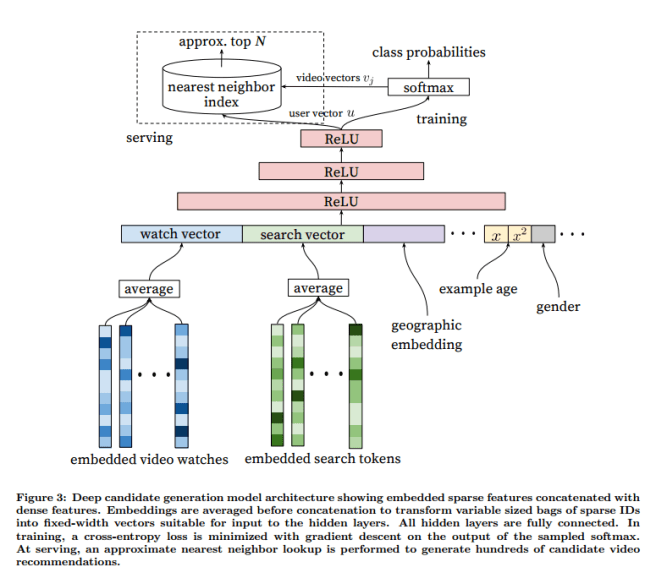
To compute the ‘watch vector’ subset of the input a sequence of video IDs is mapped to a sequence of embeddings (video embeddings are learned jointly with all other model parameters) and then these are simply averaged. A similar technique is used to average tokenized search queries via word embeddings.
The input layer is followed by several layers of fully connected Rectified Linear Units (ReLU).
The task of the deep neural network is to learn user embeddings u as a function of the user’s history and context that are useful for discriminating among videos with a softmax classifier.
At serving time, choosing the N most likely classes (i.e, videos) to pass to the ranking stage can be reduced to a nearest neighbour search.
Best performance was obtained by always predicting a user’s ‘next watch’ given their history so far (rather than holding out a random item in the history and predicting it from the other items). This better matches the natural consumption pattern of videos:
Episodic series are usually watched sequentially and users often discover artists in a genre beginning with the most broadly popular before focusing on smaller niches.
Ranking
The ranking process works with the much smaller (hundreds) of candidate videos produced by the first phase. It is therefore feasible to take advantage of many more features describing the video and the user’s relation to it.
We use a deep neural network with similar architecture as candidate generation to assign an independent score to each video impression using logistic regression. The list of videos is then sorted by score and returned to the user.

The ranking models use hundreds of features, and significant effort still needs to be expended engineering these:
Despite the promise of deep learning to alleviate the burden of engineering features by hand, the nature of our raw data does not easily lend itself to be input directly into feedforward neural networks. We still expend considerable engineering resources transforming user and video data into useful features. The main challenge is in representing a temporal sequence of user actions and how these actions relate to the video impression being scored.
The most important signals are those describing a users interaction with the item itself and other similar items. The overall goal of the ranking model is to predict expected watch time:
Our goal is to predict expected watch time given training examples that are either positive (the video impression was clicked) or negative (the impression was not clicked). Positive examples are annotated with the amount of time the user spent watching the video. To predict expected watch time we use the technique of weighted logistic regression, which was developed for this purpose.
For both candidate generation and ranking, increasing the width and depth of hidden layers improves results. Even though ranking is a classic machine learning problem, the deep learning approach still outperformed previous linear and tree-based methods for watch time prediction. For the full details, see the paper as linked at the top of this post.

Thank you for the nice explanation. But I has a question to ask. In the figure of Candidate Generation, how the video vector is trained? The user vector has a dimension of 256 and the user vector and video vector do inner product to get softmax probabilities. How to get the video vector through the neural net? Hope for your reply.